
FastAPI+LangGraph入门:从零开始打造能使用工具的AI Agent(值得收藏)
本文详细介绍了如何使用FastAPI和LangGraph从零构建一个能使用工具的AI Agent。通过创建计算器、时间获取和掷骰子等工具,结合LangGraph的create_react_agent实现Agent的思考与行动能力,并利用FastAPI的lifespan模式高效管理资源,最终实现了支持多轮对话记忆的流式和非流式API接口。本教程适合初学者,为开发复杂AI应用打下基础。
本文详细介绍了如何使用FastAPI和LangGraph从零构建一个能使用工具的AI Agent。通过创建计算器、时间获取和掷骰子等工具,结合LangGraph的create_react_agent实现Agent的思考与行动能力,并利用FastAPI的lifespan模式高效管理资源,最终实现了支持多轮对话记忆的流式和非流式API接口。本教程适合初学者,为开发复杂AI应用打下基础。
FastAPI + LangGraph 入门:从零构建一个会使用工具的 AI Agent
哈喽,大家好!你是否曾好奇,那些强大的 AI 助手是如何做到不仅能聊天,还能帮你查询信息、执行计算的?今天,我们就来揭开这层神秘的面纱,亲手构建一个属于自己的、简易版的 AI Agent。
之前推荐的开源项目——agent-service-toolkit。它是一个用于运行 AI Agent 服务的全功能工具箱,集成了基于 LangGraph 的智能体、FastAPI 后端服务、标准客户端以及一个 Streamlit 聊天界面。它功能强大,但对于初学者来说,体量可能有些庞大。
因此,今天我们将采用与它相似的技术栈,手把手地构建一个“迷你版”的 AI Agent 服务。这个小项目将带你领略 LangGraph 的魅力,并学会如何将它与 FastAPI 完美结合,为你的 AI Agent 插上“工具”的翅膀。
最终,我们的 Agent 将能够像这样与你互动:
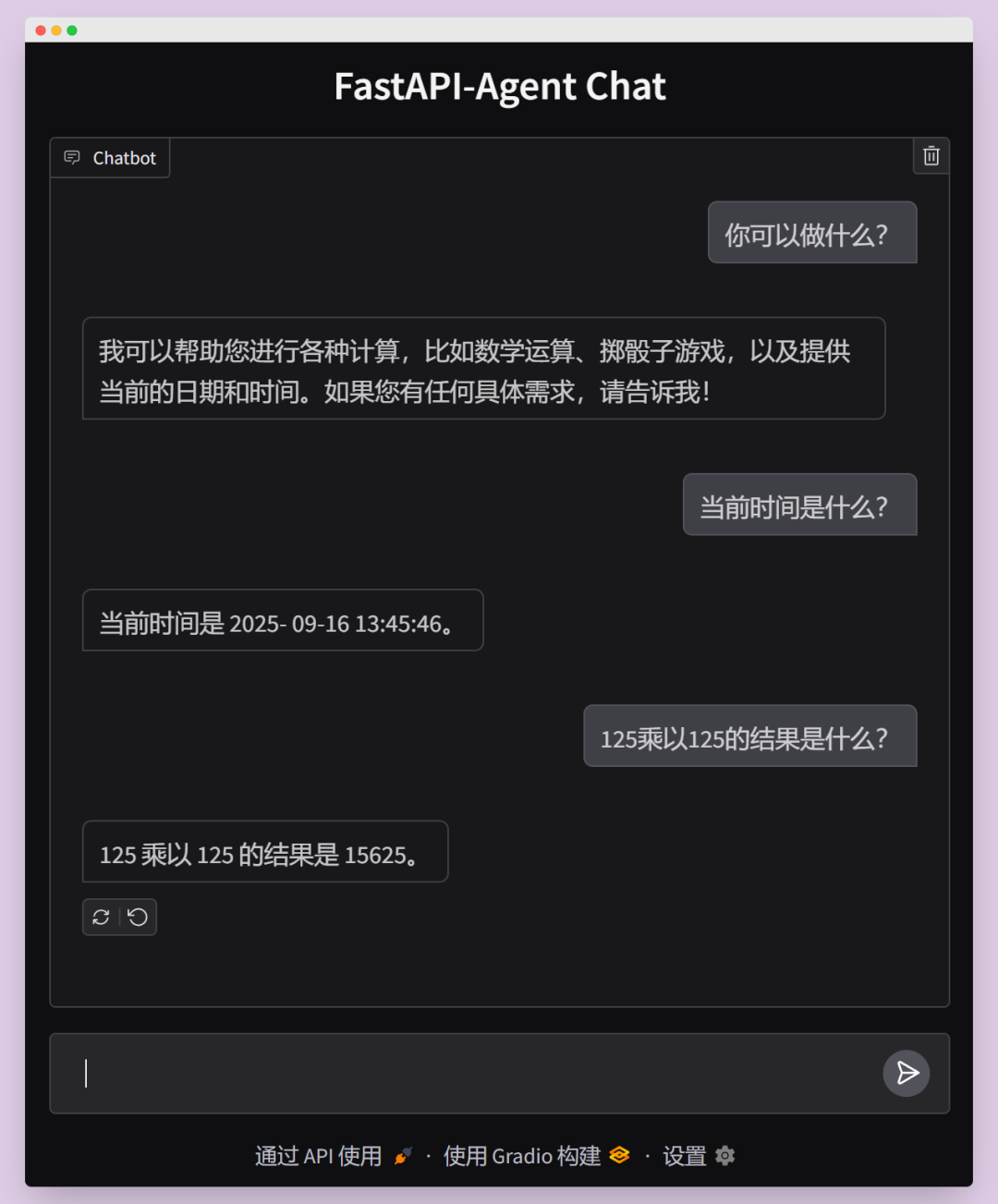
准备好了吗?让我们一步一步开始构建吧!
项目结构一览
一个清晰的项目结构是良好开端。我们的项目将组织如下:
agent-demo/
├── app/
│ ├── agents/
│ │ └── basic_agent.py # LangGraph Agent 的组装逻辑
│ ├── api/
│ │ └── query_routes.py # FastAPI 路由层
│ ├── core/
│ │ ├── config.py # 应用配置
│ │ ├── deps.py # 依赖注入
│ │ └── llm_loader.py # 大语言模型加载器
│ ├── schemas/
│ │ └── chat_schema.py # Pydantic 数据模型
│ ├── services/
│ │ └── agent_service.py # Agent 调用服务
│ ├── tools/
│ │ └── demo_tools.py # Agent 可用的工具
│ ├── lifespan.py # 应用生命周期管理
│ └── main.py # 应用主入口
├── .env # 环境变量
└── pyproject.toml # 项目与依赖管理
第一步:安装依赖
首先,让我们来安装所有需要的 Python 库。我们将使用 uv 这个现代化的包管理工具,当然你也可以使用 pip。
uv add fastapi fastapi-cli uvicorn loguru pydantic-settings langchain-core langchain-ollama langgraph ollama gradio
