登录社区云,与社区用户共同成长
邀请您加入社区
MCP协议通过标准化的工具接口,大幅降低了AI Agent与外部系统集成的复杂度。但工具调用的便利性也带来了新的安全挑战。本文展示的安全数据分析Agent实践,核心原则可以归纳为三点:安全优先(在工具层面实现安全校验,而非依赖LLM的自觉)、纵深防御(多层安全机制叠加,单层失效不影响整体安全)、可观测性(完整的审计日志和监控告警,确保问题可追溯)。随着MCP生态的持续繁荣,工具调用的标准化将进一步
2026年的AI Agent框架生态呈现出"收敛中分化"的特征:协议层面快速收敛到MCP+A2A的标准组合,框架层面则根据场景分化出不同的生态位。对于技术决策者而言,关键不是寻找"最好的框架",而是理解每个框架的设计哲学和适用边界,根据自身的任务特征、团队能力和生态集成需求做出匹配的选择。Agent技术的未来不在于框架之争,而在于工程实践的积累和行业经验的沉淀。能够控制成本、保障安全、持续优化的团
Vibe Coding代表了一种编程范式的根本转变:从"实现驱动"到"意图驱动"。虽然Karpathy宣布了Vibe Coding的"死亡",但它的核心理念——用自然语言驱动开发、拥抱执行反馈循环——已经深刻融入了Agentic Engineering的实践中。对于开发者而言,最重要的不是纠结于概念的定义,而是掌握与AI高效协作的能力。无论是叫Vibe Coding还是Agentic Engine
2026年被称为AI Agent的"工程化落地元年"。从年初的世界人工智能大会到各大云厂商的技术峰会,Agent已经取代大模型本身成为最热门的话题。但热闹背后,一线开发者面临着一个真实的困境:框架太多、选型太难、落地太坑。本文将基于我在多个Agent项目中的实战经验,系统梳理当前主流Agent开发框架的技术特点、适用场景和工程实践,帮助你在纷繁的技术选项中做出明智的决策。
当你还在为"选gpt-4o还是claude-3.5-sonnet"纠结时,真正的高手已经把这个决策本身自动化了。每3-6个月模型价格和能力都会变,精心设计的路由规则很快过时;一个千人团队每小时都有人要改配置——静态路由的本质是人肉运维,这才是大模型网关真正的瓶颈。Auto模式用算法持续优化决策,反馈闭环自动进化,最终结果:整体满意度提升8%,整体成本下降12%,不改一行业务代码。
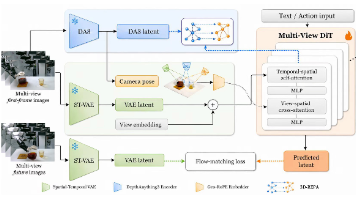
26年6月来自中科院的工业AI研究所的论文“PAIWorld: A 3D-Consistent World Foundation Model for Robotic Manipulation”。世界基础模型(WFMs)已成为物理环境的强大模拟器,但它们主要在单视角环境下运行,缺乏机器人操作任务所需的多视角三维一致性。机器人系统本质上依赖多个摄像头(包括第一人称视角、手眼视角和腕部安装视角)来获取互
本文系统梳理了人工智能(AI)的基础知识体系,重点解析了大模型(LLM)的核心原理、技术演进及应用边界。主要内容包括: AI基础认知:从规则驱动到数据驱动的范式转变,强调AI=数据+算法+算力的技术本质,区分了弱AI与通用AI(AGI)的能力差异。 技术发展史:回顾AI七十年发展,从符号主义、专家系统到深度学习的五次技术浪潮,重点分析Transformer架构如何推动大模型革命。 大模型原理:详解
ChatGPT 份额跌破 50% 是标志性的——但 Anthropic 用不到 1/4 的用户赚了更多钱,这才是真正值得盯住的结构性信号。
今年年初我开始接触AI Agent,第一个感觉就是:大模型本身像一个知识渊博的专家,但它只会动嘴,不会动手。而Agent不一样,它不仅能说,还能调用工具、查阅资料、执行操作,像一个真正的助理。举个例子:你问大模型“明天北京飞上海的机票多少钱”,它只能告诉你“请去携程查询”。但如果你问一个Agent,它会自己去查航班信息、比价、甚至帮你下单。这篇文章就是我学习Agent开发过程中的笔记和总结,从最基
现有研究已开始评测前沿模型的病毒学知识和实验推理能力,但在真实的潜在风险链条中,模型究竟能提供多大程度的实质性帮助,需要进行验证,特别是当模型以智能体形态出现,能组合知识库、搜索引擎、文件读写等工具时,其有效能力边界可能远超单轮问答的测试结果。当前大语言模型正从“聊天机器”进化为能调用工具、规划任务的“智能体”。这种进化在生物信息学、实验设计等领域展现出巨大潜力,除此之外,需要正视一个关键问题:当
系列:100 天系统学习 AI Agent 开发当前阶段:RAG、知识库与工具边界今日目标:知识库助手的核心是资料导入、检索、回答、引用和无法回答时的兜底。
