
上下文工程:超越RAG,大模型应用开发的未来方向
上下文工程是AI领域新概念,关注优化大模型输入而非改变结构。随着上下文窗口增长,出现"语境腐烂"现象,模型长语境下性能下降。文章提出写、选、压、隔四个核心环节,并详细解释实施方法。RAG技术在上下文工程框架下将迎来"第二春",理想系统应恰到好处地注入信息,这是大模型应用工程化的必经之路。
上下文工程是AI领域新概念,关注优化大模型输入而非改变结构。随着上下文窗口增长,出现"语境腐烂"现象,模型长语境下性能下降。文章提出写、选、压、隔四个核心环节,并详细解释实施方法。RAG技术在上下文工程框架下将迎来"第二春",理想系统应恰到好处地注入信息,这是大模型应用工程化的必经之路。
最近看一个播客是 Chroma 创始人兼 CEO Jeff 在 Len Space 播客的对话,对话的标题就是关于“RAG is dead”的观念,在视频中很明显的说明了原本的RAG的局限性和现在context engnieer的重要性,今天我就想全面分析一下“上文工程”(context engnieer)为什么这么爆火?以及将来RAG的形态到底何去何从……

简单解释一下Context Engineering (上下文工程) 是近期AI领域的一个新概念。它关注的不是如何训练大型模型,而是如何精心设计和优化给模型的输入内容。其核心思想是不改变模型的结构,只改变模型看到了什么,目的是让模型在有限的上下文窗口(Context Window)内尽可能地理解得更准确、回答得更好、花费更少。
什么是Context ?什么是 Context Window?
Context (上下文):
Context就是模型“看到”的一切,模型其实并不是只根据我们输入的prompt回复问题,还有其余的信息配合生成回复。
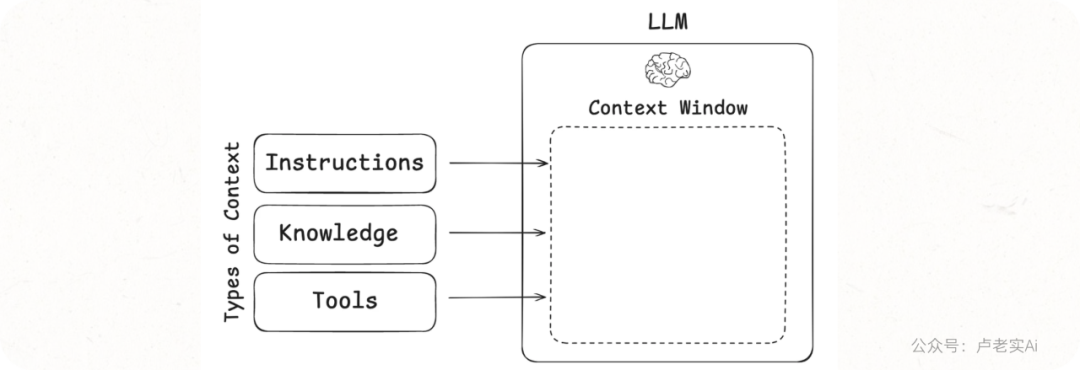
上下文工程作为适用于几种不同上下文类型的总括:
1.Instructions(指令上下文)
- 系统提示词(System Prompts):定义AI的角色、行为准则和响应风格
- 任务指令:具体的任务描述和执行要求
- 少样本示例(Few-shot Examples):输入输出示例,帮助模型理解预期格式
- 工具描述:可用函数/工具的规范和使用说明
- 格式约束:输出格式、结构化要求等
2. Knowledge(知识上下文)
- 领域知识:特定行业或专业的事实性信息
- 记忆系统:用户偏好、历史交互、会话历史
- 检索增强生成(RAG):从向量数据库或知识库检索的相关信息
- 实时数据:当前状态、动态更新的信息
3. Tools(工具上下文)
- 函数调用结果:API响应、数据库查询结果
- 工具执行状态:成功/失败反馈、错误信息
- 多步骤工具链:工具间的依赖关系和数据传递
- 执行历史:之前的工具调用记录和结果

Context Window (上下文窗口):
是指模型输入中最多能够容纳的token数量的限制。
Token可以理解为文本被拆分成的最小单位,可能是一个字、一个词,或者是一个标点符号。例如,Gemin Pro的上下文窗口是100万个token,这意味着它最多能处理100万个token的输入。一旦超过这个限制,前面的内容就会被丢弃,只保留最后的100万个token。
例如:
“ChatGPT”可能会被拆分成 ["Chat", "G", "PT"] 三个 token。
“明天 去 吃饭”,中间的空格也会单独占一个 token。总共有7个token。
容量限制:
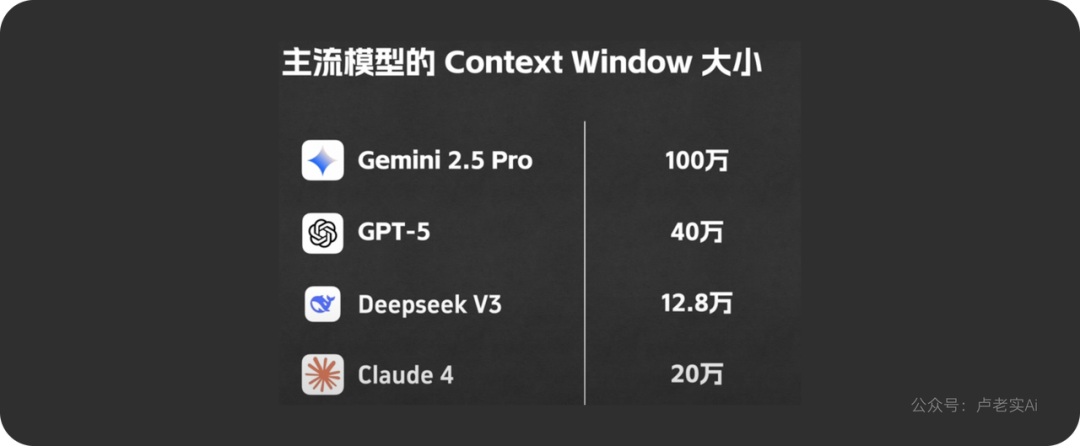
- GPT-3.5 的主流版本确实只有 4K token 上下文窗口(大约 2–3 千个中文字符)。
- Claude 3.5 Sonnet:官方标配 200K token 上下文窗口(约 15 万汉字),可稳定处理几十万字的内容。
- Google 在 2024 年发布时,强调 Gemin2.5 Pro 的上下文窗口可以达到 100 万 token,而且是“实测可用”的,不是纸面数字。100 万 token 大约对应 70–80 万个英文单词,换算成中文差不多能覆盖 整本专业书籍甚至多本论文合集。
什么是 Context Engineering?
