
深度拆解 DeepSeek-V3/R1 推理架构!从核心组件到工作流,揭秘高效推理的底层逻辑
本文深度解析了DeepSeek-V3/R1推理系统的架构设计与工作流程。该系统通过API服务器、负载均衡器(预填充/解码/专家并行)、预填充服务、解码服务及外部键值缓存等核心组件的协同运作,实现了高效推理。重点阐述了负载均衡器如何根据实例负载动态分配请求,以及专家并行机制如何优化GPU计算资源利用率。文章还详细介绍了从请求接收、负载均衡、专家分配到结果缓存的全流程,展现了系统在吞吐量、响应速度和可
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《GPT多模态大模型与AI Agent智能体》(跟我一起学人工智能)【陈敬雷编著】【清华大学出版社】
清华《GPT多模态大模型与AI Agent智能体》书籍配套视频课程【陈敬雷】
GPT多模态大模型与AI Agent智能体系列一百九十六
深度拆解 DeepSeek-V3/R1 推理架构!从核心组件到工作流,揭秘高效推理的底层逻辑
3.12.1 DeepSeek-V3/R1推理系统架构剖析
DeepSeek-V3/R1推理系统的架构是其实现高效推理的关键支撑,它精心设计了各个组件及其交互流程,以达成更大吞吐和更低延迟的目标。整个架构主要围绕API服务器、负载均衡器以及各类服务展开,它们紧密协作,确保系统稳定、高效运行。
1.系统架构及核心组件功能解析
DeepSeek-V3/R1推理系统在追求更大吞吐和更低延迟的道路上,其精妙的架构设计功不可没。整个架构由多个核心组件协同构成,宛如一部精密运转的机器,每个组件都承担着不可或缺的功能,它们彼此配合,共同为系统的高效运行提供坚实保障。DeepSeek-V3/R1推理系统架构如图3-8所示。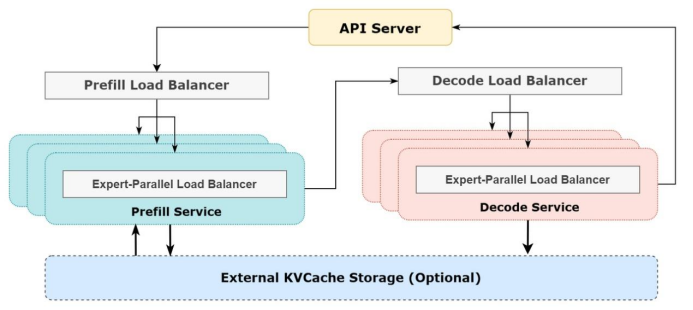
图3-8 DeepSeek-V3/R1推理系统架构
下面将深入剖析这些核心组件的功能与运作机制。
1)API服务器
API服务器作为系统与外部交互的唯一入口,承担着接收各类外部请求的重任。无论是来自网页端、APP,还是API接口的请求,都首先汇聚于此。它就像一座大厦的总入口,所有的访客都要从这里进入,其稳定性和高效性直接影响着整个系统对外服务的质量。通过对请求的初步接收和解析,API服务器为后续的处理流程奠定基础。
2)负载均衡器
(1)预填充负载均衡器:在预填充阶段,预填充负载均衡器发挥着关键的调度作用。它根据各个预填充服务实例的负载情况,将预填充请求合理地分发到多个预填充服务实例上。这一过程需要综合考虑多个因素,如每个实例当前的任务队列长度、计算资源占用情况等,确保请求能够快速得到处理,避免出现某个实例负载过高而其他实例闲置的情况,从而提高整体的处理效率。
(2)解码负载均衡器:类似于预填充负载均衡器,解码负载均衡器负责解码阶段的请求分发工作。它将解码请求精准地分配到多个解码服务实例中,依据每个实例的处理能力和实时负载,保证解码任务高效、均衡地执行,为系统的快速响应提供保障。
(3)专家并行负载均衡器:作为整个负载均衡体系的核心环节之一,专家并行负载均衡器存在于预填充服务和解码服务之前。它的主要职责是将请求分发到不同的专家进行并行处理。由于DeepSeek-V3/R1模型中存在大量专家,且不同专家的计算负载可能存在差异,专家并行负载均衡器通过特定的算法和策略,确保每个GPU上的专家计算量均衡,有效避免了因个别专家负载过高导致的系统性能瓶颈问题,充分发挥大规模跨节点专家并行的优势。
3)服务模块
(1)预填充服务:预填充服务专注于预填充任务的处理,涵盖数据预处理、初始化等关键步骤。在处理过程中,它通过专家并行负载均衡器实现负载均衡,确保每个实例都能高效地完成任务。例如,在处理文本生成任务时,预填充服务会对输入文本进行分词、特征提取等预处理操作,为后续的解码阶段提供高质量的基础数据。
(2)解码服务:解码服务主要负责解码任务,包括结果解码和后处理等工作。它同样借助专家并行负载均衡器进行负载均衡,保证解码任务的高效执行。在文本生成场景中,解码服务会将模型生成的中间结果进行解码,转化为用户可理解的文本形式,并进行必要的后处理,如语法检查、格式调整等。