这里推荐织信Informat全栈低代码平台基于数据模型优先的设计理念,提供大量标准化的组件,还内置了组件设计器、表单设计器、自动化(图形化编程环境)、脚本、工作流引擎(BPMN2.0)、自定义API、BI等功能,能帮助企业构建高度复杂核心的业务系统。如ERP、PLM、MES、SCM、WMS、OMS、EMS、项目、企业服务等多个应用场景,全面助力企业落地数字化转型战略目标。自上而下建立客户协同机制,
零基础认识大语言模型(LLM)工作原理(16.未来的大模型与 AI Agent:从模型竞争到系统竞争)–结尾篇 引言:从模型到系统的转变在过去的几年里,大语言模型(LLM)的竞争主要集中在模型本身的参数规模、训练数据和计算能力上。然而,随着技术的发展,我们正见证一个重要的转变:未来的竞争不再是单一模型的比拼,而是整个AI系统生态的竞争。这一变化的核心在于AI Agent(智能体)的兴起,它将LLM
2026年生成式AI技术深度渗透B端采购场景,推动机械设备行业营销模式转型。传统线下拓客和竞价推广效益下滑,适配AI搜索逻辑的生成式引擎优化(GEO)成为新选择。西安信之上信息技术有限公司推出机械设备行业专属GEO方案,通过优化语义匹配、信源可信度和内容完整度,提升企业在AI问答中的曝光率。该方案针对行业重决策、强属地特性,构建全平台语义适配、属地化场景匹配、可信信息库和透明数据追踪体系,已帮助西
最近在 Windows 系统上体验 OpenAI 官方推出的Codex 编程客户端,准备安装 Windows 桌面版本。按照官方流程下载时发现,Windows 版本默认跳转到Microsoft Store(微软应用商店)。微软商店打不开Microsoft Store 无法登录搜索不到 Codex 应用提示「此应用当前不可用」点击安装按钮没有反应地区限制导致无法下载经过测试发现,Codex Wind
虚假API与函数:生成看似合理但实际不存在的库函数或方法签名。逻辑正确但语义错误:代码语法无误,但业务逻辑与需求完全偏离。过度自信的补全:在缺乏上下文时强行生成“合理”但错误的代码片段。依赖版本错配:生成基于过时或未来版本API的代码,导致运行时错误。AI不是替代者,而是放大器。理解其边界,建立防御性使用习惯,才能让Codex等工具真正成为提升工程效能的利器,而非引入隐性技术债的风险源。
关键词:大模型工具深度运用、AI辅助学术研究、LLM论文写作、科研效率提升、学术AI工具 适用场景:学术论文写作、科研文献综述、实验设计、数据分析 数据更新时间:2026年7月。论文撰写2-6周大纲生成、段落撰写、润色校对Paperpal, Grammarly, 笔杆2-4×。实验设计1-3周方法建议、参数优化、统计方案Claude, ChatGPT-4o2-3×。关键词:大模型工具深度运用、AI
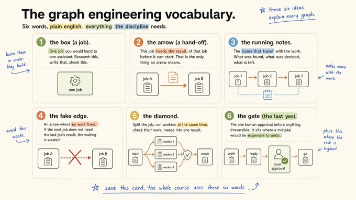
这篇文章不是概念科普,是一份能直接落地的手册。我会先把"图"到底是什么讲清楚(包括一个最容易踩坑的"假边"概念),再给一个我认为今年最值得掌握的模式,然后三个能直接抄的构建,最后收一份操作清单。所有 prompt 我都保留了英文原样——像 Claude Code 这类工具对英文指令里的"编排意图"识别更稳,复制即可用;如果你用 LangGraph / CrewAI / 自研 DAG 调度,思想完全
Grok Build代表了AI编程工具的一个重要方向:终端原生、隐私优先、完全开源。尽管经历了隐私风波的阵痛,但开源后的Grok Build正在快速赢得开发者社区的信任。对于追求代码隐私和自主控制的开发者来说,Grok Build提供了一个强有力的选择。它的Rust实现、本地模型支持和完整的工程化能力,使其成为2026年最值得关注的AI编程工具之一。
Docker和Kubernetes已经成为现代软件部署的事实标准。掌握容器化技术和编排能力,是每一位后端开发者和运维工程师的必修课。本文从Dockerfile编写到Kubernetes生产部署,覆盖了完整的容器化技术栈。建议按照本文的示例逐步实践,从单机Docker Compose开始,逐步过渡到Kubernetes集群管理,建立起完整的云原生技能体系。
AI Agent是能够自主执行任务的智能体。理解复杂任务目标制定执行计划调用外部工具(搜索、计算、API)根据结果调整策略最终完成任务2026年学习AI大模型,不需要成为数学天才,也不需要购买昂贵的GPU。关键在于:掌握正确的工具链、理解核心概念、通过项目实战积累经验。本文提供的学习路径和代码示例,可以让你在2-3个月内从零基础成长为能够独立开发AI应用的工程师。记住,最重要的不是学了多少理论,而
