登录社区云,与社区用户共同成长
邀请您加入社区
本文介绍了2026年AI编程工具生态,重点分析了ClaudeCode、Codex、CCSwitch、AnyRouter和TeamoRouter五款工具的定位、功能与协作架构。详细介绍了各工具的安装配置、核心功能、使用技巧和成本对比。
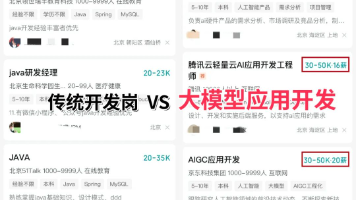
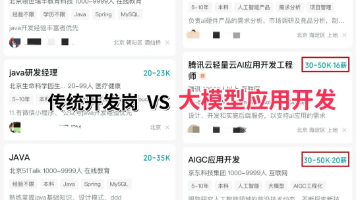
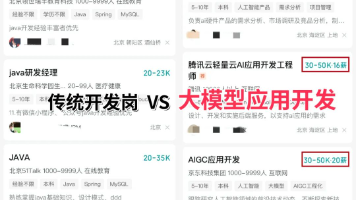
对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大?答案只有一个:人工智能(尤其是大模型方向)当下,人工智能行业正处于爆发式增长期,其中大模型相关岗位更是供不应求,薪资待遇直接拉满——字节跳动作为AI领域的头部玩家,给硕士毕业的优质AI人才(含大模型相关方向)开出的月基础工资高达5万—6万元;即便是非“人才计划”的普通应
摘要: 本文介绍了如何通过安装Skill(技能插件)提升AI工具(如Codex、Claude Code)在自媒体创作中的效率。Skill相当于为AI提供明确的任务流程,减少重复劳动。推荐5个实用Skill: web-access:快速调研对标内容; baoyu-skill:一键做图与多平台发布; guizang PPT:制作品牌风PPT; ListenHub:多平台内容自动适配; humanize
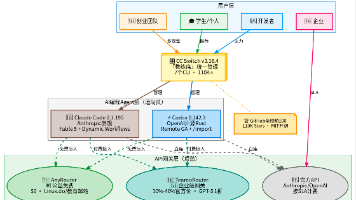
先把这篇文章的目标说清楚:看完之后,你应该能判断这件事值不值得做,以及从哪里动手。最近面试了几个转大模型开发的候选人,发现一个有趣的现象:大家手里都有能跑的 Agent Demo,有的甚至接入了 Codex 或 Claude Code 做代码生成,但在聊到“如何让 AI 编程工具在团队中稳定运行”时,往往卡壳。很多人以为上了 AI 编程助手,团队效率就能起飞。现实是,如果没有处理好权限、日志和上下
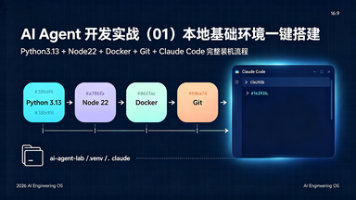
本文是一篇AI Agent开发环境配置指南,重点介绍如何在Python 3.13、Node.js 22、Docker和Git基础环境下安装Claude Code并实现首次登录运行。
文章摘要 2025年以来,AI Agent框架选择成为开发者面临的难题。本文基于实战经验,提出选型前需回答四个问题:单Agent还是多Agent、编排方式(链/图/路由)、工具调用处理及记忆管理。随后对比五大主流框架(LangGraph、CrewAI、AutoGen、Claude API、OpenSquilla),分析其架构、扩展性等特性,并提供选型决策树。最后以OpenSquilla实现公众号自
本文探讨了AI智能体的演进趋势,提出"服务型AI智能体"(SFA)将成为第四代商用智能体的发展方向。文章指出,当前主流的执行型智能体虽能完成操作任务,但缺乏服务温度,而真正的商业场景需要兼顾功能与体验。智能体发展已历经四个阶段:工具型(基础对话)、知识型(业务理解)、执行型(任务处理),直至现在的服务型(人文交互)。SFA的核心理念是"服务优先",强调在具备
AI是2026年网络安全的最大变量——既是攻击者的“超级武器”,也是防御者的“最后希望”攻防平衡已被打破——漏洞利用从“N天”变成“N小时”,传统防御模式正在失效勒索软件已工业化——从单一事件变成高度系统化的犯罪产业云原生是新的主战场——容器逃逸漏洞让“一个容器沦陷=整个集群暴露”身份是新的边界——71%的企业已经失守,非人身份(NHI)是最大盲区2026年,网络安全不再是“IT的事”,而是“企业
