




- @kaka0722ww
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Function Calling / Tool Use 不是模型自己去执行工具,而是模型先输出“该怎么调用”的结构化请求,外部程序替它执行,再把结果送回模型完成闭环。模型决定要不要调、调哪个、参数怎么填;系统决定能不能调、怎么调、结果怎么回;两者合起来,才构成一个真正能“做事”的 Agent。
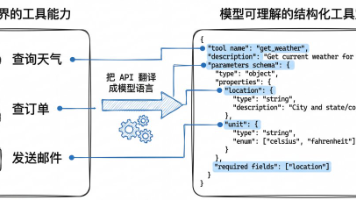
Function Calling / Tool Use 不是模型自己去执行工具,而是模型先输出“该怎么调用”的结构化请求,外部程序替它执行,再把结果送回模型完成闭环。模型决定要不要调、调哪个、参数怎么填;系统决定能不能调、怎么调、结果怎么回;两者合起来,才构成一个真正能“做事”的 Agent。
2025年AI智能体开发全景指南:10个GitHub精选教程助你从入门到精通
AI Agent(AI智能体)是基于大模型构建的自主执行系统,核心能力包括目标理解、任务规划、工具调用与动态反馈,相当于“能自主思考的数字员工”。大模型:充当“大脑”,如OpenAI的o3模型通过测试时计算优化推理效率;主动规划:可以将大型任务分解为子任务,并规划执行任务的流程,同时能够对任务执行的过程进行思考和反思,从而决定是继续执行任务,或判断任务完结并终止运行;记忆:短期记忆存储任务上下文,
Edward Donner开发的8周LLM工程师训练营,面向工程实践的大语言模型开发指南。涵盖从开发环境配置到部署的完整工程化流程,注重实战技能培养和最佳实践传授。这十个GitHub仓库构成了AI智能体技术栈的完整生态系统,从理论基础到工程实践,从开发工具到部署运维,为不同背景的开发者提供了系统性的学习路径。
本文分享了Java程序员从传统后端开发转向AI应用开发的实战经验,揭示了AI应用开发并非简单的API调用,而是涉及系统工程,包括文档解析、切分策略、检索方案、精排调优、Agent设计、MCP集成等复杂环节。文章强调Java程序员的工程化能力在这一领域具有优势,并计划后续深入探讨RAG、Agent、Java AI开发及AI编程提效等实战内容,适合对AI应用开发感兴趣的小白和程序员学习。大家好。写了8
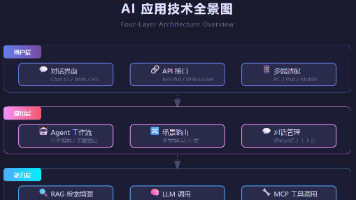
现状:AI Agent 已经从实验性概念进入生产部署阶段,72% 的企业至少在一个业务流程中部署了 Agent。类型:Browser Agent、Coding Agent、Multi-Agent Team 三种类型各有优势,分别占据自动化、开发和复杂协作的场景。技术:ReAct 范式、工具调用、记忆系统构成 Agent 的技术三角,让它真正具备感知-推理-行动-学习的闭环能力。生态:A2A(Age
现状:AI Agent 已经从实验性概念进入生产部署阶段,72% 的企业至少在一个业务流程中部署了 Agent。类型:Browser Agent、Coding Agent、Multi-Agent Team 三种类型各有优势,分别占据自动化、开发和复杂协作的场景。技术:ReAct 范式、工具调用、记忆系统构成 Agent 的技术三角,让它真正具备感知-推理-行动-学习的闭环能力。生态:A2A(Age
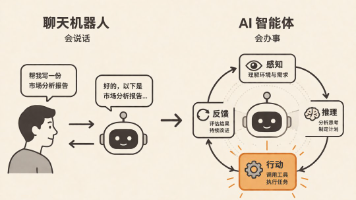
AI Agent(智能体)并非简单的人机对话程序,而是一套具备自主感知、任务规划、工具调用、记忆存储、迭代执行、结果复盘能力的智能化自主系统。其本质可以概括为:AI Agent = LLM大模型 + 记忆系统 + 任务规划引擎 + 工具调用编排 + 人机交互闭环传统的 AI 应用核心逻辑在于“被动响应”,用户输入指令、模型返回结果;而 AI Agent 的核心逻辑是“主动执行”,接收用户目标后,它

AI Agent(智能体)并非简单的人机对话程序,而是一套具备自主感知、任务规划、工具调用、记忆存储、迭代执行、结果复盘能力的智能化自主系统。其本质可以概括为:AI Agent = LLM大模型 + 记忆系统 + 任务规划引擎 + 工具调用编排 + 人机交互闭环传统的 AI 应用核心逻辑在于“被动响应”,用户输入指令、模型返回结果;而 AI Agent 的核心逻辑是“主动执行”,接收用户目标后,它