第二步:为 Agent 打造“工具箱”
一个 Agent 的强大之处在于它能够使用工具。让我们先来定义几个简单的工具函数。
app/tools/demo_tools.py:
import random
from datetime import datetime
from langchain_core.tools import tool, ToolException
# --- 1. 定义工具函数 ---
@tool
defcalculator(expression: str) -> str:
"""一个安全的计算器函数。当需要进行数学计算时使用。"""
try:
# 安全性检查:只允许特定的字符
allowed_chars = "0123456789+-*/(). "
ifnotall(char in allowed_chars for char in expression):
return"错误: 输入包含不允许的字符。"
# 使用安全的 eval 执行
result = eval(expression, {"__builtins__": None}, {})
returnstr(result)
except Exception as e:
raise ToolException(f"计算出错: {e}")
@tool
defget_current_time() -> str:
"""获取当前日期和时间字符串。"""
current_time = datetime.now().isoformat()
returnf"当前时间是{current_time}"
@tool
defdice_roller(sides: int = 6) -> str:
"""掷一个指定面数的骰子并返回结果。"""
try:
result = random.randint(1, sides)
returnstr(result)
except Exception as e:
returnf"掷骰子出错: {e}"
# --- 2. 将工具函数聚合到一个列表中 ---
tools = [calculator, get_current_time, dice_roller]
代码释义:
- •
@tool装饰器: 这是 LangChain 的“魔法棒”。将它放在一个函数上,LangChain 就能自动理解这个函数的用途(通过函数的文档字符串"""...""")、输入参数和返回类型。这样,大语言模型(LLM)就能知道在何时、如何调用这个工具。 - • 文档字符串 (Docstring):
"""..."""里的内容至关重要!LLM会读取这段描述来决定是否使用这个工具。描述越清晰,Agent 的决策就越准确。 - •
tools列表: 我们将所有定义好的工具函数放在一个列表中,方便后续统一提供给 Agent。
第三步:配置我们的 FastAPI 应用
接下来,我们来设置一些“老朋友”——配置文件、LLM 加载器等。
app/core/config.py:
from functools import lru_cache
from pydantic_settings import BaseSettings, SettingsConfigDict
classSettings(BaseSettings):
"""应用主配置"""
# 应用基本信息
app_name: str = "Agent Service Demo"
debug: bool = False
# Ollama 配置
ollama_base_url: str = "http://localhost:11434"
ollama_default_model: str = "qwen3:4b-instruct"
# pydantic-settings 的配置
model_config = SettingsConfigDict(