4)外部键值缓存存储
外部键值缓存存储是一个可选的外部键值缓存存储组件,用于存储中间结果或缓存数据。在系统运行过程中,许多计算结果具有重复性,将这些结果存储在外部键值缓存中,可以避免重复计算,大大提高系统的响应速度。例如,在连续处理相似的文本请求时,已经计算过的中间结果可以直接从外部键值缓存中获取,无需再次进行复杂的计算,从而显著提升系统的整体性能。
2.推理系统工作流程详解
在了解了DeepSeek-V3/R1推理系统的核心组件功能后,深入探究其系统工作流程,能让我们更加全面地认识该系统是如何实现高效推理服务的。从外部请求进入系统,到最终输出处理结果,整个流程环环相扣,每个环节都经过精心设计与优化,各组件协同运作,充分发挥了系统的性能优势。详细工作流程如下。
(1)当外部请求到达时,API服务器首先接收请求,并对请求类型进行识别。如果是预填充请求,API服务器会将其转发到预填充负载均衡器;若是解码请求,则转发到解码负载均衡器。
(2)预填充负载均衡器和解码负载均衡器接收到请求后,分别根据各自的负载均衡策略,将请求分发到对应的专家并行负载均衡器。
(3)专家并行负载均衡器根据系统中各个专家和服务实例的负载情况,将请求分发到合适的预填充服务或解码服务实例进行处理。在分发过程中,会充分考虑每个GPU的计算能力和当前负载,确保负载均衡。
(4)预填充服务和解码服务实例接收到请求后,执行相应的任务。预填充服务进行数据预处理和初始化,解码服务进行解码和后处理。
(5)处理完成后,产生的结果可能会被存储到外部键值缓存存储中。这样,当后续有相似请求时,系统可以直接从键值缓存中获取结果,加速响应时间,提高系统的整体性能。
DeepSeek-V3/R1推理系统的架构设计通过各个组件的紧密协作和合理的负载均衡策略,有效提升了系统的吞吐量和响应速度,同时保障了系统的可扩展性和可靠性,为实现高效的推理服务提供了坚实的基础。
更多技术内容
更多技术内容可参见
清华《GPT多模态大模型与AI Agent智能体》书籍配套视频【陈敬雷】。
更多的技术交流和探讨也欢迎加我个人微信chenjinglei66。
总结
此文章有对应的配套新书教材和视频:
【配套新书教材】
《GPT多模态大模型与AI Agent智能体》(跟我一起学人工智能)【陈敬雷编著】【清华大学出版社】
新书特色:《GPT多模态大模型与AI Agent智能体》(跟我一起学人工智能)是一本2025年清华大学出版社出版的图书,作者是陈敬雷,本书深入探讨了GPT多模态大模型与AI Agent智能体的技术原理及其在企业中的应用落地。
全书共8章,从大模型技术原理切入,逐步深入大模型训练及微调,还介绍了众多国内外主流大模型。LangChain技术、RAG检索增强生成、多模态大模型等均有深入讲解。对AI Agent智能体,从定义、原理到主流框架也都进行了深入讲解。在企业应用落地方面,本书提供了丰富的案例分析,如基于大模型的对话式推荐系统、多模态搜索、NL2SQL数据即席查询、智能客服对话机器人、多模态数字人,以及多模态具身智能等。这些案例不仅展示了大模型技术的实际应用,也为读者提供了宝贵的实践经验。
本书适合对大模型、多模态技术及AI Agent感兴趣的读者阅读,也特别适合作为高等院校本科生和研究生的教材或参考书。书中内容丰富、系统,既有理论知识的深入讲解,也有大量的实践案例和代码示例,能够帮助学生在掌握理论知识的同时,培养实际操作能力和解决问题的能力。通过阅读本书,读者将能够更好地理解大模型技术的前沿发展,并将其应用于实际工作中,推动人工智能技术的进步和创新。
【配套视频】
清华《GPT多模态大模型与AI Agent智能体》书籍配套视频【陈敬雷】
视频特色: 前沿技术深度解析,把握行业脉搏
实战驱动,掌握大模型开发全流程
智能涌现与 AGI 前瞻,抢占技术高地
上一篇:《GPT多模态大模型与AI Agent智能体》系列一》大模型技术原理 - 大模型技术的起源、思想
下一篇:DeepSeek大模型技术系列五》DeepSeek大模型基础设施全解析:支撑万亿参数模型的幕后英雄
更多推荐

 17
17 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)