登录社区云,与社区用户共同成长
邀请您加入社区
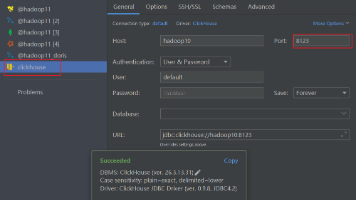
ClickHouse是一款开源列式存储OLAP数据库,专为海量数据分析设计,相比MySQL等行式数据库在聚合查询、实时报表等场景性能优势显著。本文为零基础用户提供ClickHouse一站式入门指南,涵盖核心概念、Linux原生部署和实战SQL操作。重点解析OLAP与OLTP的区别、列式存储原理,详细演示CentOS/Ubuntu系统安装配置(含远程连接、密码设置等生产级部署技巧),并通过用户行为分
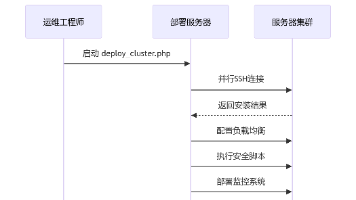
上一篇完整落地企业内网标准化 Docker 底座,统一引擎、Harbor 镜像仓库、分层持久化存储。日常业务包含用户、订单、支付三套微服务,搭配 MySQL、Redis、Nginx 中间件,需要频繁搭建、销毁测试 / 客户演示环境。如果纯手写docker run,会出现配置零散、端口密码硬编码、启停顺序混乱、日志难以统一检索等痛点。
相较于YOLOv8等前代模型,YOLOv11更适配SE110S边缘设备:推理速度提升15%-30%、模型体积更小、算子更规整,完美支持FP32/FP16/INT8多精度量化推理,INT8量化后可最大化发挥TPU算力,满足多路视频实时检测需求。:采用优化的C3k轻量化模块,替代前代C2f结构,精简冗余卷积分支,搭配SPPF空间金字塔池化,在降低算力消耗的同时,保留多尺度特征提取能力,适配SE110S
发邮件至:qq202_ezczjjz6va@aka.yeah.net。备注:飞秒云额度申请 + 注册用户名,定时审核发放。公测名额有限,适合个人开发、日常调用,抓紧入驻。充值满10元,额外追加20刀永久额度。
搭建本站点初衷是降低大模型使用门槛,让所有人都能零成本用上优质AI接口。
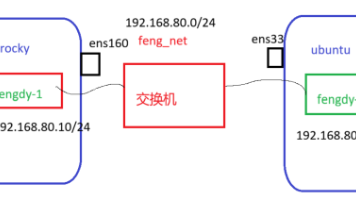
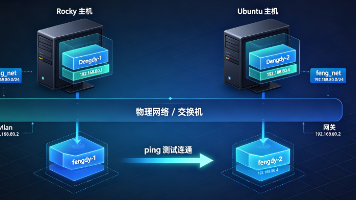
本文介绍了在Ubuntu和Rocky Linux系统中创建IPvlan网络并实现容器互联的方法
新建一个docker-compose.yml配置文件,并复制下面的配置参数到docker-compose.yml中保存。(任选一处路径存放)通过cmd进入到docker-compose.yml 所在路径下,输入下列命令,完成镜像和容器的下载与配置。crawlab的web登录页的默认账号:admin,密码:admin。(注:需要在梯子环境下下载)
Docker+Zipkin+Elasticsearch+Kibana部署分布式链路追踪
各位小伙伴,有没有遇到过这种头疼的情况:家里买的智能设备越来越多,小米、vivo、Yeelight、美的……各个品牌都有自己的 App,结果就是手机里装了十几个应用,每个设备一个入口,想开一下灯要切到米家,想关窗帘又得切到美的,连做个自动化联动都困难重重。
项目地址:https://github.com/czfshine/docker-hadoopdocker-hadoopA dockerfile for setting up a full Hadoop cluster server一套在ubuntu 下生成和部署Hadoop的Docker镜像的配置文件集与示例。包括:环境配置文件生成 docker image 的dockerfi...
Rocky、Ubuntu通过IPvlan搭建同网段容器,实现跨主机互通
最近安装了一下Browserless 与Playwright,并且对接上AI智能体,发现就可以处理一些以往无法直接自动化处理的事情,比如网页数据抓取等等。本篇博客就介绍一下关于这两种工具在ddocker中的安装方法,让你的AI智能体如虎添翼。
本文所提及的各类智能运维平台相关信息(包括但不限于产品功能、适配场景、市场反馈、行业适配性等),均基于公开市场披露资料、权威行业调研报告及网络公开可查的用户评价等客观信息整理而成,仅为向企业提供选型参考维度,不构成对任何品牌、产品的官方背书、性能承诺或购买建议,亦不代表我方对相关产品的主观评价。CPack深度适配鲲鹏、飞腾等国产芯片,以及银河麒麟、统信UOS等操作系统,在数据库层面兼容TDSQL、