env_file=".env", env_file_encoding="utf-8", case_sensitive=False
)
@lru_cache
defget_settings() -> Settings:
"""返回一个缓存的 Settings 实例,确保配置只被加载一次。"""
return Settings()
settings = get_settings()
模型选择提示: 在这里我使用了 qwen3:4b-instruct 模型。它小巧、高效,遵循指令的能力很强,非常适合这个项目。经验表明,至少需要 3B 参数量以上的模型才能较好地驱动 Agent 使用工具。
app/core/llm_loader.py:
from functools import lru_cache
from loguru import logger
from langchain_ollama import ChatOllama
from app.core.config import settings
@lru_cache(maxsize=1)
defget_llm() -> ChatOllama:
"""
根据全局配置初始化并返回一个 ChatOllama 实例。
这是一个同步函数,将在应用的 lifespan 中被调用。
"""
model = settings.ollama_default_model
logger.info(f"正在初始化Ollama LLM: {model}...")
try:
llm = ChatOllama(
model=model, base_url=settings.ollama_base_url, temperature=0.5
)
logger.success(f"Ollama LLM '{model}' 初始化成功。")
return llm
except Exception as e:
logger.error(f"初始化 Ollama LLM 失败: {e}")
raise
代码释义:
- •
@lru_cache(maxsize=1): 这是一个非常实用的 Python 装饰器。maxsize=1意味着它会缓存第一次调用的结果。当get_llm()被再次调用时,它会立即返回缓存中的同一个 LLM 实例,而不会重新创建一个新的。这保证了在整个应用中,我们使用的是同一个、唯一的 LLM 对象,避免了资源浪费。 - • 职责分离: 这个文件的作用是集中管理 LLM 的创建。如果未来我们想换成 OpenAI 或其他模型,只需要修改这一个文件,而不需要改动应用的其他部分。
第四步:重头戏——组装 LangGraph Agent
现在,让我们来构建 Agent 的“大脑”。
app/agents/basic_agent.py:
from langchain_core.runnables import Runnable
from langchain_ollama import ChatOllama
from langgraph.checkpoint.memory import MemorySaver
from langgraph.prebuilt import create_react_agent
from loguru import logger
from app.tools.demo_tools import tools
asyncdefassemble_langgraph_agent(llm: ChatOllama) -> Runnable:
"""
一个“组装厂”函数,负责将 LLM 和工具组装成一个可运行的 LangGraph Agent。
"""
logger.info("开始组装 LangGraph Agent...")
