登录社区云,与社区用户共同成长
邀请您加入社区
本文介绍了在ArkTS中实现菜谱App搜索过滤功能的完整方案。首先分析了现有搜索框UI结构,包括TextInput的关键属性:placeholder提示文字、text双向绑定和onChange实时监听。针对当前只有UI无逻辑的问题,提出两种实现方案:方案一直接在build方法中过滤数据,适合小数据量场景;方案二通过@State缓存过滤结果,性能更优。文章还对比了两种方案的优缺点,并建议根据数据量选
本文从架构角度分析了一个菜谱应用的数据流动和代码组织。项目包含5个页面和1个服务层,核心数据层RecipeData采用三层结构:接口定义、静态数据、共享状态与操作函数。数据流动呈现三种模式:静态数据直读、查询函数+@State副本、共享状态+操作函数。操作函数分为查询类、状态修改类和状态操作类,实现了跨页面数据同步。整体架构通过合理的分层和模式选择,在保持简洁的同时满足了功能需求,为类似应用开发提
Per-Request 是基于协程本地存储(Goroutine Local Storage / Async Local Storage)的上下文传播模型。每一条外部消息(飞书、Websocket、HTTP、SFA2A子代理消息)进入网关,自动生成独立请求上下文,贯穿整条调用链路:插件回调、模型调用、工具执行、记忆读写、Langfuse 埋点。当前生效MD配置快照、权限快照链路标签、cjkRatio
LongTermMemory什么时候检索、如何使用召回历史记忆;哪些对话内容需要写入长期记忆;记忆摘要解读规则;上下文压缩后的摘要如何理解、不能忽略摘要信息;跨会话历史信息使用边界,禁止滥用无关记忆。
文章摘要 弹性伸缩是云原生系统的关键能力,能根据负载自动调整资源。本文介绍了三种伸缩类型:垂直伸缩(调整单机配置)、水平伸缩(增减实例数)和混合伸缩。重点讲解了Kubernetes中的HPA(水平Pod伸缩)、VPA(垂直Pod伸缩)和CA(集群伸缩)机制,以及Prometheus+KEDA的事件驱动伸缩方案。同时展示了应用层实现方式(如Spring Boot健康检查)和多种伸缩策略(阈值、预测、
摘要 聊天宝五端覆盖的架构设计核心在于数据与交互分离:统一云端数据层,差异化平台交互层。通过事件驱动的同步机制实现数据实时更新,采用RBAC模型确保五端权限一致。各平台利用原生特性实现最优交互方案(如Android悬浮窗、iOS输入法),而数据始终保持同步。架构评估应关注账号绑定、事件同步、精细权限、离线支持等关键点。鸿蒙版目前复用Android数据层,未来将补全交互能力。该设计实现了多端一致体验
校友网管理软件选择需关注组织模型扩展性、教育身份验证和跨端数据一致性。关键指标包括多级组织架构支持、权限管理、教务系统对接能力(如API、OCR识别)以及统一数据底座。"会会"系统采用微服务架构,具备信息治理、活动管理、积分建模等100+功能模块,适合高校数字化建设需求,满足审计、迁移和合规要求。该系统5年持续迭代,可作为可靠的技术基座选择。