标准 RL:训练系统是 “主人”→ 它决定问什么、答几次、怎么评分OpenClaw:训练系统是 “寄生者” → 它寄生在真实对话上,被动收集数据Rollout = 被动等待(不是主动生成)Environment = 真实用户(不是模拟器)PRM = 即用即评(不是预训练 RM)Policy = 对外服务(不是内部推理)一切设计选择都源于这个范式转变。Rollout Allocation = 决定"
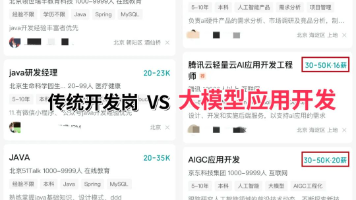
摘要: 随着AI Agent技术的成熟,传统前端开发岗位面临萎缩,2026年或成转型关键节点。本文分析前端工程师的困境(需求减少、内卷加剧、价值边缘化),对比AI Agent领域的高需求与薪资优势(薪资高出30%-50%),并拆解技术栈差异(需补Python、Prompt工程等)。前端工程师凭借TypeScript基础、流式数据处理、产品意识等优势,转型路径较短。文章提供学习框架(如LangCha
2026世界人工智能大会(WAIC)将于7月17日-20日在上海举行。合合信息作为精英合作伙伴,将在世博展览馆H1-B1130展台展示多项AI创新应用:面向个人的扫描全能王AI去反光技术可一键消除拍摄反光,AI鉴伪技术通过互动游戏和跨模态系统识别AI伪造痕迹;面向企业的文档智能处理产品TextIn xParse、商业数据Agent“启信慧眼”等B端工具,以及AI教育产品蜜蜂智阅一体机也将同台亮相,
没有海外 Visa 如何升级 ChatGPT Plus、Pro 5X 或 Pro 20X?本文介绍套餐区别、自助升级步骤、覆盖充值与账户授权安全注意事项,并提供 UPGPT 与 GitHub 完整图文教程。
传统提示词开发让你和AI处在一种模糊的、不断讨价还价的关系中。你负责定义“对”是什么,AI负责把“对”做出来。在AI可以写代码的时代,“写代码”本身不再稀缺。稀缺的是“知道该写什么代码”。规范就是那个“知道”的显式表达。这也许就是AI编程工具的下一个演进方向——不是更强的模型、更快的补全,而是更好的协作协议。OpenSpec。
前端行业困境与破局之道 当前前端行业面临多重挑战:岗位缩减、薪资下降、AI冲击及年龄危机。AI Agent已能替代70%基础开发工作,加剧竞争;经济下行导致岗位减少,而培训班持续输出新人,形成恶性内卷;30+开发者面临精力不足与技术迭代压力。 破局建议: 职业转型:转向项目管理、售前或考公考编,寻求稳定; 技能升级:深耕技术(如全栈开发)或强化英语能力,瞄准外企机会; 副业拓展:结合兴趣发展第二收
大龄前端转型AI大模型开发指南 面对前端岗位萎缩与AI冲击,一名36岁开发者制定转型计划: 能力评估:具备Python基础(numpy/pandas)及计算机知识,数学要求较低(应用开发方向); 目标定位:瞄准大模型应用开发岗(RAG/Agent/微调),优先武汉/深圳,拒外包/初创,长期目标AI架构师; 市场验证:中型企业年龄包容性强,需2-3个实战项目(如知识库机器人)弥补年龄劣势; 成本测算
AI时代职业转型指南:前端开发者的三大方向 方向一:AI产品经理 前端开发者转型AI PM优势在于交互设计经验,需掌握需求分析、AI技术原理(如LLM/RAG),通过低代码工具实践MVP开发。推荐学习吴恩达AI课程,从代码编写转向产品定义。 方向二:AIGC内容专家 凭借视觉敏感度切入海外短剧赛道,需掌握Runway/Pika等AI视频工具,建立从脚本生成到本地化分发的全流程能力。关键点是研究Ti
ESP32-S3、AI玩具机芯、ULINK-A6、智能毛绒玩具、语音交互、嵌入式开发、开源硬件、玩具方案、量产方案
提示注入是AI安全的头号威胁——模型分不清合法指令和恶意指令RAG知识库和向量数据库是新攻击面——默认无认证=默认被入侵自主AI攻击正在成为现实——AI智能体可以自主完成从入侵到勒索的全链条防御的唯一出路是以AI对抗AI——机器对机器,智能体对智能体AI不是未来的安全挑战——它就是现在的安全挑战。你今天的AI应用,可能已经被攻击者盯上了。