# MemorySaver 用于在多次调用之间保持对话状态(短期记忆)。
# 对于生产环境,可以替换为 SqliteSaver, RedisSaver 等持久化存储。
memory = MemorySaver()
# create_react_agent 是 LangGraph 提供的一个高级工厂函数,
# 它可以快速创建一个遵循 ReAct (Reason + Act) 逻辑的 Agent。
runnable_agent = create_react_agent(
model=llm,
tools=tools,
checkpointer=memory,
)
logger.success(f"✅ LangGraph Agent 组装完成,使用模型: {llm.model}")
return runnable_agent
代码释义:
这段代码是 Agent 的核心组装逻辑,可以理解为一个“Agent 组装厂”。
-
MemorySaver(): 这是 Agent 的“短期记忆”。它能让 Agent 记住同一场对话中的上下文。LangGraph提供了多种checkpointer(检查点),如SqliteSaver、RedisSaver,可以将对话历史持久化到数据库中,实现长期记忆。
-
create_react_agent(...): 这是LangGraph提供的“一键组装”功能。它会创建一个遵循 ReAct (Reasoning + Acting) 模式的 Agent。
- • Reasoning (思考): LLM 会根据你的问题和可用工具进行思考,决定下一步该做什么。例如,“用户问现在几点,我应该使用
get_current_time工具。” - • Acting (行动): LLM 决定调用工具,然后
LangGraph框架会实际执行这个工具函数。 - • 这个过程会循环进行,直到 LLM 认为它已经获得了足够的信息来回答你的初始问题。
-
- 参数说明:
- •
model=llm: 告诉 Agent 使用哪个 LLM 作为“大脑”。 - •
tools=tools: 将我们之前定义的工具列表提供给 Agent。 - •
checkpointer=memory: 为 Agent 配置好记忆系统。
最终,这个函数返回一个 runnable_agent,这是一个可以被调用和执行的完整 Agent 对象。
第五步:应用生命周期管理 (Lifespan)
我们使用 FastAPI 现代化的 lifespan state 模式,在应用启动时加载模型和 Agent,并在请求处理中安全地访问它们。
app/lifespan.py:
from typing import TypedDict
from collections.abc import AsyncIterator
from contextlib import asynccontextmanager
from fastapi import FastAPI
from loguru import logger
from langchain_ollama import ChatOllama
from langchain_core.runnables import Runnable
from app.core.config import get_settings
from app.core.llm_loader import get_llm
from app.agents.basic_agent import assemble_langgraph_agent
classAppState(TypedDict):
"""定义应用生命周期中共享状态的结构。"""
llm: ChatOllama
agent: Runnable
@asynccontextmanager
asyncdeflifespan(app: FastAPI) -> AsyncIterator[AppState]:
# -------- 启动 --------
get_settings()
logger.info("🚀 应用启动,配置已就绪。")
# 1. 加载 LLM
llm = get_llm()
# 2. LLM健康检查
try:
await llm.ainvoke("Hello")
logger.success("✅ LLM 健康检查通过...")
except Exception as e:
logger.error(f"❌ LLM 初始化失败: {e}")
raise RuntimeError("LLM 初始化失败,应用启动中止")
# 3. 组装 LangGraph Agent
agent = await assemble_langgraph_agent(llm)
# 4. 通过 yield 将状态传递给应用
yield AppState(llm=llm, agent=agent)
# -------- 关闭 --------
logger.info("应用关闭,资源已释放。")
代码释义:
lifespan 就像是应用的“开/关机”流程。
- •
yield之前: 这部分代码在 FastAPI 应用启动时执行。我们按顺序:加载配置 -> 初始化 LLM -> 对 LLM 进行一次快速的“健康检查” -> 组装 Agent。 - • 健康检查:
await llm.ainvoke("Hello")这一步非常重要。它确保了我们的应用在启动时就能连接到 Ollama 服务,如果连接失败,应用会立即报错退出,而不是等到第一个用户请求进来时才发现问题。 - •
yield AppState(...): 这是关键。yield将llm和agent实例作为一个字典“产出”。FastAPI 会将这个字典保存在app.state中。这样,在后续的请求中,我们可以通过request.state来安全地访问这些已经初始化好的对象。 - •
yield之后: 这部分代码在应用关闭时执行,用于进行资源清理。
第六步:服务与依赖注入
为了在路由函数中方便地获取 Agent 和 LLM,我们创建依赖注入函数。
app/core/deps.py:
# app/core/deps.py
from typing import cast
from fastapi import Request, HTTPException, status
from langchain_core.runnables import Runnable
from langchain_ollama import ChatOllama
defget_agent(request: Request) -> Runnable:
"""
一个 FastAPI 依赖项。
它从 lifespan state (request.state) 中获取 Agent 实例。
这是 FastAPI 推荐的、类型安全的方式。
"""
ifnothasattr(request.state, "agent"):
raise HTTPException(
status_code=status.HTTP_503_SERVICE_UNAVAILABLE,
detail="Agent service is not initialized."
)
# 使用 cast 帮助类型检查器理解 request.state.agent 的确切类型
return cast(Runnable, request.state.agent)
defget_llm(request: Request) -> ChatOllama:
"""
一个 FastAPI 依赖项,用于从 request.state 中获取 LLM 实例。
"""
ifnothasattr(request.state, "llm"):
raise HTTPException(
status_code=status.HTTP_503_SERVICE_UNAVAILABLE,
detail="LLM service is not initialized."