之前我们一直在强调prompt engineer**(提示词工程),目标是让模型在既定约束下稳定地产出期望格式与质量的结果,把单步任务**说清楚(角色、目标、格式、约束、示例)。
“如果说 Prompt Engineering(提示词工程) 是“如何问问题”,那么 Context Engineering(语境工程) 更进一步,它关心的是“如何设计问题背后的语境”。”
-
Prompt Engineering:侧重在一句话或一段指令中,如何让模型理解并执行。
-
Context Engineering:不仅是提问,还要设计整个对话、任务或信息流的上下文环境,让模型在“正确的语境”里作答。
直白点说,Prompt 是“单点触发”(需要干啥),Context 是“完整背景”(如何干对干好)。
Prompt(提示):用户一句话——“我想退货。”
这是模型要处理的直接任务,就像指令:识别意图,生成一段回复。
Context(语境):
退货能否成功,取决于系统给模型的更多信息:
用户是谁(新老客户?VIP?黑名单?)
订单详情(买的什么,是否在退货期限内?)
商城规则(此商品是否支持7天无理由?)
历史对话(之前客服有没有答应过用户什么条件?)
如果模型只拿到 Prompt(“我想退货”),它可能机械回答:“请在7天内申请。”
但在 Context 的支持下,它能更聪明地说:“您购买的耳机还在退货期,我已为您提交退货申请,快递员将在2天内上门取件。”
四个核心特征
🔄 动态系统,而非静态模板
复杂AI应用需要整合多源信息:开发者指令、用户输入、历史交互、工具反馈、外部数据。这些信息实时变化,因此构建提示的逻辑必须是动态的,能够根据情况智能组装上下文。
📊 信息质量决定输出质量
“吃什么,拉什么” —— 这是AI领域的铁律
LLM不会读心术。很多智能体表现糟糕的根本原因是缺乏关键信息。你必须提供:
相关性高的背景知识
准确性强的实时数据
完整性好的上下文线索
🛠️ 工具赋能,突破纯文本局限
仅凭文本输入,LLM无法处理复杂的现实任务。正确的工具配置包括:
信息检索接口(搜索、数据库查询)
操作执行能力(API调用、文件处理)
分析计算功能(数据处理、逻辑推理)
💬 格式设计,影响理解效率
与人类沟通一样,怎么说比说什么同样重要:
- 一句清晰的错误提示 > 一堆混乱的JSON数据
- 结构化的工具参数 > 模糊的功能描述
- 渐进式的信息组织 > 信息堆砌
在设计上下文工程时的要求:
✅ 信息充分吗? 是否提供了完成任务的必要信息?
✅ 工具合适吗? 是否具备解决问题的关键能力?
✅ 格式清晰吗? AI能否轻松理解和使用这些资源?
为什么会出现 Context Engineer?
随着上下文窗口越来越长,我们原本以为“把所有对话历史和资料都丢进模型”就能解决记忆问题。但实验表明,现实远比想象复杂。**随着上下文长度增长,模型越来越难保持信息的准确性与一致性,**表现就像“记忆腐烂”。
这些现象在 Chroma 的研究中被称为Context Rot——即模型在长语境下的性能“腐蚀”。这正是 Context Engineer 这一角色诞生的根本原因:需要有人去对抗和修复这种“语境腐烂”,通过裁剪、压缩、重组和检索增强,让模型在有限的注意力资源中保持可靠表现。
在业界常见经常使用 Needle-in-a-Haystack(针堆测试) 对模型上下问能力进行检测。
可以理解为这个实验就是大海捞针,在海量的文章数据中放一部分我们需要的知识内容。
市面上模型几乎能拿到满分,因此很容易让人以为:它们可以在任意长输入下稳定完成任何任务。
但事实是,模型之所以能在“针堆测试”上表现出色,是因为这个测试非常简单,本质上是一个“识别任务”。我们只是把一个随机事实插在长文档的中间,然后让模型找出来。而且,这种设计往往存在词面匹配(lexical match),模型几乎只要做个字符串匹配就能答对,不需要推理或消解歧义。