同时,在策略制定阶段,我们要充分考虑到医药医疗行业的业务特点和需求,制定出合适的数据管理策略、数据安全策略以及数据治理策略,为数据架构的设计和实施提供有力的指导。比如,数据建模技术,它能够帮助我们对医药医疗行业的业务数据进行抽象和整合,形成统一的数据视图。通过合理的数据架构设计,企业可以打破数据孤岛,提升数据质量,更好地挖掘数据价值,从而推动企业的持续发展和创新。一个好的数据架构能够确保数据的准确
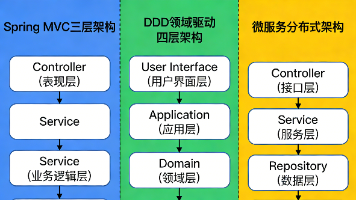
本文系统解析Java企业级分层架构(Controller/Service/Manager/Repository/DAO/Mapper),阐明各层职责边界、设计原则与典型误区,强调单一职责、依赖倒置、关注点分离等核心思想,助力构建高内聚、低耦合、易维护的可扩展系统。
分词器概述(认识分词、为什么需要分词、分词发生的阶段)、分词器的组成(字符过滤器、切词器、词项过滤器)、Ngram 自定义分词实战
API 网关 (Gateway)功能:作为整个系统的入口,负责请求的路由、负载均衡、认证授权、限流熔断、日志记录等。技术选型注册中心 (Service Registry)功能:负责服务的注册与发现,让各个微服务能够动态感知其他服务的存在。技术选型任务调度服务 (Scheduler Service)功能接收用户提交的采集任务(如指定商品分类、采集频率、采集字段等)。将大任务拆分成多个小任务(例如,按
在分布式存储环境中,存储资源通常由多个用户、项目和业务共享使用。如果缺乏有效的约束机制,单一主体的异常写入或误操作,可能迅速消耗大量空间或 inode,进而影响系统稳定性与成本控制。配额管理正是为共享环境建立可预测资源边界的重要手段。但在分布式系统中,配额管理并不只是“设置上限”这么简单。系统需要在多客户端并发写入、元数据异步更新和整体吞吐之间取得平衡;同时,配额规则也需要落实到不同层级的管控对象
摘抄自极客学院的《周志明的软件架构课》
通过明确愿景和目标、评估现状和需求、制定数字化战略框架、规划数字化应用和实施、加强组织和文化保障以及监控和评估数字化转型效果等步骤,企业可以制定出有效的数字化转型战略规划,并推动企业实现数字化转型的目标和愿景。根据愿景、目标和现状评估结果,确定数字化转型的战略方向,包括数字化技术的应用领域、组织架构的调整、流程的优化等方面。根据数字化转型的需要,调整企业的组织架构和人员配置,确保数字化转型战略的顺
软件架构作为系统设计的骨架,决定了应用的可扩展性、可靠性和维护成本。从大型机时代的集中式架构到云原生时代的分布式系统,架构模式的演进始终围绕 "如何平衡复杂性与效率" 这一核心命题。本文聚焦和三大主流范式,通过技术原理剖析、企业级案例对比和量化性能分析,揭示每种架构的适用场景与演进路径。根据 IEEE 1471 标准定义,架构是 "系统的基本组织,体现在组件、组件间关系、环境交互及设计原则中"。。
Leaf-Segment(号段模式):│ (主) │ ←─→ │ (从) ││ │▼ ▼│ 服务A │ │ 服务B ││ (获取 │ │ (获取 ││ 号段) │ │ 号段) │- 双Buffer预加载:当前号段用完前已预加载下一个- 高可用:多个Leaf Server组成集群Leaf-Snowflake(雪花模式):- 通过ZooKeeper自动注册workerId- 内置时钟回拨解决方案方案选
