登录社区云,与社区用户共同成长
邀请您加入社区
/ 注意:content 是数组,不是字符串id: string;// base64 编码的图片数据Anthropic 的content是一个块数组,而不是单个字符串。这正是多模态和工具调用的基础。MessageBuilder 的核心职责,就是正确地生成这个数组。特性实现方式价值多模态块content块数组 +imagesource支持图片输入动态系统提示实时注入环境/工具上下文模型"身临其境"工
两个月持续交叉使用两款Agent模式完成上百次vibe coding开发后,能清晰感知两者的定位差异:Cursor Composer依托成熟海外生态,英文开发场景体验均衡,但中文口语理解、工程配套文档生成存在短板,长期订阅成本偏高;TRAE依托字节跳动技术底座,Work模式(原 SOLO 模式)针对国内开发者口语化需求深度优化,基础版免费降低使用门槛,三合一开发链路覆盖全流程开发,私有化部署、团队
当不同人群开始按场景选择不同的AI编程工具时,说明未来工作已经不再只有一种标准答案。vibe coding的核心是用自然语言降低开发门槛,TRAE凭借本土化优化、免费可用的基础版本、全链路开发模式,是国内独立开发者、自由职业者做vibe coding的优质选择。真正的更新,往往先发生在一个个小场景里——而有一场赛事正在让这些小场景里的创新变成现实。
分层 + 渐进——不试图用一个万能方案解决所有问题,而是按照不同维度(成本、变更频率、信任层级)将问题分解,每层用最适合的策略处理。压缩策略:零成本 → 零 LLM → LLM 驱动,渐进升级Prompt 管线:全局缓存 → 会话缓存 → 无缓存,变更频率递增配置覆盖:企业 → 个人 → 项目 → 本地,信任层级递减四者协同。
在物联网时代,JSON已成为嵌入式设备与云端通信的事实标准。无论是传感器数据上报、设备配置下发,还是OTA升级包描述,JSON格式无处不在。然而,当面对ROM仅有32KB、RAM仅有8KB的MCU时,传统的cJSON(ROM 25KB+)或Jansson(ROM 30KB+)显然过于"臃肿"。更棘手的是,许多嵌入式场景要求边接收边解析——MQTT消息可能分多次到达,串口数据以字节流形式涌入,WiF
非双一流但有实习经历,AI零代码平台成本降40%是核心卖点,竞赛荣誉需精简,技能措辞偏保守需升级。
读文件、写文件FileReaderFileWriter缺点:字符基础流使用电脑系统默认编码,Windows是GBK,读取UTF-8中文文件会乱码,新手不推荐直接用。FileReader中文乱码底层原因FileReader默认使用操作系统的系统编码(Windows GBK),解码规则和文件UTF-8二进制不匹配,翻译文字出错;必须使用转换流手动指定UTF-8编码。相对路径找不到文件程序启动的基准工作
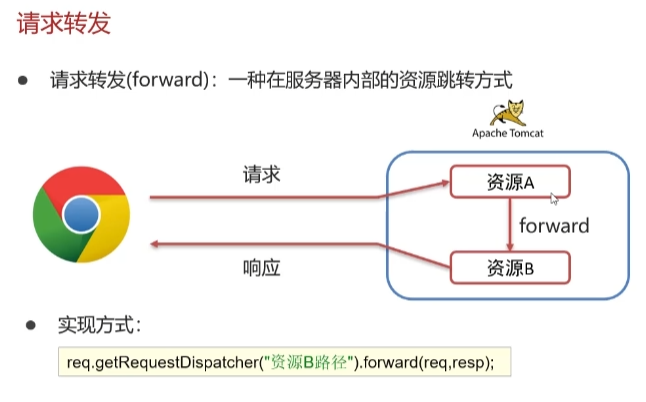
由此可以看出重定向进行了两次请求,第一次是浏览器请求资源A,而资源A让我们请求资源B,然后浏览器第二次发出向资源B发出请求请求,需要注意的是与请求转发不同,请求转发是当我们请求资源A时,资源A对请求可以进行一些相应处理,将后续的处理从资源A继续转发到资源B中。对于重定向,我么需要明白第一次请求是从浏览器发出的,当请求到我们资源A时,重定向语句会让浏览器重新请求资源B,请求的两次都是从浏览器发出的,
ChatModel是 Solon AI 生态中的统一 LLM 客户端。同步调用— 一次请求,完整返回流式调用— 基于 Project Reactor 的响应式流(工具/函数调用— 让 LLM 调用你的 Java 方法聊天会话— 自动维护对话记忆多模态消息— 文本、图片、音频方言适配— 支持 OpenAI、Ollama、Anthropic、Gemini、DashScope 等多种服务商最核心的是它使
三个月时间,从后端开发崽逐渐转型为 agent 工程师,想聊聊自己的三个小技巧。读官方文档。LangChain、Anthropic、Manus 等公司或组织的官方文档、博客质量很高,特别是 LangChain,文档简直手把手教读者怎么做一个 agent看大佬分享。Manus Peak Ji、LangChain CEO、Claude Code 之父 Boris 等等,这几位都有很多公开的分享、博客、
C++26将大幅扩展Freestanding环境下可用的标准库功能,使无操作系统环境(如内核、嵌入式系统等)能够使用更多标准库组件。新标准将支持array、span、optional等实用工具,但仍需注意动态内存分配、异常处理等限制。该特性对内核开发、嵌入式和异构计算具有重要意义。目前GCC、Clang和MSVC已提供部分支持,需通过-ffreestanding等选项启用。这一扩展填补了标准库在底