例如:
问题:我大学同学给我的最佳写作建议是什么?
针( Needle):我大学同学给我的最佳写作建议是 每周都写作。

然而,在实际使用过程中,任务远比这种词面匹配复杂得多。
一旦我们加入一些模糊性(比如问题和 needle 的表述不完全一致),或者放入一些干扰项(distractors),随着输入长度增加,模型性能就会开始显著下降。
以下是Context Rot: How Increasing Input Tokens Impacts LLMPerformance研究中针对上下文的token数对LLM模型输出效果的研究多探讨的几个关键影响生成质量点:
1. 长对话推理困难
模型在面对数十万 tokens 的输入时,并不能像硬盘一样均匀记住所有信息。实验发现,精简版输入(仅几百 tokens)反而比完整输入(十几万 tokens)表现更好。研究结果显示,模型在精简版上的表现显著优于完整版。这说明当输入过长、噪音过多时,即使是最先进的模型,也很难抓住关键信息。
现象还原 想象这样的场景:你在对话初期提到"我现在住在北京",
经过数百轮对话后问"我一会想找个好看的地方看日料"
理想情况下,AI应该给出北京的地点推荐。但一个之前的方法是把完整对话历史(几百条消息)直接塞进 prompt,希望模型自己找。我们实验证明,这在实践中效果并不好,输出经常不可靠。
研究通过LongMemEva基准进行了对比测试:

完整对话版本:约500条对话,总计12万tokens,模型的任务是找到相关的信息并且进行回复
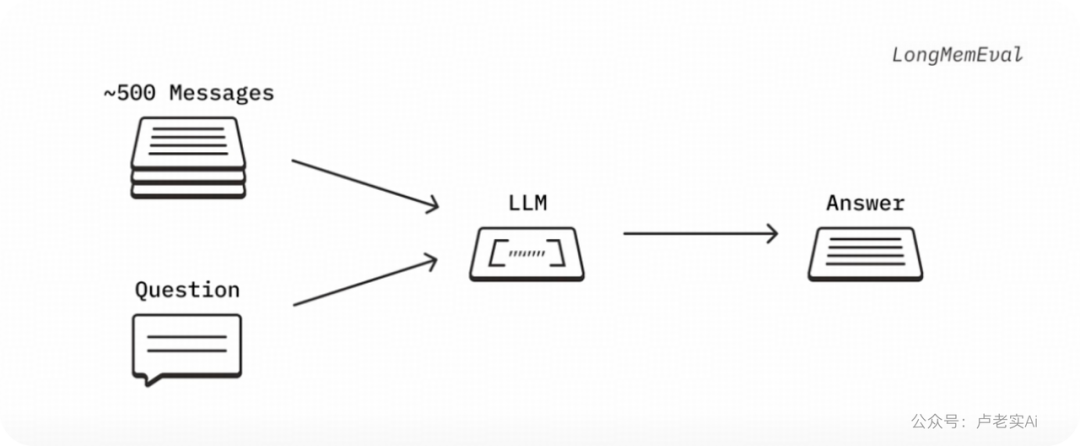
精简关键信息版本:测试关于浓缩版本的信息仅保留相关片段,总计300tokens,对比两者恢复的质量
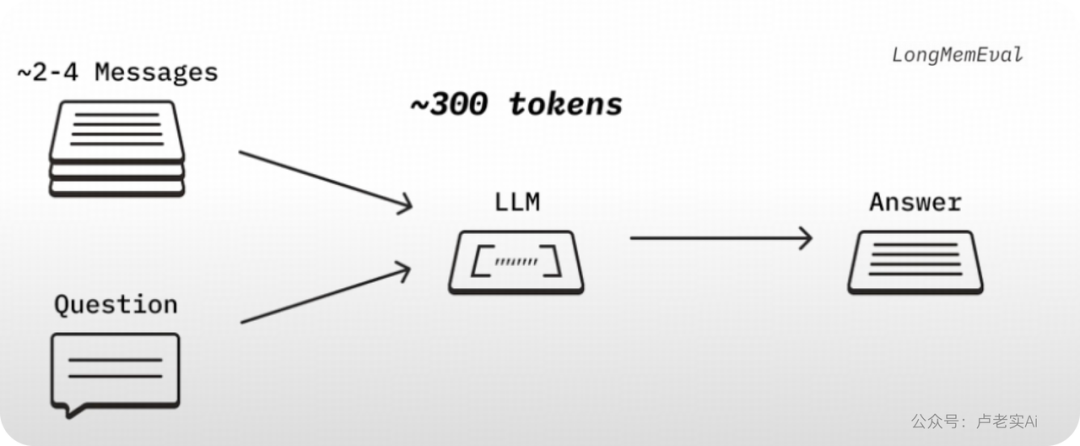
这意味着:如何裁剪和组织上下文,直接决定了模型能否记住关键信息。当输入过于冗长噪声过多时就算是能力比较强的模型表现也一般,模型就像在信息海洋中迷航,难以准确定位关键信息,出现了"记忆衰减"现象。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

2. 长输入的模糊性使挑战更加复杂
“模糊性”(ambiguity)指的是问题(question)和针(needle)之间的对应关系不再直接、明确,而是存在多种可能解释或理解空间。
现实中,当你提示模型修复代码 bug,你通常不会告诉它精确的行号,而是会给一大段上下文代码,让它自己找原因。
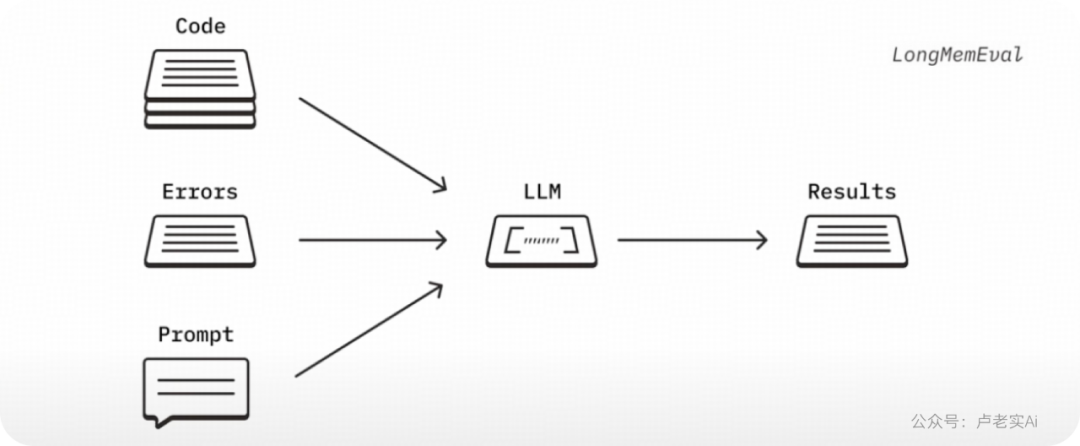
我们改造了“针堆测试”,引入不同程度的模糊性(“High Similarity Needle”“low Similarity Needle”)其实就是干扰项(通过 needle 与问题的余弦相似度来量化)。编写了 8 个与长文本主题相关的“needle”,分析了各种模型在 4 干扰条件下是否尝试失败,不容易被模型简单关键词匹配找到。人工写这些 needle 是为了避免模型在训练时已经见过,保证实验干净。
**原始问题:**我大学同学给我的最佳写作建议是什么?
相似度较高材料(High Similarity Needle):
我大学同学给我的最佳写作建议是每周写一次
模糊的材料(low Similarity Needle):
很少有人知道,我每周坚持写作的习惯是大学时英语课上一位同学推荐的。
-
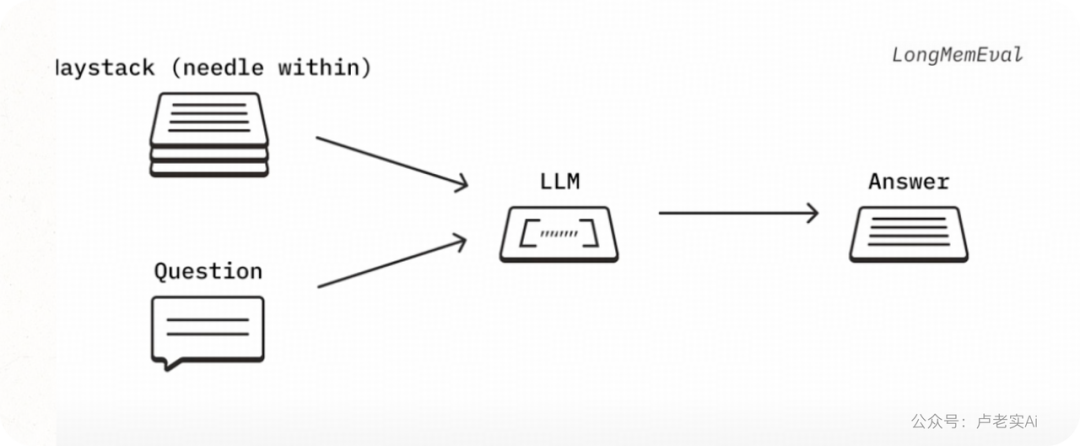
Question 问题:
What was the best writing advice I got from my college classmate?
我从大学同学那里得到的最好的写作建议是什么?