混合部署架构解决方案:本地与云端的优势互补 2026年,企业普遍采用"本地+云端"的混合部署模式,极智词元通过数百家企业的实践经验,总结出一套成熟的混合部署架构方案。该方案通过智能路由层动态分配任务:简单问题和敏感数据由本地AI BOX处理(响应快、成本低、数据安全),复杂问题则交由云端处理(模型能力强、可扩展性高)。架构包含用户交互层、智能路由层、AI BOX本地层和云端层,支持多端接入、负载均
2026年后端架构迎来"文艺复兴":随着AI工具和硬件算力的提升,过度拆分的微服务弊端显现,业界转向"分布式单体"新范式。该架构结合Wasm模块化隔离与Rust内存安全,在单体部署中实现逻辑解耦,显著降低网络延迟和运维成本。开发者需转型为"整合专家",掌握编译原理、性能调优和分布式内存计算。这场变革并非简单回归,而是AI时代对系统效率的重
入门:网络故障模型 → CAP/BASE → Raft 算法中层:微服务通信、注册发现、熔断限流核心难点:分库分表、分布式事务、分布式锁异步解耦:消息队列全套机制高阶:多活架构、NewSQL、大数据分布式计算实战:ShardingSphere、Seata、Nacos、Sentinel、RocketMQ、Flink
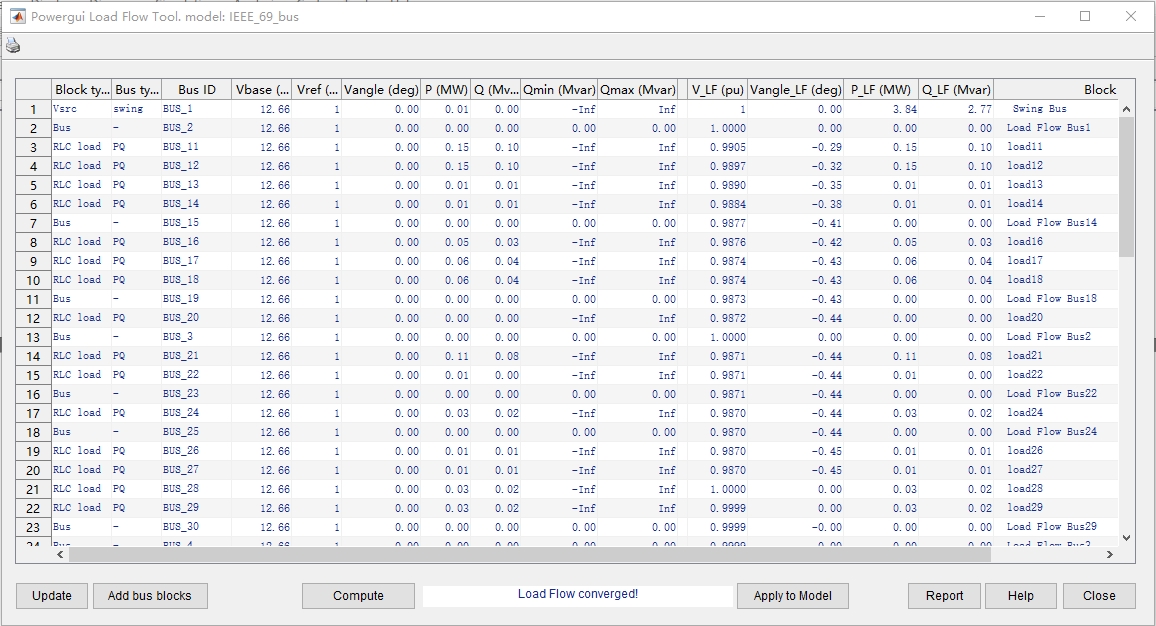
对了,记得把仿真结果导出到Workspace,用fft函数做频谱分析可比Simulink自带的示波器好用多了。这时候需要调出各节点电压分布曲线,能看到电压曲线从原来的"下垂型"变成了"波浪型",这说明分布式电源确实改变了系统的功率流向。有意思的是断开故障线路后,隔壁支路的电流反而会下降,这其实是网络拓扑重构带来的潮流转移现象。2.拓展功能: 可在该IEEE69节系统仿真模型上进行故障分析(短路,断
(包括:VM,JAVA集合,JAVA多线程并发,JAVA基础,Spring原理,微服务,Netty与RPC,网络,日志,Zookeeper,Kafka,RabbitMQ,Hbase,MongoDB,Cassandra,设计模式,负载均衡,数据库,一致性哈希,JAVA算法,数据结构,加密算法,分布式缓存,Hadoop,Spark,Storm,YARN,机器学习,云计算)
有效的企业架构对企业的生存和成功具有决定性的作用,是企业通过IT获得竞争优势的不可缺少的手段。企业数字化转型是指将传统企业的经营模式、业务流程、员工工作方式、客户服务等重要方面进行全面的数字化升级和转变,以应对日益激烈的市场竞争和顾客需求。数字化转型的本质是利用数字技术,使企业的业务、运营和管理更加高效、准确和智能,从而提升企业的竞争力和市场份额。企业数字化转型、企业架构、数字化转型蓝图、数字化顶
随着工业4.0战略的全球推广和智能制造的快速发展,工业物联网(Industrial Internet of Things, IIoT)逐渐成为现代工业领域不可或缺的一部分。IIoT通过先进的传感器技术、网络通信、大数据分析和人工智能手段,实现设备的智能化、生产过程的自动化以及管理和决策的优化。这些技术不仅提高了生产效率和安全性,还推动了工业生产方式的根本变革。
现代化的Cron-Job分布式任务调度平台,支持Go语言执行器SDK
