
一文搞懂大模型RAG流式输出:提升应用体验的关键技术!
文章介绍了在RAG应用中实现流式输出的技术方案,包括其三大优势:提升用户体验、实时性和内存优化。详细讲解了在FastAPI中通过StreamingResponse和SSE协议实现流式输出的方法,并结合OpenAI API展示了LLM流式输出。重点介绍了使用LlamaIndex框架在RAG应用中实现流式输出的核心逻辑和完整代码示例,帮助开发者提升大模型应用的用户体验。
简介
文章介绍了在RAG应用中实现流式输出的技术方案,包括其三大优势:提升用户体验、实时性和内存优化。详细讲解了在FastAPI中通过StreamingResponse和SSE协议实现流式输出的方法,并结合OpenAI API展示了LLM流式输出。重点介绍了使用LlamaIndex框架在RAG应用中实现流式输出的核心逻辑和完整代码示例,帮助开发者提升大模型应用的用户体验。
在传统的 RAG 流程中,我们通常会等待整个生成过程完成后,再将完整的内容返回给用户。但对于许多应用场景,尤其是需要实时交互的聊天机器人或问答系统,这种等待时间可能会导致糟糕的用户体验。流式输出则很好地解决了这个问题,它允许语言模型在生成内容的同时,将每个词或每个 Token 实时地返回给用户,就像我们看到别人打字一样。

一、为什么需要流式输出?
- 提升用户体验:用户无需漫长等待,可以立即看到内容逐字逐句地生成,大大减少了等待的焦虑感,使得交互更加流畅自然。
- 实时性:对于需要快速响应的应用至关重要,例如客服系统或实时聊天。
- 内存优化:完整生成大段文本会占用较多内存,而流式输出可以边生成边释放,有助于降低内存消耗。
二、 FastAPI 中实现流式输出
在 FastAPI 中实现流式输出,主要有两种常见方式:
1、StreamingResponse 直接流式输出
这是最基础、通用的方案,适合文件传输、日志、模拟分段输出等用途。
from fastapi import FastAPI
在这个例子中,/stream 接口会返回一个流式响应,每秒发送一个数据块(模拟的“Chunk”),客户端在每次接收到数据时就能立即处理,避免等待所有数据传输完毕。
2、SSE 协议流式推送数据
使用 SSE(Server-Sent Events)协议流式推送数据,适合实时通知、聊天系统、前端长连接监听场景,前端通过 EventSource 或相似库消费消息。
from fastapi import FastAPI
- 响应头自动设置 Content-Type: text/event-stream 和 Cache-Control: no-cache;
- 前端通过 JavaScript 的 new EventSource(‘/sse’) 可接收每条 data: 消息 ;
- 可用于实时推送 ChatGPT 或 LLM 模型输出等应用;
3、 OpenAI 或 LLM 接口流式输出
结合 OpenAI 的 API stream=True 参数,将大语言模型 (LLM) 的令牌逐步传回客户端,样例(简化):
from fastapi import FastAPI
根据以上信息,我们初步掌握了流式输出的基本原理和方法,接下来我们来看下在开发RAG或Agent等大模型应用中,如何使用流式输出!
三、RAG实现流式输出的核心逻辑
开发RAG或Agent,一般选择 LangChain(LangGraph)或 LlamaIndex 这两种框架。我们采用LlamaIndex来实现。
1、先来看下非流式输出
LlamaIndex内置了多种ChatEngine对话引擎,这里使用CondenseQuestionChatEngine+CitationQueryEngine,这种引擎特点是可以追溯来源,定位知识库中的元数据,这特点在开发RAG为主的应用中尤为常用。调用chat_engine.achat就可以进行多轮对话的查询了。 核心的代码如下:
- 使用memory组件,可以将历史信息保存到数据库和缓存中;memory组件的使用方法点击这里!
- 知识库的索引kbm_index,需事先将文档Embedding到知识库,然后创建索引Index;
- 查询引擎使用CitationQueryEngine,该引擎的特点是可溯源;
- 对话引擎使用CondenseQuestionChatEngine,初始化时需传入查询引擎、提示词、memory组件等,想看详细日志可以verbose=True;
- 多轮对话方法是chat_engine.achat;
- AI回答的内容,需要溯源知识库元数据 sources;
从代码量来看真实的RAG落地,其工程化的确需 Python功底和对LlamaIndex的各个组件的掌握的!流式输出会更加复杂;在开发RAG中,还会碰到其他的需求,我们一般在核心代码外部还需要包一层Workflow,扩展性和灵活性瞬间上升一个级别!