-
High Similarity Needle 高相似度针头:
The best writing advice I got from my college classmate was to write everyweek
我从大学同学那里得到的最好的写作建议是每周写一次。
-
Ambiguous Needle 模糊的针头:
One thing people may not know about me is that I write every week. It’s themost useful habit I’vedeveloped, and it started back in my college days when a random guy in my English corrected it to me
人们可能不知道的是,我每周都会写作。这是我养成的最有用的习惯,它始于大学时期,当时英语课上的一位不认识的同学向我提出了这个建议。
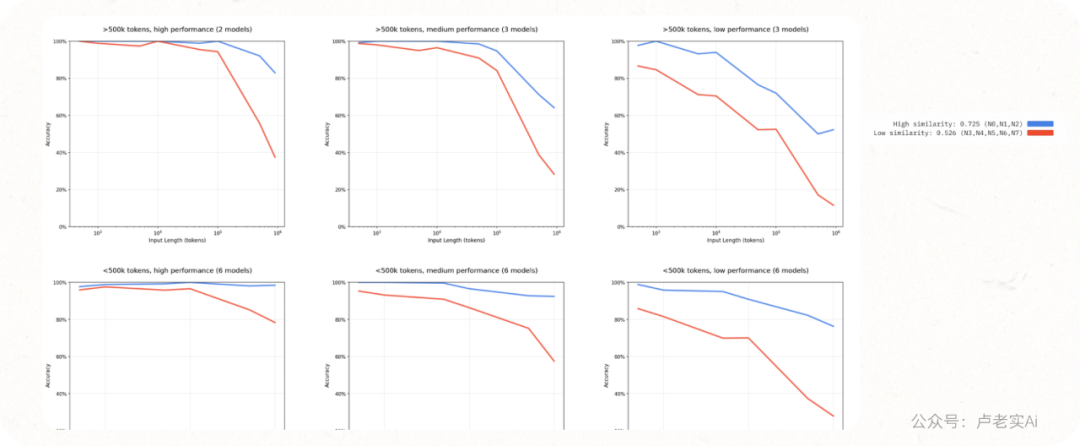
结果发现:
在短输入下,即使 needle 很模糊,模型也能正确回答。
但随着输入变长,模糊性显著加剧性能下降。
这说明模型具备处理歧义的能力,但这种能力在长输入下迅速崩溃。
这告诉我们:在冗长语境下,需要人为帮模型消除歧义,强化关键信号。
3. 干扰项的影响
干扰项(distractors)就是在测试或任务里,看起来跟正确答案很相似,但其实不是真正答案的内容。它们的存在会“干扰”模型,让模型容易选错。
在“长上下文”研究里,干扰项通常是:
语义相关:主题、关键词、句式都跟 needle 很像。
不完全正确:内容部分对齐,但回答的是另一个问题。
真实对话和资料中,往往存在语义相似却不相关的“噪音”。短上下文里模型能区分,但长上下文时更容易被误导。这要求有人来做上下文的筛选与去噪,让模型聚焦真正相关的信息。在长上下文里,模型不光要找到相关信息,还要能分辨“哪个才是正确的 needle,哪个只是干扰项”。
实验中测试的问题是:
Question 问题:
“What was the best writing advice I got from my college classmate?”
我从大学同学那里得到的最好的写作建议是什么?
Needle 针头:
The best writing advice I got from my college classmate was to write every week.
我从大学同学那里得到的最好的写作建议是每周写一篇。
Distactor 分心者:
The best writing advice Igot from my classmate was towrite each essay in threedifferent styles, this wasback in high school.
我从同学那里得到的最好的写作建议是用三种不同的风格写每篇论文,这是在高中时学到的。
蓝线是没有干扰项,黄线是有1个干扰项,红色是有4个干扰项
以下是不同模型的最终结果,从图上可知随着干扰项的增加随着字数的增加准确度逐步递减。
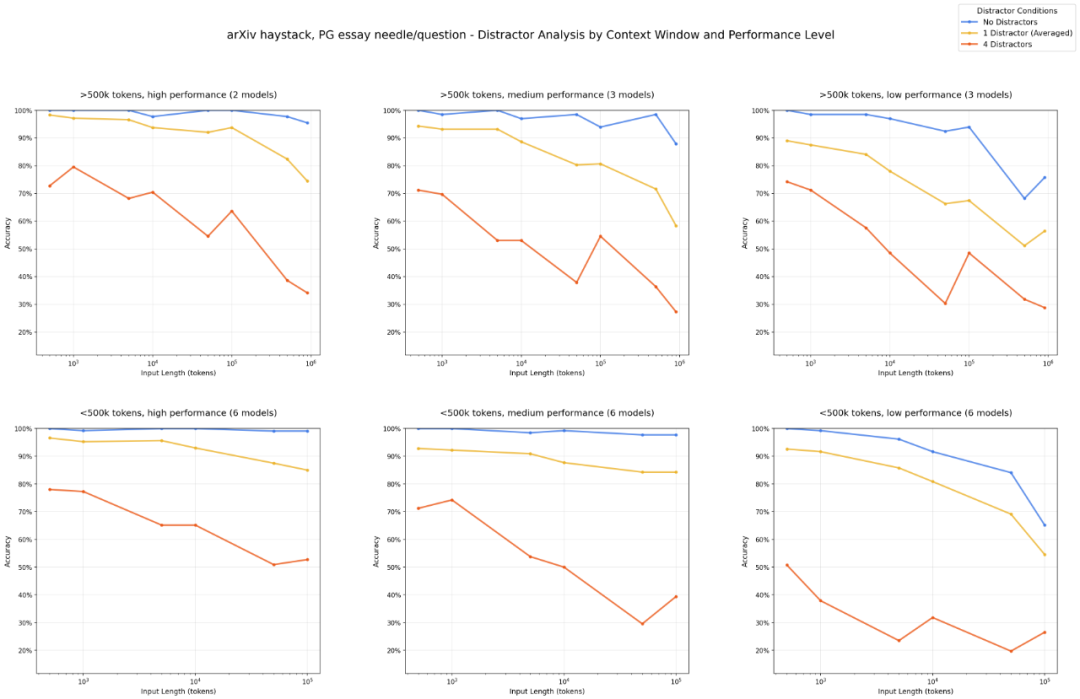
结果证明:
在短输入下,模型可以区分 needle 与干扰项。
输入越长,性能下降越明显。
4. 缺乏“计算机式”可靠性
我们希望LLM获得一致质量的输出 即使是最简单的复制任务,模型在长输入下也会出错。它不是逐字逐位的符号处理器,而是概率驱动的语言生成器。因此不能期望它像数据库或计算机一样精确地处理长上下文,而必须借助结构化设计来弥补。
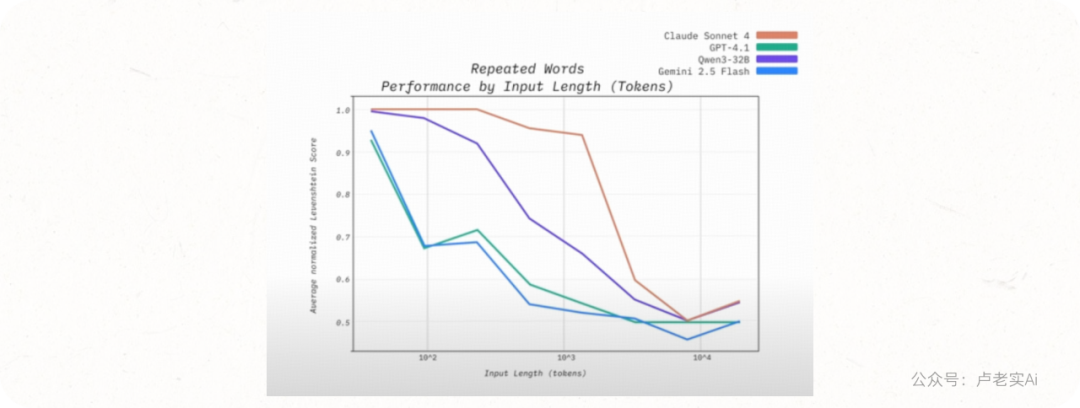
让模型重复一段字符串列表,并在某个特定位置插入一个独特单词。理论上,这只是机械复制任务,应该百分百正确。

结果发现:
当列表长度达到 500 词时,模型的表现开始下滑,常常会多写、漏写,甚至输出随机内容。这证明模型并不是“均匀处理上下文”的计算系统。
总结:
即使你的模型拥有 100 万 token 的上下文窗口,这也不意味着它能在 100 万 token 下稳定工作。即便是当前最顶尖的模型,在长输入中处理简单任务时仍会掉链子。
因此,有效的上下文窗口管理和语境工程是必不可少的。
怎么实施 Context Engineer?