核心方案就是将运行时耗时、计算量大的功能交给新开的node进程去执行处理。
但是随之而来的数据质量控制、共享、保密等问题日益突出,中国石油基于梦想云打造了中国石油统一的数据湖,也尝试应用OSDU的数据体系在油气田企业进行落地应用,但是面临的是“水土不服”的问题,数据的利用率并没有得到有效提升,究其原因,基于IT架构的数据治理并不能满足业务人员的真正需要,数据价值挖掘和有效应用的前提是构建公司内部统一的数据标准。在近期的一份中石化的调研报告中显示,我们唯一高于中石化的指标是
可观测性
你进入商场 → 服装店买衣服 → 餐厅吃饭 → 电影院看电影 → 离开商场↓ ↓ ↓ ↓ ↓会员卡号:8888 刷卡消费8888 刷卡消费8888 刷卡消费8888 刷卡消费8888商场通过你的会员卡号,可以知道你这一整趟行程的所有消费记录。正常时间流逝:时间回拨(运维手动修改系统时间):12:00:05 → 12:00:03 ← 时间倒退了2秒!如果不处理会怎样?新生成的ID会比之前的小破坏了递
本文档主要介绍了企业数字化转型中的财务数据中台建设,包括数字化转型的经历、财务数据中台架构与蓝图、数字化转型中的财务数据中台项目与需求、数字化转型中的财务数据中台建设难点与建议等内容。1. 数字化转型的经历本文档中提到了企业数字化转型的历程,从传统的业务模式到数字化的业务模式的转变,这是数字化转型的基础。总的来说,本文档介绍了企业数字化转型中的财务数据中台建设,包括数字化转型的经历、财务数据中台架
Prometheus是一个开源的监控和报警工具,专门用于捕获和存储时序数据。它通过抓取中暴露的指标数据来工作,并提供了强大的查询语言(PromQL)用于数据分析。Grafana是一个开源的分析和可视化平台,能够与 Prometheus 结合,展示数据并进行实时监控。分布式链路追踪是指在分布式系统中,跟踪一个请求从入口到达多个服务的全过程。通过链路追踪,可以清晰地看到各个服务之间的调用关系、请求的延
TVM 的 C++ 产物被拆成多个共享库,职责清晰、可按需部署。本文按和说明各库的功能与作用。
时间戳单位为10 微秒,统一从格林威治时间 2015年1月1日开始计算。如果设备使用常规Unix时间(从1970年1月1日算起),可以加上固定偏移值1420070400秒完成换算。受设备时钟、GPS信号等影响,报文里的时间戳不一定和标准时间完全一致,协议对此不作强制要求,只要求先后顺序正常。规定:在同一组(系统ID, 组件ID, 链路ID)的通信链路中,后一条报文的时间戳必须比前一条大。如果报文发
架构
——架构
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 HarmonyOS开发者社区
HarmonyOS开发者社区



 智能体开发者社区
智能体开发者社区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 人工智能6S服务平台
人工智能6S服务平台


 EazyDevelop社区
EazyDevelop社区


 深开鸿 技术专区
深开鸿 技术专区





























 AMD开发者中国社区
AMD开发者中国社区