)
return cast(ChatOllama, request.state.llm)
现在,我们来编写调用 Agent 的核心服务逻辑,支持流式和非流式两种方式。
app/services/agent_service.py:
# app/services/agent_service.py
import json
from typing import AsyncGenerator
from loguru import logger
from langchain_core.runnables import Runnable, RunnableConfig
from langchain_core.messages import HumanMessage, AIMessage
asyncdefrun_agent(agent: Runnable, query: str, session_id: str) -> str:
"""
以非流式的方式异步调用 Agent,并传入会话ID。
"""
logger.info(f"非流式调用 Agent [Session: {session_id}], 查询: '{query}'")
config: RunnableConfig = {"configurable": {"thread_id": session_id}}
result = await agent.ainvoke({"messages": [HumanMessage(content=query)]}, config)
for message inreversed(result["messages"]):
ifisinstance(message, AIMessage):
content = message.content
ifisinstance(content, str):
logger.success(f"成功获取非流式响应 [Session: {session_id}]。")
return content
elifisinstance(content, list):
text_parts = [
part["text"]
for part in content
ifisinstance(part, dict) and part.get("type") == "text"
]
if text_parts:
return"\n".join(text_parts)
raise ValueError("Agent 未能生成有效的 AI 响应。")
asyncdefstream_agent(
agent: Runnable, query: str, session_id: str
) -> AsyncGenerator[str, None]:
"""
以流式的方式异步调用 Agent,并传入会话ID。
"""
logger.info(f"流式调用 Agent [Session: {session_id}], 查询: '{query}'")
config: RunnableConfig = {"configurable": {"thread_id": session_id}}
logger.debug(f"准备调用 Agent.astream_events,传入的 config: {config}")
# 1. 模型流式输出
asyncfor event in agent.astream_events(
{"messages": [HumanMessage(content=query)]}, version="v1", config=config
):
kind = event["event"]
if kind == "on_chat_model_stream":
chunk = event.get("data", {}).get("chunk")
if chunk:
content = chunk.content
if content:
yieldf"data: {json.dumps({'content': content})}\n\n"
代码释义:
这部分是实际与 LangGraph Agent 交互的地方。
-
- 会话管理 (
session_id):
- 会话管理 (
- •
config: RunnableConfig = {"configurable": {"thread_id": session_id}} - • 这是 LangGraph 中实现多轮对话记忆的关键!我们将
session_id包装在configurable字典的thread_id字段中。LangGraph会根据这个thread_id去查找对应的对话历史 (checkpointer),从而实现上下文记忆。
-
- 非流式调用 (
run_agent):
- 非流式调用 (
- • 使用
agent.ainvoke()发起调用。 - • 它会等待 Agent 完成所有思考和工具调用,最后返回一个包含完整对话历史的结果。
- • 我们的代码需要从返回的消息列表中,找到最后一条
AIMessage,并提取其内容作为最终答案。
-
- 流式调用 (
stream_agent):
- 流式调用 (
- • 使用
agent.astream_events()。这会返回一个异步事件流。 - • 我们监听
event["event"] == "on_chat_model_stream"这种类型的事件,这代表 LLM 正在生成内容的“token 流”。 - • 我们将每个内容块 (
chunk.content) 包装成 Server-Sent Event (SSE) 格式 (data: {...}\n\n) 并yield出去,这样前端就能实时接收并显示了。
第七步:定义 API 接口
我们需要定义请求和响应的数据结构,这得益于 Pydantic 的强大功能。
app/schemas/chat_schema.py:
from pydantic import BaseModel, Field
classChatRequest(BaseModel):
"""聊天请求的数据模型。"""
query: str = Field(..., min_length=1, description="用户的输入查询")
session_id: str | None = Field(default=None, description="会话ID,用于保持多轮对话。")
classChatResponse(BaseModel):
"""非流式聊天响应的数据模型。"""
answer: str = Field(..., description="Agent 返回的最终答案")
session_id: str = Field(..., description="当前会话的ID。")
为什么需要 Schema?