上下文工程(Context Engineering),正是为了解决这个问题的一整套方法论。它核心分为四个环节:写(Write)→ 选(Select)→ 压(Compress)→ 隔(Isolate)。下面我们逐一拆解。
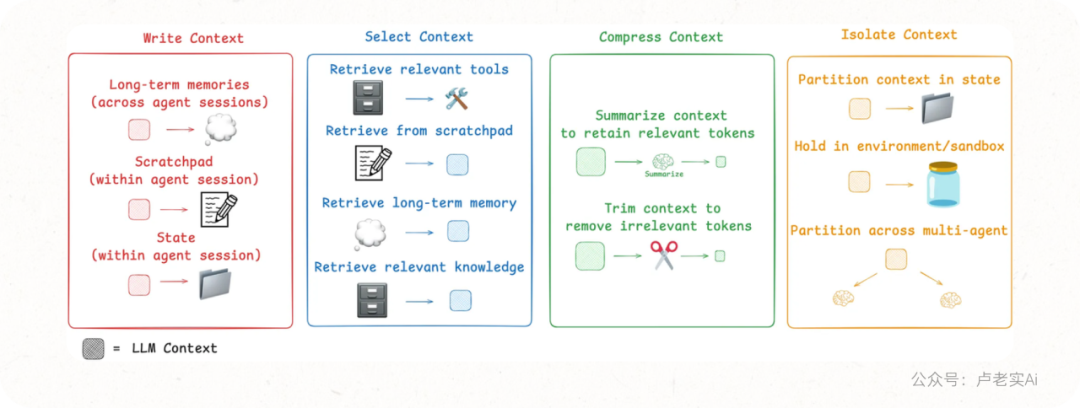
1.Write Context 写入上下文
写入上下文意味着把信息明确记录下来,而不是依赖模型的“即时记忆”。在复杂的任务中,Agent 需要不断产生中间结果、推理路径、状态信息,如果不把这些内容写入持久化的存储,就会在后续步骤中遗失,造成逻辑断裂。
1.1 Scratchpads 便签本
当人类解决任务时,一个临时的工作区,记录模型的中间推理,让思考过程可见。例如在代码生成时,模型会先在 scratchpad 上写出逻辑推理,再据此生成 SQL 或函数。
Anthropic 的多智能体研究人员举了一个明显的例子:
LeadResearcher 的 Agent,它需要带领团队探索某个研究方向。它在思考“下一步计划”时,会把计划写入内存(memory)。这样一来,即使上下文窗口后来被截断,Agent 仍然能通过 memory 找回原本的计划。
1.2 Memories 记忆
将跨对话的重要事实、用户信息和环境状态保留下来,以便后续复用。
Agent 不只是被动存储信息,而是像人类一样,在每次行动后主动反思,把经历转化为“抽象记忆”,并在未来的任务中反复使用。这样它就能在长期交互中表现出连续性和成长性。
Agent 会把新发生的上下文(new context)与已有的记忆(existing memories)结合,经过处理后写成更新的记忆(updated memory),这样它就能在未来的任务中调用“更完整、更抽象的知识”,而不是零散片段。
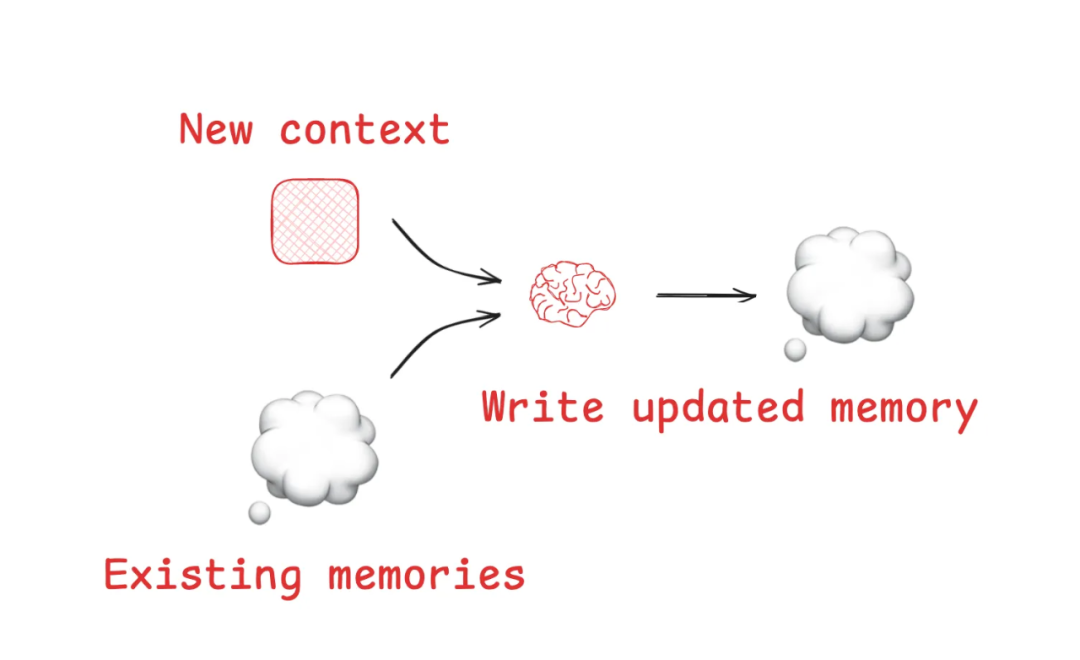
LLM 可用于更新或创建记忆,这些概念进入了 **ChatGPT、**Cursor 和 Windsurf 等流行产品中,这些产品都具有自动生成长期记忆的机制,这些记忆可以根据用户与Agent的交互在会话中持续存在。长期记忆机制已经落地在主流产品中,它让 Agent 不再是“一问一答的临时工”,而是能在持续交互中逐渐了解用户、形成上下文积累的“长期助手”。
2.Select Context 选择上下文
当信息量越来越大时,如何选择比如何存储更重要。选择上下文就是在每次调用模型时,从所有可用的信息源里,挑出真正相关的部分放入窗口。
2.1 Scratchpad 便签本
从暂存器中选择上下文的机制取决于暂存器的实现方式。如果它是一个工具,那么Agent可以通过进行工具调用来简单地读取它。如果它是Agent运行时状态的一部分,则开发人员可以选择在每个步骤中向Agent公开哪些状态部分。这为在以后的回合中向 LLM 公开暂存器上下文提供了细粒度的控制级别。
2.2 Memories 记忆
即使 Agent 有了长期记忆,它也不能把所有记忆一次性都塞进上下文窗口(会超载、也会让模型困惑)。 所以它必须 像人一样主动筛选,只带上和当前任务相关的那部分记忆。
-
语义记忆 (Semantic)
选择事实知识作为任务的背景。“医生看病时,会调用自己记得的人体生理知识。”
-
情景记忆 (Episodic)
选择过去的相似经历,作为行为的“示范案例”。“学生做题时,会想起自己以前做过的类似题目。”
-
程序记忆 (Procedural)
选择操作规则或执行指令,用来引导行为。“人类开车时不需要重新学习“踩刹车”,而是直接调用程序性技能。”
在电商客服场景中,用户问“订单为什么还没到”,Agent 只需要选择订单记录和物流政策作为上下文,而不必把全部 FAQ 或促销活动一起输入。通过这种精确的选择,模型的注意力被锁定在最关键的信息上,从而给出更聚焦的回答。
| 记忆类型 (Memory Type) | 存储内容 (What is Stored) | 人类示例 (Human Example) | 智能体示例 (Agent Example) |
| 语义记忆 (Semantic) | 事实 (Facts) | 我在学校学到的知识 | 关于用户的事实信息 |
| 情景记忆 (Episodic) | 经历 (Experiences) | 我做过的事情 | 智能体过去的行为 |
| 程序性记忆 (Procedural) | 指令 (Instructions) | 本能或运动技能 | 智能体的系统提示 (system prompt) |
2.3 如何确保选取的记忆真的是相关的,而不是“乱选”或“越界”呢?