2026年7月15日,《人工智能拟人化互动服务管理暂行办法》正式施行。豆包、千问同步下线智能体功能,腾讯元宝、网易妙时提前关停。AI陪伴产品为什么被整顿?Character.AI少年自杀案、情感依赖、未成年人保护、企业合规路径——本文从七个维度拆解这场AI监管风暴背后的技术、人性与权力博弈。AI从业者、产品经理、合规人员必读。
26年6月来自阿里达摩院、香港具身智能实验室、港中文、阿里湖畔实验室和蚂蚁集团的论文“RynnWorld-Teleop: An Action-Conditioned World Model for Digital Teleoperation”。扩展机器人学习规模需要海量且多样化的轨迹数据,但目前数据采集受限于物理遥操作模式,因为每一次演示都需要操作员将时间投入到特定的硬件和工作空间中。提出一种
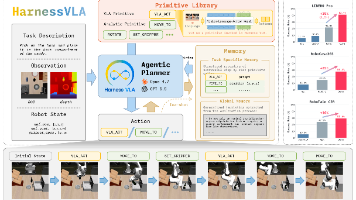
26年7月来自清华、Striding AI公司、普渡、中科院自动化所、无问芯穹公司、港科大和中关村学院的论文“Harness VLA: Steering Frozen VLAs into Reliable Manipulation Primitives via Memory-Guided Agents”。基于语言指令的操作任务既需要精确且涉及丰富接触交互的控制能力,也需要针对语言、场景及长程任务序
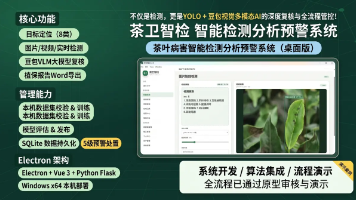
本项目是一个基于人工智能技术的茶叶病害检测分析预警系统,旨在通过计算机视觉与深度学习模型,为茶园与鲜叶质检场景提供叶片病害、虫害征状与健康状态的识别与预警服务。系统集成了图片检测、视频检测、实时检测、模型评估、模型管理、数据集管理等多项功能,构建了一个完整的茶叶叶片目标检测与植保辅助决策服务平台。
AFLoc(Annotation-Free pathology Localization)是 2026 年 1 月发表于《Nature Biomedical Engineering》的零标注多模态视觉 - 语言模型,主打医疗影像场景的病灶定位,通过多层级语义对齐技术,无需人工标注即可将临床报告文本与医学影像跨模态关联,实现零样本跨模态迁移,性能远超现有多模态模型,部分指标甚至超越人类放射科医生基准
LangChain是一个用于构建基于LLM的应用程序的框架。它提供了一套工具和抽象,使得开发者能够快速构建复杂的AI应用,包括聊天机器人、问答系统、代码生成器等。Prompt是指用户输入给LLM的文本,用于引导LLM生成特定的输出。一个好的Prompt能够让LLM更准确地理解用户意图,生成高质量的响应。Chain是LangChain中最核心的概念之一。它是一系列组件的组合,用于处理输入并生成输出。
打开 Trae,进 设置 → 模型,点「添加模型」。API 格式:选 OpenAI(Kimi 走 OpenAI 兼容协议)接口地址:填,注意末尾带/v1。如果你开关了「完整 URL」,就填模型 ID:填kimi-k3,区分大小写,不是也不是API 密钥:填刚才复制的 sk-xxx点「添加模型」后,Trae 会自动调用服务商接口验证密钥是否有效。如果连接成功,模型就加好了;如果失败,窗口会显示服务商
AI Agent安全是一个系统工程,需要从基础设施、模型、应用三个层面构建纵深防御体系。安全左移(在开发阶段发现和修复问题)和运行时监控(实时检测和响应威胁)同等重要。随着Agent获得越来越多的自主权和工具访问权限,安全防护的复杂度将持续增加。企业需要将安全作为Agent项目的核心考量因素,而非事后补救的附加项。只有构建起可信赖的安全体系,AI Agent才能真正从"概念验证"走向"规模化部署"
Vibe Coding的核心逻辑可以用一句话概括:人类只负责描述业务意图,把全部代码实现细节交给AI,依靠运行效果与直观反馈完成迭代。这是一种彻底的"意图导向编程"——你说出目的地,AI负责规划路线、驾驶车辆、处理路况。在传统编程模式中,开发者是"工匠",需要记忆语法、手写逻辑、查阅文档、逐行调试。在Vibe Coding模式下,开发者转变为"指挥家",核心工作变成了描述需求、审查结果、反馈修正。
语言模型
——语言模型
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 智能体开发者社区
智能体开发者社区
 AI编程社区
AI编程社区



 DAMO开发者矩阵
DAMO开发者矩阵

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 AtomGit AI 社区
AtomGit AI 社区






 深开鸿 技术专区
深开鸿 技术专区