在 FastAPI 中,使用 Pydantic 模型(Schema)能带来三大好处:
-
- 自动数据校验:FastAPI 会自动检查请求体是否符合
ChatRequest的格式。
- 自动数据校验:FastAPI 会自动检查请求体是否符合
-
- 自动类型转换:如果可能,它会自动转换数据类型。
-
- 自动生成文档:Swagger UI 或 ReDoc 页面会根据这些模型生成清晰、可交互的 API 文档。
最后,我们来编写 FastAPI 路由,将所有部分连接起来。
app/api/query_routes.py:
# app/api/v1/agent.py
import uuid
from loguru import logger
from fastapi import APIRouter, Depends, HTTPException, status
from starlette.responses import StreamingResponse
from langchain_core.runnables import Runnable
from langchain_ollama import ChatOllama
from app.core.deps import get_agent, get_llm
from app.schemas.chat_schema import ChatRequest, ChatResponse
from app.services import agent_service
router = APIRouter(tags=["Agent"])
@router.post("/chat/invoke", response_model=ChatResponse, summary="非流式聊天")
asyncdefchat_invoke(
request: ChatRequest,
# 使用 Depends 从 lifespan state 中安全地注入 agent 实例
agent: Runnable = Depends(get_agent)
):
"""
与 Agent 进行一次性问答。
- 如果请求中不提供 `session_id`,将创建一个新的会话。
- 如果提供 `session_id`,将继续在该会话中进行多轮对话。
"""
# 核心会话管理逻辑:如果客户端没有提供,我们在此处生成一个新的
session_id = request.session_id orstr(uuid.uuid4())
try:
# 将 agent, query, 和 session_id 一同传递给服务层
answer = await agent_service.run_agent(agent, request.query, session_id)
return ChatResponse(answer=answer, session_id=session_id)
except Exception as e:
logger.error(f"Agent 调用失败 [Session: {session_id}]: {e}")
raise HTTPException(
status_code=status.HTTP_500_INTERNAL_SERVER_ERROR,
detail=f"Agent execution failed: {e}"
)
@router.post("/chat/stream", summary="流式聊天")
asyncdefchat_stream(
request: ChatRequest,
agent: Runnable = Depends(get_agent)
):
"""
与 Agent 进行流式聊天,支持多轮对话记忆。
"""
session_id = request.session_id orstr(uuid.uuid4())
# 注意:流式响应通常不直接返回 session_id,客户端需要自己管理。
# 一种常见的做法是客户端在第一次请求后,从非流式端点或特定session端点获取ID。
return StreamingResponse(
agent_service.stream_agent(agent, request.query, session_id),
media_type="text/event-stream"
)
代码释义:
- •
Depends(get_agent): 这是 FastAPI 的依赖注入系统。当请求到达时,FastAPI 会自动调用get_agent函数,并将返回的agent实例注入到我们的路由函数中。这让我们的代码非常干净和解耦。 - • 会话 ID 管理:
session_id = request.session_id or str(uuid.uuid4())这行代码实现了简单的会话管理。如果客户端在请求中提供了session_id,我们就使用它;如果没有,就用uuid.uuid4()创建一个新的,并返回给客户端,以便它在后续请求中使用。 - •
StreamingResponse: 对于流式接口,我们返回StreamingResponse。它的第一个参数是我们的stream_agent生成器函数,FastAPI 会自动处理,将生成的内容以流的形式发送给客户端。media_type="text/event-stream"明确告诉浏览器这是一个 Server-Sent Event 流。
最后一步:启动应用
记得在 main.py 中挂载你的路由,然后就可以启动应用了!你可以在 FastAPI 自动生成的 Swagger UI (http://127.0.0.1:8000/docs) 中测试你的 Agent。
Gradio 前端聊天界面代码可以在项目仓库中找到,有兴趣的同学可以自行复制或拉取。
总结
恭喜你!通过这个小项目,你已经掌握了:
- • 如何为 AI Agent 创建和注册工具。
- • 使用
LangGraph的create_react_agent快速构建一个具备思考和行动能力的 Agent。 - • 通过
lifespanstate 模式在 FastAPI 中安全高效地管理 Agent 和 LLM 实例。 - • 实现了支持多轮对话记忆的流式和非流式 API 接口。
这为你打开了通往更复杂、更有趣的 AI 应用开发的大门。快去动手试试,让你的 Agent 拥有更多强大的工具吧!
大模型未来如何发展?普通人能从中受益吗?
在科技日新月异的今天,大模型已经展现出了令人瞩目的能力,从编写代码到医疗诊断,再到自动驾驶,它们的应用领域日益广泛。那么,未来大模型将如何发展?普通人又能从中获得哪些益处呢?