许多早期的 Agent 采取了简化的策略:它们并不真的从大量信息中动态筛选,而是固定从一组狭窄的文件里拉取上下文。
例如,不少代码 Agent 会把指令放在一个专门的文件中(这就是“程序性记忆”),Claude Code 使用 CLAUDE.md,Cursor 和 Windsurf 则依赖规则文件。在某些情况下,它们也会附带几个示例,作为“情景记忆”的简化版本。
这种做法简单,但局限明显:
随着 Agent 开始存储更多事实与关系(也就是语义记忆),选择的难度指数级增加。ChatGPT 是一个突出的例子:它能够保存大量用户特定的记忆,并在任务中进行选择。为了解决“选什么”的问题,产品通常引入嵌入索引或知识图谱,作为辅助检索机制。
即便如此,记忆选择仍然容易出错。
在一次公开分享中,Simon Willison 就展示了一个令人尴尬的案例:ChatGPT 自动从记忆中取出他的位置信息,并意外注入到图像生成的提示词里。这种“未预期的记忆注入”,会让用户觉得上下文窗口仿佛不再完全受控,甚至带来隐私上的担忧。
Tools 工具
过滤掉多余的返回,只保留必要数据。
在 Agent 系统里,工具本身就是一种上下文。当模型调用 API、插件或外部函数时,它必须理解工具的描述,并在合适的场景下选择正确的工具。问题在于,如果给 Agent 提供的工具太多、描述彼此重叠,就会让模型陷入“工具过载”:它不知道该用哪个,甚至可能错误调用。
为了解决这一问题,一种有效方法是将 RAG(Retrieval-Augmented Generation,检索增强生成) 用于工具描述的选择:
- 不再把所有工具内容一次性丢给模型;
- 而是先用检索机制筛选出与当前任务最相关的少量工具,再交给模型使用。
研究表明,这样的做法能显著提升工具选择的准确性——部分最新论文显示,准确率甚至可以提升 3 倍。
把工具当作上下文来处理,是现代 Agent 工程的重要课题:如果不加选择,工具多到让模型迷失,就会导致执行效率低下;如果应用 RAG,对工具进行检索和过滤,就能极大提升选择准确率。
尤其在代码场景中,RAG 并不是“嵌入搜索万能药”。它需要结合 AST 分块、知识图谱检索、传统搜索、重新排序等手段,才能真正解决大规模代码库下的上下文选择问题。
换句话说:RAG 不是终点,而是一个需要系统设计与多层次补充的工程方案。
3.Compressing Context 压缩上下文
在真实应用中,Agent 的交互可能跨越数百个回合,同时还会调用大量 token 密集型工具(例如代码搜索、数据库查询、长文档解析)。如果把这些内容原封不动放进上下文窗口,不仅会迅速耗尽 token,还会让模型难以聚焦。
压缩上下文(Compressing Context) 就是解决这个问题的核心方法。它的基本思路是:对长对话或冗长的工具输出,进行摘要(summarization)或修剪(trimming),用更短的信息替代原始内容。
在 LangGraph 的设计中,还特别支持将 状态(state)压缩后再写入,从而减少 token 占用,同时保持任务的完整性。
3.1 Context Summarization 上下文摘要
Agent交互可以跨越数百个回合,并使用token密集型工具调用。摘要是管理这些挑战的一种常见方法。如果您使用过 Claude Code,您就会看到这一点。Claude Code 在您超过 95% 的上下文窗口后运行“ 自动压缩 ”,它将总结用户与Agent交互的完整轨迹。这种跨Agent轨迹的压缩可以使用各种策略,例如递归或分层摘要。
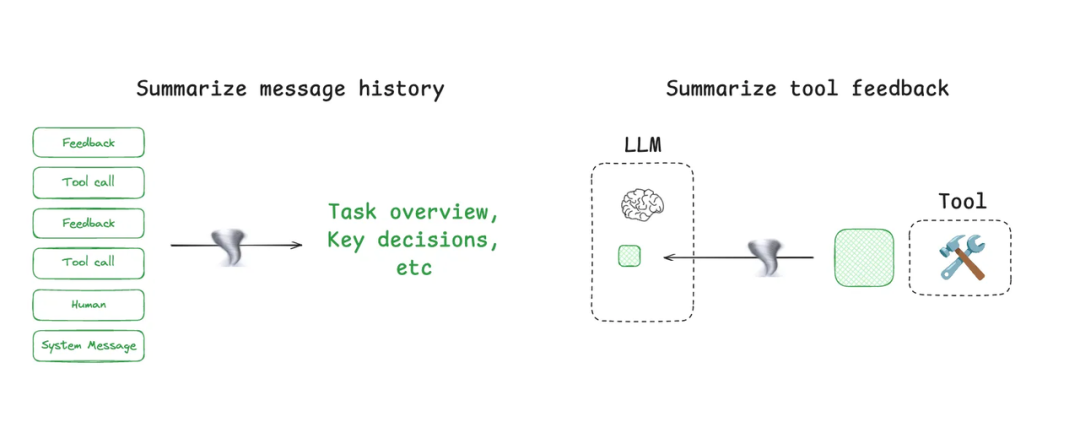
压缩上下文的两大核心策略:
-
对话摘要:管理长时间的多轮交互。
-
工具摘要:管理冗长的外部调用结果。
二者的目标一致:减少 token 占用,保留关键上下文,让 LLM 聚焦在真正重要的信息上。
可以应用摘要的几个地方。除了对长对话和工具输出做整体压缩之外,摘要还可以插入到 Agent 流程的特定节点,帮助系统更高效地传递信息。
a. 工具调用后的后处理
有些工具本身返回的信息极其庞大,比如搜索引擎、代码搜索、文档检索。
如果直接把这些结果交给模型,不仅浪费 token,还可能让模型分心。
在调用完成后做一次“摘要”,只保留与任务相关的关键信息,可以显著降低负担。
b. Agent-Agent 边界的知识交接
在多 Agent 协作场景里,不同 Agent 需要传递信息。
Cognition 的实践提到:在 Agent 之间交接时,先做摘要,再传递,可以减少 token 占用。
相当于把“原始记录”精简成“交接笔记”,既高效又避免上下文污染。
c. 特定事件或决策的捕捉
有时我们并不是要压缩所有信息,而是只想捕捉某些关键事件或决策。
这类摘要往往比“通用总结”更难,因为要有选择性地保留对未来有影响的细节。
Cognition 的做法是使用一个 微调模型(fine-tuned model) 来生成这类定制化摘要,保证准确性。
3.2 Context Trimming 上下文修剪
摘要通常使用 LLM 来提炼最相关的上下文片段,而修剪通常可以过滤,或者正如 Drew Breunig 指出的那样,“ 修剪 ”上下文。
启发式修剪(Heuristic Trimming)
Drew Breunig 的观点是:修剪有时比摘要更直接、成本更低。
例如在聊天场景中,可以简单规定:
只保留最近 10 条消息;
或只保留包含关键字的消息,其余删除。
这种方式虽然粗糙,但能避免 token 膨胀。
摘要是“提炼”,修剪是“裁剪”。 摘要需要 LLM 来生成浓缩内容,而修剪通常用规则或专门模型来删除不必要的上下文。两者常常配合使用:先修剪掉最没用的部分,再对剩余的内容做摘要。
4. Isolating Context 隔离上下文
在复杂任务中,如果把所有信息都塞进一个 Agent 的上下文窗口,很容易造成冲突、过载和混乱。隔离上下文的目标,就是通过“分区管理”,让不同类型的信息保持边界清晰。这样不仅能避免信息干扰,还能让系统结构更清晰。
4.1 Multi-agent 多智能体
隔离上下文最常见的方式就是 多智能体架构。
代表性实践是 OpenAI 的 Swarm 库:它的设计动机是关注点分离,把大任务拆成子任务,每个子 Agent 各自处理。
每个子 Agent 拥有:一组特定的工具、自己的系统说明(instructions)、独立的上下文窗口
Anthropic 的研究也支持这一点:当智能体被拆分成多个子代理,每个子代理只处理自己专属的窄任务时,整体性能往往优于“一个大而全的单智能体”。
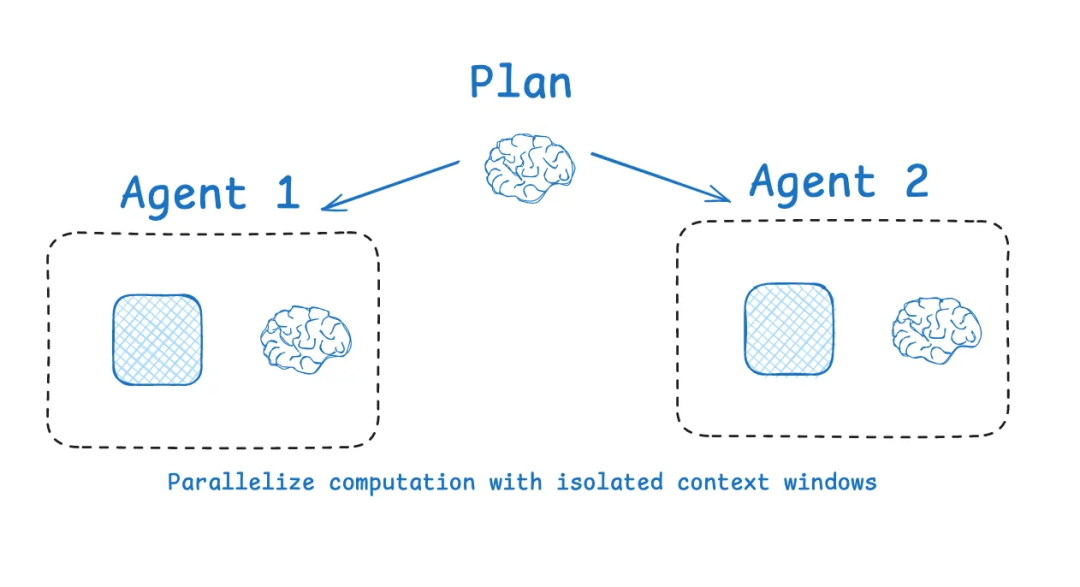
他们在博客里写道:
子代理在各自独立的上下文窗口中并行运行,同时探索问题的不同方面。
这就像一个团队开会时,每个人只带自己相关的笔记,而不是所有人都要读完整个文件夹。
不过,多 Agent 架构也带来挑战:
token 成本增加:Anthropic 报告显示,多代理模式下的 token 使用可能比单 Agent 多出 15 倍。
提示工程复杂:需要设计好每个子 Agent 的分工和指令。
协调难度:子 Agent 的结果必须由调度者整合,否则会各说各话。
4.2 Context Isolation with Environments 与环境的上下文隔离
HuggingFace 的深入研究者展示了上下文隔离的另一个有趣的例子。大多数代理使用工具调用 API,它返回 JSON 对象(工具参数),这些对象可以传递给工具(例如搜索 API)以获取工具反馈(例如搜索结果)。
Hugging Face 的研究团队给出了一个典型案例:CodeAgent。
流程是:
LLM 生成工具调用(例如调用一个搜索 API),以 JSON 形式描述参数。
这些调用被送入工具,在一个 沙盒环境 中执行。
工具执行结果(例如搜索结果)再被挑选后传回给 LLM。
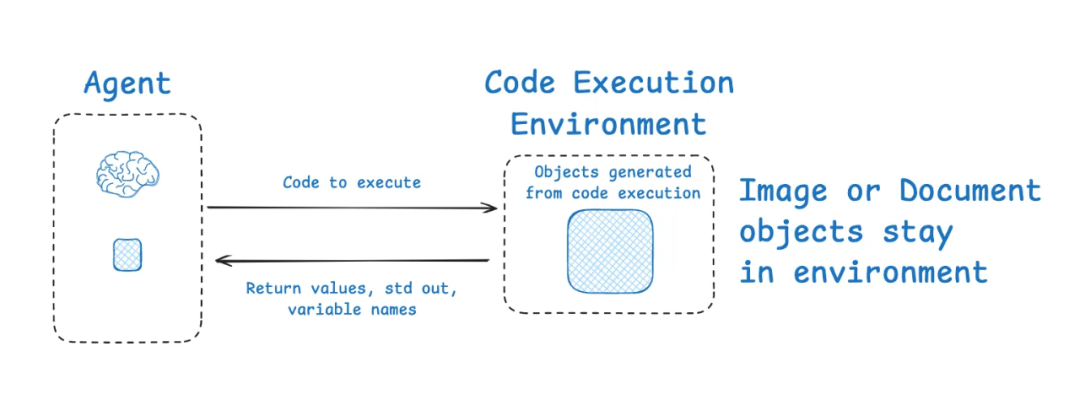
这种方式的关键是:执行环境和 LLM 上下文隔离。
LLM 不需要直接接触所有工具输出,而是只接收处理过的结果。
Hugging Face 指出,这种方法尤其适合处理 token 密集型对象(比如庞大的 JSON、长代码输出),因为它们先在沙盒中“隔离”,然后只把必要内容带回主上下文。
隔离上下文就是给不同的信息设置“边界”和“专属空间”。无论是子 Agent 分工,还是工具沙盒执行,都是在避免上下文混乱,让每个环节的信息干净、可控。
总结:
上下文工程的四个动作——写、选、压、隔——并不是零散的技巧,而是一套系统方法。它们分别解决了信息丢失、信息冗余、信息过载和信息冲突的问题。
当这四个策略被系统化执行,Agent 就能在复杂环境中稳定运行,从“看似聪明的 demo”成长为“可靠的企业级系统”。这不仅仅是 prompt 的升级,而是大模型应用走向工程化的必经之路。
综述
“上下文工程是一种观念,而不是单一技术”
上下文工程(Context Engineering)并不是某一项具体的技术实现,它更像是一种贯穿整个 Agent 设计与开发的思想和方法论。它背后折射的是技术圈,尤其是一线工程师们,对未来 AI 系统架构趋势的判断。
正如 Dex Horthy 所说:
“Even as models support longer and longer context windows, you’ll ALWAYS get better results with a small, focused prompt and context.”**“即使模型支持越来越长的上下文窗口,你仍然总是能用小而聚焦的提示与上下文获得更好的结果。”
“长上下文 ≠ 终极答案”
大模型的长上下文窗口确实缓解了很多开发难题:
你不必频繁丢弃信息;也可以在更长的对话中保持上下文。
但这远不是解决方案的全部。上下文工程提出的核心观点就是:我们不应该单纯追求窗口更长,而应该追求上下文管理更聪明。
真正理想的系统,是能够在发送给 LLM 的上下文里:
不多不少,恰到好处;
既不过载模型,也不遗漏关键信息。
“RAG 的新生命”
在这一点上,RAG(检索增强生成)技术也并未过时,反而将在上下文工程的框架下迎来“第二春”。
如果说 LLM 是强大的推理引擎,那么 AI 应用开发的本质,就是在海量信息中找到最合适的一小部分,并将其适配进上下文窗口。
这个过程就像一个信息漏斗:
检索:从海量数据中找到候选信息;
过滤:剔除冗余或无关内容;
排序:把最相关的部分优先送进上下文。
上下文工程提供的正是这套完整的“信息筛选与注入机制”。
“微妙的艺术与科学”
因此,Context Engineering 既是一门工程技术,也是一门微妙的艺术。它要求我们在复杂的信息洪流中,精准决定:
哪些信息该写入(Write);
