




- @Python_cocola
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
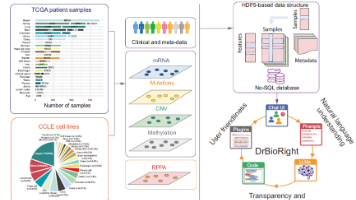
Nat Commun | DrBioRight 2.0:由大语言模型驱动的、进行癌症功能蛋白质组学分析的生物信息学聊天机器人
在人工智能浪潮席卷全球的今天,人机交互领域正经历着前所未有的变革。浙江大学张胜宇教授的讲座,为我们打开探索大小模型端云协同的思路,成为推动人工智能迈向新高度的关键力量,它所构建的人机交互新范式,将深刻改变我们与智能设备、数字世界的互动方式。
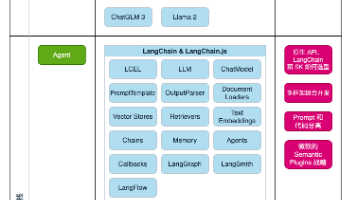
在当前的大语言模型应用开发领域,开发者面临着众多框架选择。AgentScope和LangChain各自有着不同的设计哲学和适用场景。

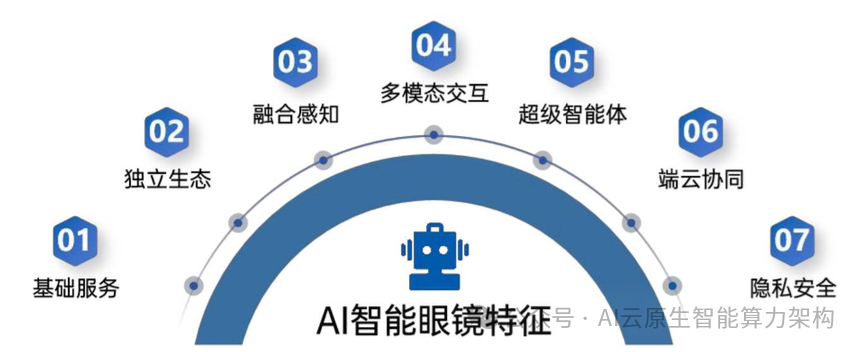
Al智能眼镜的关键技术特征涵盖了基础服务、独立生态、融合感知、多模态交互、超级 智能体、端云协同、隐私安全等。Al 智能眼镜,离不开眼镜的基础功能。视觉要求,无论是近视镜片、老花镜片还是太阳镜片,都是用于辅助人的视觉效果, 这是眼镜的主要属性。
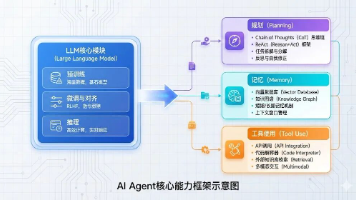
AI Agent是基于大语言模型的智能系统,具备感知-规划-执行-反馈闭环能力。文章系统介绍了AI Agent的核心能力框架(规划、记忆、工具使用)、主流开发工具对比与选型指南、三大架构(反应式、深思熟虑式、混合式)及实战案例、LangGraph工作流开发步骤,以及构建AI Agent的三大原则(简洁性、透明性、工具化与测试)。AI Agent正从实验室走向产业落地,将成为数字时代的核心生产力工具
在大模型智能体快速发展的今天,FastGPT和Dify作为两个最具代表性的开源智能体开发平台。FastGPT专注于知识库问答和RAG场景的深度优化,而Dify则致力于构建基于LLM的Agent智能体应用程序,降低开发门槛,支持多种应用类型。
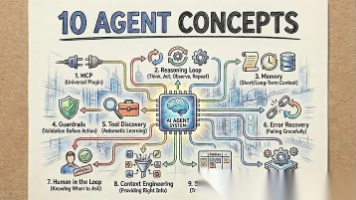
构建AI智能体远不止于挑选合适的LLM或设计精妙的提示词,关键在于掌握那些能让智能体在真实业务中自主、可靠运转的底层系统。一个能让团队眼前一亮的演示,与一个每周能切实节省10小时工时的生产级智能体,其分水岭正是这十个核心概念。它们才是打造AI系统时真正该聚焦的重点,接下来我们正式进入正题。
图像描述任务要求模型能够准确识别图像中的物体、场景以及它们之间的关系,并用自然语言生成一段简洁、流畅且富有信息量的描述****。**
这周我把Karpathy 4月份的 gist 原文完整读完,又照着搭了一遍:3 个文件、3 篇素材、10 分钟,真的跑出了一个能回答问题、还会自己写笔记的小知识库。> 这篇不谈概念,只讲我怎么动手搭的——目录长什么样、CLAUDE.md 怎么写、Ingest 和 Query 各自发生了什么,包括我踩到的坑。
在2026 年的AI DevCon 上, Anthropic 的工程师 Lamis 做了一场 30 分钟的演讲,主题是Claude Code的**上下文工程( context engineering )**。
