- @m0_59162248
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在AI时代,程序员面临转型而非淘汰。文章指出,程序员向AI工程师/架构师转型具有先天优势,关键在于将现有工程能力(系统设计、性能优化等)与AI技术结合。作者提出五阶段进阶路径:1)夯实Python与数学基础;2)掌握深度学习与Transformer;3)聚焦大模型API、RAG、智能体等实用技术;4)学习模型微调与MLOps;5)进阶为AI系统架构师。核心建议包括:从API实践入手、发挥工程优势、

RAG(检索增强生成)技术正在革新企业AI知识库应用,解决传统AI系统的"记忆难题"。文章通过生活化比喻,解析了RAG三大核心步骤:检索相关资料、增强问题提示、生成准确回答,并列举了智能客服、内部知识管理等典型应用场景。相比传统AI,RAG具有知识实时更新、减少幻觉、成本更低等五大优势。文章还探讨了实施挑战与未来趋势,指出RAG正在推动企业从"静态知识库"向"动态知识助手"转型。最后强调AI与传统
摘要: 985本科学历的果子通过1个月高强度准备,成功从6.5年设计院工作转行至央企AI产品岗,虽薪资持平但工作强度降至965。她利用下班时间学习、面试,保持高效执行力与情绪稳定,最终面试40余场,总结出“核心问题准备+线下面试优先”等经验。现负责AI效率提升产品,面临领导期望过高、技术认知差距等挑战,通过分阶段目标管理推进落地。Eddie(合创求职合伙人)指出,AI行业需“画大饼”能力而非纠结技

前端转型Agent开发的实战经验分享 作者从React开发成功转型Agent开发,薪资增长35%,总结出核心经验: 前端技能的价值:事件循环、SSE流式输出等前端经验可直接迁移到Agent开发的工具编排、实时渲染等场景 关键认知转变:必须接受模型输出的不确定性(如"幻觉"问题),建立多层校验机制控制错误 转型路径: 先手搓基础Agent理解底层原理 用熟悉技术栈开发真实可用项目(非Demo) 通过
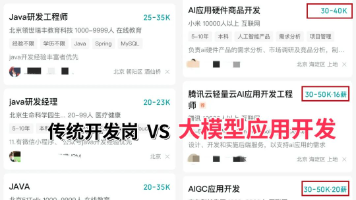
摘要 当前AI Agent开发岗对转行者较为友好,更看重工程能力而非学历背景。核心要求包括:1)扎实的Python基础(异步编程/Pydantic);2)真实LLM API项目经验(Prompt设计/成本控制);3)RAG全流程实践能力;4)深入理解至少一个Agent框架原理。关键是要有完整项目经历,能解决实际场景问题(如文档解析优化/Token控制)。该领域薪资优势显著(大厂起薪3-6万),建议
本文探讨了零基础转行AI大模型应用开发的四大常见问题及应对策略,包括技术迭代焦虑、大龄转行困境、培训模式选择和防割韭菜建议。作者分享了自己一周的学习复盘(Python技能速成、考证、亲子时间),并制定了下周目标(LangChain学习、作品集准备、城市岗位调研)。文章强调AI大模型是未来十年最具潜力的方向,列举了头部企业的高薪待遇(如字节跳动硕士起薪5-6万/月),并附赠一套由清华-加州理工双料博
2026年人工智能岗位需求激增12倍,占新经济岗位26%。零基础转型需分阶段学习:先掌握Python编程与数学基础;再系统学习机器学习、深度学习及计算机视觉核心技术;最终进阶大模型开发。行业报告显示,大模型方向人才薪资显著高于其他领域,头部企业为应届硕士生开价月薪4-6万元。本文提供完整学习路径,包含基础理论、实战项目及行业资源,并附赠由清华-加州理工双料博士团队研发的零基础教程,涵盖四大进阶阶段
摘要: Agent开发并非伪命题,而是软件工程能力的延伸。随着大模型技术落地,企业对Agent开发工程师的需求从高学历转向实际项目能力,表明该领域正趋于成熟。Agent开发的核心价值在于系统集成、私有知识融合和定制工作流,而非简单替代通用AI工具。未来,Agent技能可能成为程序员的标配,而非独立岗位。判断Agent项目价值的关键在于:是否具备不可替代的业务连接能力。AI行业(尤其大模型方向)仍是
LoRA(低秩适配)是一种参数高效的大模型微调方法,通过冻结原模型参数并添加可训练的低秩矩阵(A×B)来实现增量式适配。相比全量微调,LoRA显著降低训练成本(显存/存储减少80%以上),支持同一基座模型挂载多个适配器,适合风格迁移、领域术语适配等场景化需求。其核心优势在于:1)仅需训练原模型0.1%-1%的新增参数;2)部署时可动态加载或合并权重;3)与量化技术兼容。典型应用包括客服助手、代码风
RAG(检索增强生成)是一种通过检索外部数据注入提示词来增强大模型回复准确性的技术。文章介绍了三种主要检索方法:关键词搜索、向量搜索和混合搜索,并详细解析了RAG的两个核心阶段——索引(文档预处理、分块、嵌入存储)和检索(查询嵌入、相似度搜索、结果注入)。最后以Java 8文档问答为例,展示了Spring Boot项目集成LangChain4j、Qdrant向量数据库和本地嵌入模型AllMiniL