哪些信息需要选择(Select);
哪些必须压缩(Compress);
哪些应该隔离(Isolate)。
正如 LangChain 博客中所总结的:
**“Context engineering is the delicate art and science of filling the context window with just the right information for the next step.”**上下文工程,是用恰到好处的信息填充上下文窗口的微妙艺术与科学,让智能体能走好下一步。
大模型未来如何发展?普通人能从中受益吗?
在科技日新月异的今天,大模型已经展现出了令人瞩目的能力,从编写代码到医疗诊断,再到自动驾驶,它们的应用领域日益广泛。那么,未来大模型将如何发展?普通人又能从中获得哪些益处呢?
通用人工智能(AGI)的曙光:未来,我们可能会见证通用人工智能(AGI)的出现,这是一种能够像人类一样思考的超级模型。它们有可能帮助人类解决气候变化、癌症等全球性难题。这样的发展将极大地推动科技进步,改善人类生活。
个人专属大模型的崛起:想象一下,未来的某一天,每个人的手机里都可能拥有一个私人AI助手。这个助手了解你的喜好,记得你的日程,甚至能模仿你的语气写邮件、回微信。这样的个性化服务将使我们的生活变得更加便捷。
脑机接口与大模型的融合:脑机接口技术的发展,使得大模型与人类的思维直接连接成为可能。未来,你可能只需戴上头盔,心中想到写一篇工作总结”,大模型就能将文字直接投影到屏幕上,实现真正的心想事成。
大模型的多领域应用:大模型就像一个超级智能的多面手,在各个领域都展现出了巨大的潜力和价值。随着技术的不断发展,相信未来大模型还会给我们带来更多的惊喜。赶紧把这篇文章分享给身边的朋友,一起感受大模型的魅力吧!
那么,如何学习AI大模型?
在一线互联网企业工作十余年里,我指导过不少同行后辈,帮助他们得到了学习和成长。我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑。因此,我坚持整理和分享各种AI大模型资料,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频。
学习阶段包括:
1.大模型系统设计
从大模型系统设计入手,讲解大模型的主要方法。包括模型架构、训练过程、优化策略等,让读者对大模型有一个全面的认识。

2.大模型提示词工程
通过大模型提示词工程,从Prompts角度入手,更好发挥模型的作用。包括提示词的构造、优化、应用等,让读者学会如何更好地利用大模型。

3.大模型平台应用开发
借助阿里云PAI平台,构建电商领域虚拟试衣系统。从需求分析、方案设计、到具体实现,详细讲解如何利用大模型构建实际应用。

4.大模型知识库应用开发
以LangChain框架为例,构建物流行业咨询智能问答系统。包括知识库的构建、问答系统的设计、到实际应用,让读者了解如何利用大模型构建智能问答系统。
5.大模型微调开发
借助以大健康、新零售、新媒体领域,构建适合当前领域的大模型。包括微调的方法、技巧、到实际应用,让读者学会如何针对特定领域进行大模型的微调。


6.SD多模态大模型
以SD多模态大模型为主,搭建文生图小程序案例。从模型选择、到小程序的设计、到实际应用,让读者了解如何利用大模型构建多模态应用。
7.大模型平台应用与开发
通过星火大模型、文心大模型等成熟大模型,构建大模型行业应用。包括行业需求分析、方案设计、到实际应用,让读者了解如何利用大模型构建行业应用。


学成之后的收获👈
• 全栈工程实现能力:通过学习,你将掌握从前端到后端,从产品经理到设计,再到数据分析等一系列技能,实现全方位的技术提升。
• 解决实际项目需求:在大数据时代,企业和机构面临海量数据处理的需求。掌握大模型应用开发技能,将使你能够更准确地分析数据,更有效地做出决策,更好地应对各种实际项目挑战。
• AI应用开发实战技能:你将学习如何基于大模型和企业数据开发AI应用,包括理论掌握、GPU算力运用、硬件知识、LangChain开发框架应用,以及项目实战经验。此外,你还将学会如何进行Fine-tuning垂直训练大模型,包括数据准备、数据蒸馏和大模型部署等一站式技能。
• 提升编码能力:大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握将提升你的编码能力和分析能力,使你能够编写更高质量的代码。
学习资源📚
- AI大模型学习路线图:为你提供清晰的学习路径,助你系统地掌握AI大模型知识。
- 100套AI大模型商业化落地方案:学习如何将AI大模型技术应用于实际商业场景,实现技术的商业化价值。
- 100集大模型视频教程:通过视频教程,你将更直观地学习大模型的技术细节和应用方法。
- 200本大模型PDF书籍:丰富的书籍资源,供你深入阅读和研究,拓宽你的知识视野。
- LLM面试题合集:准备面试,了解大模型领域的常见问题,提升你的面试通过率。
- AI产品经理资源合集:为你提供AI产品经理的实用资源,帮助你更好地管理和推广AI产品。
👉获取方式: 😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】

更多推荐
 11
11 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)