摘要: 本文探讨Java生态下物联网设备接入的工程化方案,提出分层架构(设备层→协议适配层→能力层→应用层)实现统一管控。针对摄像头、传感器、水电表等设备,建议优先选用ONVIF、Modbus等通用协议,私有功能通过厂商SDK(如海康HCNetSDK)补充。视频类设备集成示例显示,通过ONVIF协议获取RTSP流地址,结合FFmpeg处理视频流;私有SDK则通过JNA调用原生库,封装登录、控制等操
Java 是一门由 Sun Microsystems 公司于 1995 年推出的高级编程语言,现属于 Oracle 公司。它采用面向对象的编程范式,具有跨平台能力、自动内存管理(垃圾回收)和丰富的标准库,被广泛应用于企业级后端、Android 移动开发、大数据处理、云计算等领域。Java 的设计核心理念是“一次编写,到处运行”(Write Once, Run Anywhere),通过 Java 虚
本文介绍了LangChain中提示词模板的核心用法,主要包括: PromptTemplate:基础文本模板,支持占位符填充 ChatPromptTemplate:多角色聊天模板,适合对话场景 MessagesPlaceholder:动态消息占位符,用于插入对话历史 FewShotChatMessagePromptTemplate:标准化少样本提示实现 LangChain Hub:提示词共享仓库 文
本文从DNS基础概念出发,系统性地探讨了域名与DNS批量管理面临的挑战,并深入介绍了OpenClaw这一专业工具在自动解析检测、批量修改记录和监控解析状态三个核心领域的能力与实践。我们通过一个完整的实战案例,展示了如何从零开始搭建一套企业级的DNS批量管理体系,将原本需要大量手工操作的DNS管理任务转变为自动化、标准化、可观测的工程实践。
这个报错通常在第二轮对话就出现——Cursor 发起工具调用后,DeepSeek 的 API 直接返回 400。根本原因在于 DeepSeek 的思考模式(thinking mode)有一个特殊要求:当对话中包含工具调用时,后续请求必须原封不动地回传此前积累的链条。而 Cursor 在处理工具调用请求时,直接丢弃了这个字段,导致校验失败。我因此做了,一个运行在本地的轻量代理,专门负责在 Curso
在 AI Agent 开发中,Harness(马具/套件)是一个承上启下的概念。公式定义。模型提供推理,而 Harness 提供落地执行的实体。硬件类比:Model 是 CPU(计算核心),Context 是内存(瞬时寻址),而 Harness 则是操作系统(资源调度与环境隔离)。没有 Harness 的 Agent 就像一个漂浮在大脑中的灵魂——虽然能思考,但无法稳定地感知物理世界、无法受控地操
超级自动化(Hyperautomation)不是单一工具,而是技术组合拳RPA(机器人流程自动化)AI/ML(人工智能/机器学习)iBPMS(智能业务流程管理)集成平台(iPaaS)低代码/无代码工具RPA工程师不是“昙花一现”的岗位,而是数字化转型的基石角色。随着超级自动化和AI技术的融合,这个岗位的技术内涵和价值正在不断提升。技术是基础,业务是核心——最优秀的RPA工程师是“懂技术的业务专家”
经过前三篇文章的学习,我们已经掌握了Java的基本数据类型、变量和运算符。但到目前为止,我们写的程序都是"直线"执行的——从上到下,一行接一行,没有任何分支和转折。这就好比一台只会走直线的机器人,遇到岔路口不会拐弯,碰到重复劳动也不会偷懒。显然,真正的程序要比这灵活得多。今天这篇文章,我们来学习Java中的程序逻辑控制——让代码能够做出判断、选择路径、重复执行。这是编程从"玩具"走向"工具"的关键
上周三我在 Windsurf 里把 claude-sonnet-5 接进 Cascade,整个过程花了大概 12 分钟。但坑的地方在于——如果你之前接过 claude-opus-4.8,会想当然地复制那套配置,然后发现有三处完全不一样,其中一处设置界面根本没有任何提示。结论先放在这:claude-sonnet-5 在 Anthropic 官方 API 中的 model ID 为;如果你走 Open
定位与 Claude Code 一样。Codex CLI是由 OpenAI 开发的开源系统级 AI 助手,使用 Rust 语言编写,具有极高的性能和效率。它可以在终端中读取、修改和运行代码,是一个真正意义上的 AI Agent。特性说明Rust 原生构建极速启动和响应,内存占用极低开源完全开源,社区驱动,代码透明可审计多模型支持原生支持 OpenAI、Ollama、LM Studio、Amazon
摘要:在物联网与边缘计算场景中,嵌入式设备需要在资源受限的环境下实现可靠的数据持久化。FlashDB作为专为Flash存储优化的轻量级嵌入式数据库,同时支持键值存储(KVDB)和时序存储(TSDB)两种模式。本文深入剖析FlashDB的架构设计、磨损均衡算法、垃圾回收机制、掉电安全策略及FAL(Flash抽象层)适配方案,提供可直接落地的工程实践代码,帮助开发者在MCU级别实现工业级数据存储能力。
