- @weixin_50205273
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
如果你要看某一个框架的源码,第一步当然是访问官网,搞清其组成,确定其核心类有哪些,看源码过程中可以配合画一些时序图,加以debug源码验证,这一套流程下来,没有啥源码你搞不定的。当然我在这里只能简单说,因为源码不能速成,是你摸索到适合你自己的方法后靠平时的积累跟坚持,下面LZ也是大致总结了几个核心点,希望能对诸位有一些启发。

其实并不是去了大公司就能获得高并发的经验,高并发只是一个结果,并不是过程。在来自全人类的高并发访问面前,一切都有可能发生,所以我们经常能看到顶级网站的颤抖。想要获得高并发经验基础最重要,这包括算法,操作系统,jvm,数据库,缓存,多线程等等。

Spring是我们Java程序员面试和工作都绕不开的重难点。很多粉丝就经常跟我反馈说由Spring衍生出来的一系列框架太多了,根本不知道从何下手;大家学习过程中大都不成体系,但面试的时候都上升到源码级别了,你不光要清楚了解Spring源码的整体设计和实现细节,还要懂现在互联网公司面试的套路,不然面试根本过不了。

今天我决定以面试的角度,深度聊聊一些面试中经常会被问及的知识点;希望能够帮助你们系统的梳理Java程序员面试中必须要掌握的知识技能。
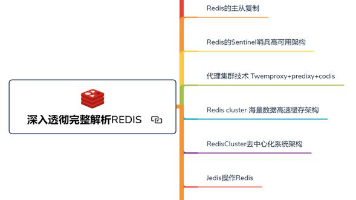
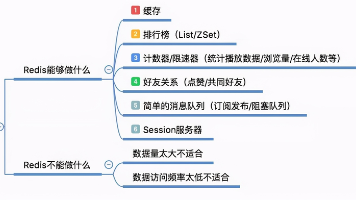
大家都知道Redis的业务范围是非常广的,但是对于刚入行的小伙伴来说可能也就知道个缓存跟分布式锁。因为Redis的很多功能在一些小企业里,根本是用不到的,得等到并发量到了一定的程度,系统扛不住了,才会用到Redis那些高级的功能。下面LZ就带大家来看看,Redis到底能干些啥:
Redis想必大家都听说过,不管是面试还是工作上我们都能见到。但是Redis到底能干什么?又不能干什么呢?(如下图)
很多互联网公司对于Java开发的要求都变高了,很多东西你不仅要会用,还得知道其中的原理,不然免谈~

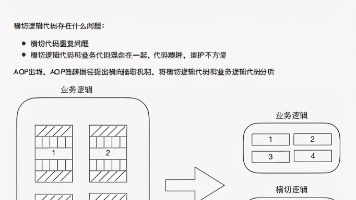
今天看到了一位博主分享自己阅读开源框架源码的心得,看了之后也引发了我的一些深度思考。我们为什么要看源码?我们该怎么样去看源码? 其中前者那位博主描述的我觉得很全了(如下图所示),就不做过多的赘述了,我这篇主要跟大家说说怎么去看源码。

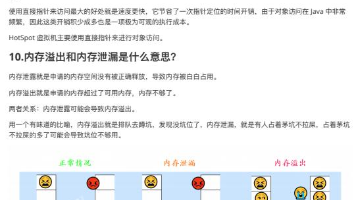
性能优化可以说是我们程序员的必修课,如果你想要跳出CRUD的苦海,成为一个更“高级”的程序员的话,性能优化这一关你是无论无何都要去面对的。为了提升系统性能,开发人员可以从系统的各个角度和层次对系统进行优化。除了最常见的代码优化外,在软件架构上、JVM虚拟机层、数据库以及操作系统层面都可以通过各种手段进行调优,从而在整体上提升系统的性能。

金三银四也快要到了,不知道大家最近面试的时候有没有被问到过Spring相关问题(循环依赖、事务、生命周期、传播特性、IOC、AOP、设计模式、源码)?