通用人工智能(AGI)的曙光:未来,我们可能会见证通用人工智能(AGI)的出现,这是一种能够像人类一样思考的超级模型。它们有可能帮助人类解决气候变化、癌症等全球性难题。这样的发展将极大地推动科技进步,改善人类生活。
个人专属大模型的崛起:想象一下,未来的某一天,每个人的手机里都可能拥有一个私人AI助手。这个助手了解你的喜好,记得你的日程,甚至能模仿你的语气写邮件、回微信。这样的个性化服务将使我们的生活变得更加便捷。
脑机接口与大模型的融合:脑机接口技术的发展,使得大模型与人类的思维直接连接成为可能。未来,你可能只需戴上头盔,心中想到写一篇工作总结”,大模型就能将文字直接投影到屏幕上,实现真正的心想事成。
大模型的多领域应用:大模型就像一个超级智能的多面手,在各个领域都展现出了巨大的潜力和价值。随着技术的不断发展,相信未来大模型还会给我们带来更多的惊喜。赶紧把这篇文章分享给身边的朋友,一起感受大模型的魅力吧!
那么,如何学习AI大模型?
在一线互联网企业工作十余年里,我指导过不少同行后辈,帮助他们得到了学习和成长。我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑。因此,我坚持整理和分享各种AI大模型资料,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频。
学习阶段包括:
1.大模型系统设计
从大模型系统设计入手,讲解大模型的主要方法。包括模型架构、训练过程、优化策略等,让读者对大模型有一个全面的认识。

2.大模型提示词工程
通过大模型提示词工程,从Prompts角度入手,更好发挥模型的作用。包括提示词的构造、优化、应用等,让读者学会如何更好地利用大模型。

3.大模型平台应用开发
借助阿里云PAI平台,构建电商领域虚拟试衣系统。从需求分析、方案设计、到具体实现,详细讲解如何利用大模型构建实际应用。

4.大模型知识库应用开发
以LangChain框架为例,构建物流行业咨询智能问答系统。包括知识库的构建、问答系统的设计、到实际应用,让读者了解如何利用大模型构建智能问答系统。
5.大模型微调开发
借助以大健康、新零售、新媒体领域,构建适合当前领域的大模型。包括微调的方法、技巧、到实际应用,让读者学会如何针对特定领域进行大模型的微调。


6.SD多模态大模型
以SD多模态大模型为主,搭建文生图小程序案例。从模型选择、到小程序的设计、到实际应用,让读者了解如何利用大模型构建多模态应用。
7.大模型平台应用与开发
通过星火大模型、文心大模型等成熟大模型,构建大模型行业应用。包括行业需求分析、方案设计、到实际应用,让读者了解如何利用大模型构建行业应用。


学成之后的收获👈
• 全栈工程实现能力:通过学习,你将掌握从前端到后端,从产品经理到设计,再到数据分析等一系列技能,实现全方位的技术提升。
• 解决实际项目需求:在大数据时代,企业和机构面临海量数据处理的需求。掌握大模型应用开发技能,将使你能够更准确地分析数据,更有效地做出决策,更好地应对各种实际项目挑战。
• AI应用开发实战技能:你将学习如何基于大模型和企业数据开发AI应用,包括理论掌握、GPU算力运用、硬件知识、LangChain开发框架应用,以及项目实战经验。此外,你还将学会如何进行Fine-tuning垂直训练大模型,包括数据准备、数据蒸馏和大模型部署等一站式技能。
• 提升编码能力:大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握将提升你的编码能力和分析能力,使你能够编写更高质量的代码。
学习资源📚
- AI大模型学习路线图:为你提供清晰的学习路径,助你系统地掌握AI大模型知识。
- 100套AI大模型商业化落地方案:学习如何将AI大模型技术应用于实际商业场景,实现技术的商业化价值。
- 100集大模型视频教程:通过视频教程,你将更直观地学习大模型的技术细节和应用方法。
- 200本大模型PDF书籍:丰富的书籍资源,供你深入阅读和研究,拓宽你的知识视野。
- LLM面试题合集:准备面试,了解大模型领域的常见问题,提升你的面试通过率。
- AI产品经理资源合集:为你提供AI产品经理的实用资源,帮助你更好地管理和推广AI产品。
👉获取方式: 😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】

更多推荐
 26
26 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)