本文介绍了使用Docker和Kubernetes部署Python Web应用的优势和方法。传统部署方式存在环境不一致、效率低、运维成本高等问题,而云原生技术通过容器化和编排能实现环境统一、自动化运维和快速扩缩容。文章详细讲解了将Python应用打包为Docker镜像的步骤,以及Kubernetes提供的自愈、弹性扩缩容等企业级功能。实践表明,该方案可节省80%-95%运维时间,显著提升部署效率和系
本文详细介绍了如何利用vLLM框架高效部署Qwen2.5-32B大模型,实现企业级数据分类分级任务。主要内容包括: 关键技术解析 vLLM框架特性:支持高并发、多卡推理、量化模型和长文本处理 Qwen32B模型优势:320亿参数规模在准确率和部署成本间取得平衡 量化技术对比:AWQ和GPTQ的性能差异及适用场景 多卡部署要点:张量并行配置和NCCL通信优化 生产部署方案 硬件选型建议:根据不同场景
本文介绍了使用Docker三阶段构建方法制作高效Nginx Ingress Controller镜像的技术方案。通过将构建过程划分为GCC编译Nginx、Golang编译Controller和运行时整合三个阶段,实现了构建环境与运行环境的完全隔离。该方法相比传统单阶段构建,可将镜像体积从1.5GB缩减至50MB左右,提升30倍的存储和传输效率,同时显著降低安全风险。文章详细讲解了每个阶段的设计要点
随着企业全面上云、全面容器化,容器安全已经成为云安全的主战场。懂 Docker、K8s、又会安全的人,未来几年会非常抢手。扫码领取《网络安全资料》包含:学习路线 / 视频教程 / 电子书籍 / 工具清单 / 实战靶场 / 面试题库 / 技术社区本文由「网络安全学习笔记」原创整理,转载请注明出处。扫描文中二维码可领取更多学习资料和课程信息。
日常使用**开发时,反复粘贴项目编码规范、接口约束、架构规则极大降低效率。OpenSpec** 是配套Claude Code的标准化持久提示词工具,无需本地安装,通过**** 一键拉起,支持全局/项目/临时三级配置自动加载,团队可Git共享统一代码规范,彻底告别重复输入约束文本。本文跳过安装流程,聚焦**** 命令、配置分层、工程目录、完整实战案例、排错方案,全部代码可直接复制复用。OpenSpe
claude.md。
用于配置容器网络,同时 CNI 本身也供了一系列现成的插件。CNI 仅专注于容器的网络连通性,以及在容器被删除时清理已分配的网络资源。正是由于这种专注性,它获得了广泛的支持和易于实现的规范。IPVLAN 就是 CNI 自带的网络插件之一,它也对宿主机的网络接口进行了虚拟化,所有 IPVLAN 设备共享同一个 MAC 地址。
虚拟化技术把真实物理机子中剩余的资源重新整合,创建出来一台新的虚拟的计算机提供给开发者使用。优点:虚拟化使用软件的方法重新定义划分IT资源,可以实现IT资源的动态分配、灵活调度、跨域共享,提高IT资源利用率,降低成本,加快部署,极大增强系统整体安全性和可靠性。使IT资源能够真正成为社会基础设施,服务于各行各业中灵活多变的应用需求。虚拟化技术有3种不同的实现方案:1. 硬件虚拟化需要购买虚拟化设备2
BaseAgent - 全栈 AI Agent 系统,FastAPI + Vue 前后端分离,支持大模型自定义、工具调用、向量知识库检索,Docker 一键部署。
前两天发了一篇[怎么更好使用 DeepSeek 的文章]后,很多朋友在后台留言,希望了解 DeepSeek 的更多玩法。春节前几天事情较多,这两天终于闲下来了,打算再分享一些自己使用 AI 功能的经验,包括但不限于 DeepSeek。这一篇先介绍呼声较高的在本地部署 DeepSeek-R1 大语言模型的方案,后续会带来 DeepSeek 平替、DeepSeek 生成图片、视频、构建知识库等一系列文
在当今的软件开发领域,PHP和Python的组合越来越受到开发者的青睐。然而,搭建PHP和Python的双环境往往是一个繁琐且容易出错的过程。本文将介绍一款零配置的PHP+Python双环境一键部署工具,它能够自动完成环境搭建和配置,极大地提高开发效率。文章将从市场需求、商业价值、技术架构、核心代码实现等多个方面进行详细阐述,同时还会提供接单策略、企业级部署建议以及常见问题的解决方案。通过本文的介