2、流式输出的核心代码
2.1 LlamaIndex的多轮对话底层方法
@step
大部分逻辑与上面的一致,只有以下几点需要调整!
-
构造查询引擎,流式输出 streaming=True ;
-
多轮对话流式输出 chat_engine.astream_chat(req.query) ;
-
大模型返回的一个一个数据块方法:
async for token in resp.async_response_gen(),
-
因为这里是使用workflow,所以需要将其保存到上下文的流里write_event_to_stream;
-
若不在workflow里,则直接使用 yield token;
-
溯源的Source数据可以放在最终的返回结果里;
2.2 Service层写法
asyncdefchat_stream(self, req: ChatQueryRequest)->ChatQueryResponse:
之所以有services层,是为了对流数据统一管理,因为第一步中,source并没有放流里。( 也可以在第一步中将source数据放流里)
- 接收流输出的写法依旧是 async for chunk in handler.stream_events() ;
- 最终的完整的答案需要使用await handler 来获取;
2.3 FastApi的WebApi接口层写法
@chat_router.post("/chat_stream",summary="多轮对话问答",
- 使用yield返回一个一个数据块;
- 返回的是字典类型(对象),event 对应的值表示消息的类型,data就是消息内容;
效果如下:
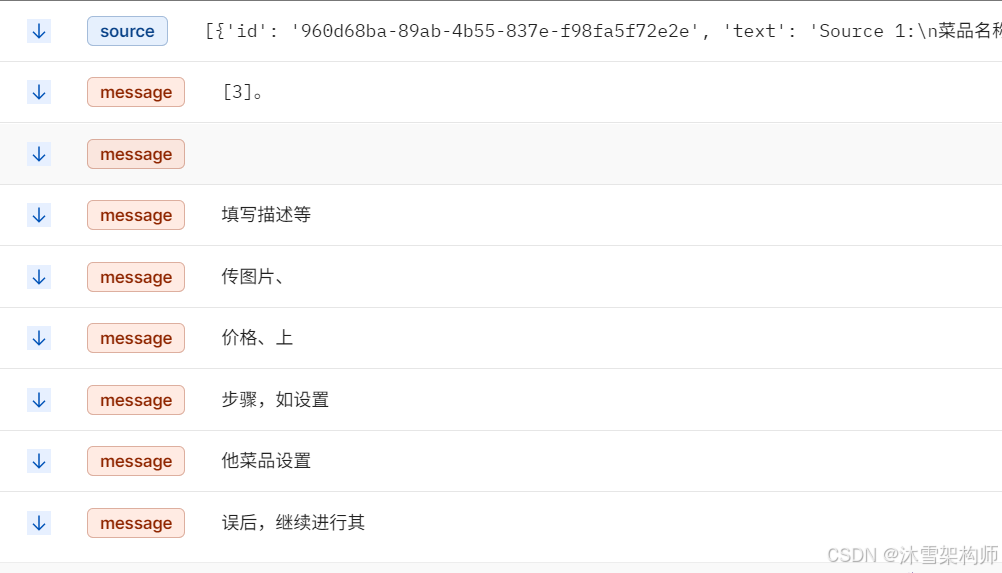
2.4 前端停止后接口的处理
FastAPI 可以通过 直接监听请求的 disconnect 事件来感知客户端断开连接,进而停止数据发送并释放资源。webapi层完整的代码如下:
# 活跃连接 Task ID 集合
至此已经将流式输出的所有功能都讲完了。
四、AI大模型学习和面试资源
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
更多推荐
 13
13 0
0- 0



 已为社区贡献66条内容
已为社区贡献66条内容

所有评论(0)