- @m0_59235945
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
我们用 AI Agent 驱动前后端全流程开发——从需求分析到自动化测试,整个 harness 工作流由 1 个 TL + 6 个子 Agent 组成。跑起来之后第一个问题就是:钱烧得很快,但完全不知道烧在哪。我们先用 AgentLens 把成本拆开看,发现系统提示词、工具返回信息、历史消息是大头。围绕"让 AI 只看到当前需要的上下文、减少无关的上下文、减少重复的上下文"这三个原则,我们逐一改造
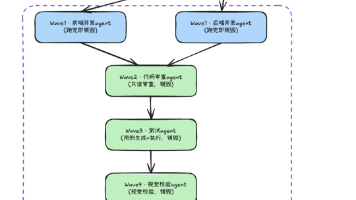
我们用 AI Agent 驱动前后端全流程开发——从需求分析到自动化测试,整个 harness 工作流由 1 个 TL + 6 个子 Agent 组成。跑起来之后第一个问题就是:钱烧得很快,但完全不知道烧在哪。我们先用 AgentLens 把成本拆开看,发现系统提示词、工具返回信息、历史消息是大头。围绕"让 AI 只看到当前需要的上下文、减少无关的上下文、减少重复的上下文"这三个原则,我们逐一改造
2024 年以前,"AI Agent"这个词听起来很酷,但实际落地形态通常是:```code-snippet__js用户输入 → Prompt Engineering → LLM → 输出
2024 年以前,"AI Agent"这个词听起来很酷,但实际落地形态通常是:```code-snippet__js用户输入 → Prompt Engineering → LLM → 输出
从“会调用工具”的 AI,到“了解用户、掌握知识”的智能助手上一篇文章我们介绍了 AI Agent 的核心能力:
从“会调用工具”的 AI,到“了解用户、掌握知识”的智能助手上一篇文章我们介绍了 AI Agent 的核心能力:
如果你这两年学 AI,一定绕不开一个词:Transformer。ChatGPT、Claude、Gemini、BERT、T5、机器翻译、代码助手、文档摘要、图文理解,背后都能看到 Transformer 的影子。

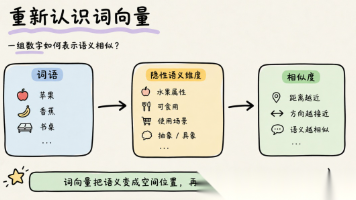
前面讲线性代数时,我们知道了:向量就是一组有顺序的数字。但到了自然语言处理里,问题会变得有点奇怪:
很多候选人一聊 RAG,回答就会迅速收缩成几句流程口号:切 chunk、做 embedding、存向量库、召回 Top-K、把上下文塞给大模型生成答案。这些步骤本身没有错,但如果面试官继续追问“为什么大模型已经很强了还需要 RAG”“R 和 G 分别在解决什么问题”“为什么检索看起来命中了,回答还是会错”“RAG 和 SFT 该怎么选”“ChatPDF 这种产品到底落在哪些技术点上”,很多回答就会

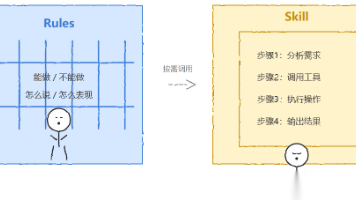
Skill和Rules看似都是"给AI下指令",但本质上解决的是完全不同层次的问题。一个管的是"AI始终要保持的状态",另一个管的是"AI在特定场景下的专业能力"。混在一起,两头都做不好。