搜索


武汉城市开发者社区
https://devpress.csdn.net/wuhan
成员
为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。



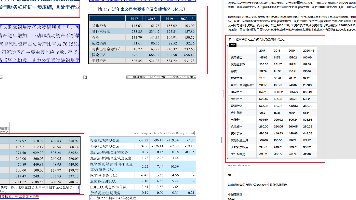
- 208 5
- 176 6
- 5803 55
- 1698 59
- 1.3w 77
- 3.1w 88
- 1.3w 9
- 9598 5
- 6.3w 91
- 171 5