本文介绍了如何构建一个生产级的PHP+Python双语言Docker镜像,解决电商系统、AI平台等场景下的环境部署痛点。文章详细展示了容器化架构设计,包含PHP-FPM 8.3与Python 3.11的集成方案,并提供了性能优化策略和安全加固措施。通过一个电商风控系统的完整案例,演示了从环境配置到应用代码的实现过程,包括Dockerfile编写、Nginx动静分离配置、PHP的OPcache加速以
摘要:本文介绍了在国内使用Claude Code AI编程助手的完整教程。首先需要通过anyrouter.top中转服务注册账号并获取API Key。接着详细说明了Node.js环境配置方法(包括Windows/WSL2、Ubuntu/Debian和macOS的安装指南),并提供了Docker容器的替代方案。最后演示了如何安装Claude Code命令行工具并进行基本使用。整个过程包含具体命令、环
springboot项目在k8s中的部署
说起多数据源,一般都来解决那些问题呢,主从模式或者业务比较复杂需要连接不同的分库来支持业务。我们遇到的情况是后者,网上找了很多,大都是根据 Jpa 来做多数据源解决方案,要不就是老的 Spring 多数据源解决方案,还有的是利用 Aop 动态切换,感觉有点小复杂,其实我只是想找一个简单的多数据支持而已,折腾了两个小时整理出来,供大家参考。废话不多说直接上代码吧!我们以 Mybatis Xml 版本
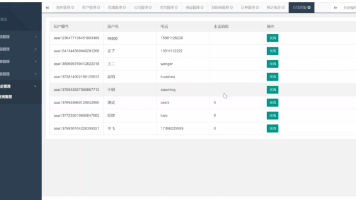
本系统以实际运用为开发背景,通过系统管理员可以对用户信息、商品评价管理、售后管理、报表管理管理、优惠活动管理、售后等进行统一的管理。总的来说,系统采用Java语言进行开发,后台使用SpringBoot框架,数据库采用Mysql。
在当今的软件开发领域,微服务架构因其高可扩展性、灵活性和易于维护等特点,受到了广泛的关注和应用。而 Docker 作为一种轻量级的容器化技术,为微服务的部署提供了极大的便利。Spring Boot 则是一个简化 Spring 应用开发的框架,它可以帮助开发者快速搭建独立的、生产级别的 Spring 应用。本文将详细介绍如何使用 Spring Boot 和 Docker 实现微服务的容器化部署,为技
分享一些适合大语言模型入门同学的开源课程,对转行或者新入门的同学非常友好(个人感受)。
以下内容为本人遇到的问题,仅作参考。
Dify是一个开源的LLM应用开发平台,提供可视化AI工作流、多模型支持、RAG管道和Agent能力等核心功能。本地部署主要出于数据安全和隐私保护需求,确保敏感数据不离开企业网络,符合行业合规要求并控制长期成本。
PHP配置说明:该php.ini配置用于支持MySQL数据库连接和Xdebug调试。启用pdo_mysql和mysqli扩展以实现数据库访问;设置Xdebug调试模式,配置host.docker.internal指向宿主机IP,端口9003用于IDE通信。此配置需在PHP安装相应扩展后生效,是ThinkPHP开发和Docker环境调试的关键设置。
PyTorch 镜像包含Python 、CUDA、PyTorch、pip,配置完requirements.txt即可运行。若显示“command not found”,说明 Docker 未正确安装或环境变量未配置。不能使用纯python镜像做基础,即使配置好环境所需包也不能调用GPU。首先构建dockerfile,新建文件dockerfile。写入下列代码(具体任务需要更改请自行参考更改)
docker
——docker
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AMD开发者中国社区
AMD开发者中国社区
 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区


 DeepSeek技术社区
DeepSeek技术社区

 DAMO开发者矩阵
DAMO开发者矩阵

 深开鸿 技术专区
深开鸿 技术专区







 智能体开发者社区
智能体开发者社区


 openEuler 社区
openEuler 社区











 AI Agent技术社区
AI Agent技术社区