OpenCode 是一个基于大型语言模型(LLM)的开源 AI 编程助手。它旨在理解开发者的意图,提供代码补全、生成、解释、重构、调试建议等功能,并能通过插件(Skill)系统扩展其能力,适配不同的编程语言、框架和工作流。核心特性:智能代码补全与生成:根据上下文和注释,生成高质量的函数、类甚至整个模块。代码解释与文档生成:对复杂代码段进行自然语言解释,并自动生成文档注释。交互式对话与调试:允许开发
通过本实战项目,我们深入应用了 Codex/GPT 的高级提示工程、上下文管理和任务分解技巧,构建了一个实用的代码审查智能体。将大模型视为一个需要精确引导和约束的“思考引擎”,而非一个简单的问答机。通过精心设计的系统提示、清晰的交互协议以及与现实工作流的深度集成,你可以创造出真正强大、可靠的AI智能体,显著提升开发效率与代码质量。
在 Web 开发里,我们不会为了加日志、鉴权、限流、压缩、异常处理,就重新设计 HTTP 请求流程。它可能不按格式输出,可能跳过步骤,可能忘记系统提示,可能随便编工具参数,可能在应该调用工具的时候直接胡说,可能在应该等待人工确认的时候擅自执行。但随着模型越来越能遵循指令、理解 Skill、使用工具、处理长上下文,过度复杂的图结构会越来越像一种历史包袱。银行转账、库存扣减、权限校验、订单状态机,都应
Spring AI 社区已将 Agent Skills 概念集成到 Spring 生态中,允许在 Spring Boot 应用内部运行 AI Agent 并加载 Skills。“AI 擅长 Python,但在 Spring Boot 上会幻觉。以下 Skills 专为 Spring Boot 开发设计,直接提升 AI Agent 在 Spring Boot 项目中的编码质量。Spring Boot
显而易见,如果不注意这个问题,当程序从中文操作系统移植到英文操作系统上运行时,中文字符串的排序结果会完全不同,如果这个排序结果仅仅用于显示,则显示结果会不同,如果排序结果被作为一种类似主键的方式存储在文件,那么在中文操作系统下排序的文档,到了英文操作系统下就变成了不排序的文档,整个程序逻辑都会发生错误。我们可以看出,不同的区域性信息,上述字符串的排序结果完全不同,简体中文下,排序按照汉字的拼音顺序
Agent 跑工具调用经常一轮接一轮,要是只把最终回答推给前端,用户那边就是十几秒甚至几十秒的空白,体验很差,出问题也没法排查。我们的做法是把整个工具调用循环里发生的事情都拆成事件吐到 SSE 流里——token 在出、思考在写、工具被调了、工具返回了什么,前端按事件类型渲染就行。记忆解决了"它记得",但 Agent 还差一块——"它能在你不在的时候干活"。JobRunr 要把这条 lambda
对于一个流来说,这个ContinuationToken是对这个流的某个中间位置的描述,客户端得到这个ContinuationToken后,不仅不知道流尚未结束,还能利用它从正确的位置继续获取数据。我们知道Token就是AI领域的货币,所以这本账单使用Token数量来记账,它记录了模型调用过程中的各种Token数量,包括输入输出的Token数量、是否命中缓存、推理过程中使用的Token数量等。所有的
Claude Code 的三层compact机制,本质上是在回答一个朴素问题:长程 Agent 任务里,哪些历史必须留下,哪些只是在占地方?用模型摘要兜底,能力强,但贵且不稳定。用本地 notes 承接中等压力,避免过早进入高成本路径。最不起眼,却跑得最频繁:每次请求前都扫一遍旧工具结果,能用就走服务端缓存编辑,cache 已经过期就直接本地瘦身。这套设计最聪明的地方,不是“压缩得多”,而是把不同
处理一份10万字的年报,直接全塞进上下文,输入Token可能飙到13到15万,一次调用就要花掉好几块甚至十几块。分块摘要加逐步合并。把文档按章节或者每3000字分块每块单独调用摘要模型(推荐Haiku,成本超低)把得到的若干条分段摘要合并,再调一次Sonnet生成总摘要这么干的话,输出Token总量可能会增加,但输入Token从13万降到几千,总成本能降90%以上。而且因为避免了超长上下文带来的注
java
——java
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区
 AtomGit AI 社区
AtomGit AI 社区



 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区


 EazyDevelop社区
EazyDevelop社区

 openEuler 社区
openEuler 社区

 AI硬件创业社区
AI硬件创业社区








 龙虾开发者社区
龙虾开发者社区




 DAMO开发者矩阵
DAMO开发者矩阵



 DeepSeek技术社区
DeepSeek技术社区





 MCP技术社区
MCP技术社区