文章摘要:AI编程工具本质上是提升编程效率的高级工具,类似于历史上的汇编语言和高级语言,不会取代程序员。当前AI编程的热潮源于大语言模型(LLM)擅长处理编程语言的简洁逻辑结构,但实际应用仍局限于一维信息处理。程序员就业波动主要源于市场供需关系,而非AI工具本身。未来10年,人工智能(尤其是大模型方向)仍是职业发展潜力最大的领域,薪资待遇优厚,适合程序员转型和提升。文章最后提供了大模型学习资源和路
2026年AI行业的重大机遇聚焦于应用层,企业加速布局AI产品落地,AI前端工程师等人才需求激增,薪资水平显著高于传统岗位。核心能力包括RAG(信息整合)、Agent智能体(自主任务处理)和模型微调(业务适配)。大模型相关岗位供不应求,字节跳动、腾讯等企业提供高薪职位。AI技术正重塑职业竞争力,转型或入行人工智能领域(尤其是大模型方向)成为职业发展的优选路径。学习资源包括路线图、视频教程、书籍、行
摘要: "小暖"是一个基于Spring Boot 3和Spring AI框架开发的AI聊天陪伴应用,前端采用纯HTML/CSS/JS单页应用,后端接入DeepSeek大语言模型,支持SSE流式对话和多轮上下文记忆。项目提供温暖治愈的聊天体验,具有角色设定、对话记忆、流式传输等功能,可通过环境变量配置API密钥快速启动。核心架构包括双模式对话(流式优先+普通兜底)和内存存储的对话记忆,适用于情感陪伴
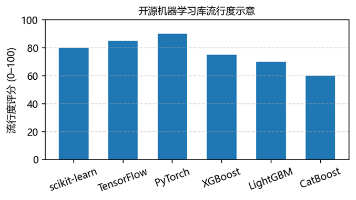
本文系统介绍了机器学习开源算法生态,重点分析了主流框架、工具和最佳实践。内容涵盖经典ML库(如scikit-learn)、梯度提升库(XGBoost系列)、深度学习框架(TensorFlow/PyTorch)及领域专用库,同时阐述了MLOps工具链和工程实践。文章还探讨了开源许可证合规、社区贡献方式及未来发展趋势,为ML开发者和研究人员提供了全面的参考指南。表格数据直观展示了各类工具的技术特性和适
《医疗AI操作系统白皮书》摘要 华为联合顶级三甲医院发布医疗AI建设权威指南,针对数据孤岛、系统割裂等行业痛点,创新提出"AI操作系统"三层架构(基础设施-工具平台-模型应用)。方案覆盖诊疗、服务、科研、运营四大场景,提供分阶段实施路径与生态共建策略,强调国产化适配与数据安全。兼具理论高度与实操性,为医院AI平台建设及厂商交付提供标准化参考,是医疗数智化转型的标杆性指导文件。(
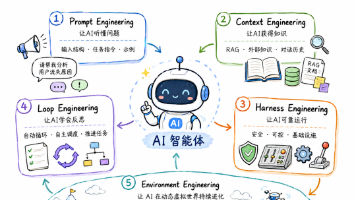
AI智能体训练范式正在经历从静态数据到动态环境的革命性转变。文章系统梳理了五大工程范式演进路径:Prompt工程(基础指令调控)、Context工程(知识增强)、Harness工程(系统安全)、Loop工程(自主循环)直至最新的Agentic环境工程(虚拟世界训练)。虚拟环境解决了传统静态数据集的三大局限:缺乏动态反馈、现实试错成本高、无法支持连续决策。研究者从符号/神经合成两条技术路线构建虚拟训
AI时代的前端:从切页面到Agent开发者的进化 摘要:AI工具已能快速生成基础前端代码,引发部分开发者焦虑。但真正的危机仅针对低复杂度工作,如静态页面开发。前端核心能力——异步流程设计、流式体验优化、组件化工程思维等,正成为AI Agent开发的关键竞争力。2025年主流AI厂商的Agent SDK普遍采用TypeScript/Node.js技术栈,印证了前端技能与Agent开发的高度适配性。前
企业级AI Agent生产应用面临六大核心挑战:数据可信度、模型可替换性、工具可控性、身份权限管理、运行可恢复性和任务级评估。本文提出六层架构体系:1)数据治理层确保信息可追溯;2)模型抽象层实现灵活切换;3)工具约束层定义安全边界;4)身份继承层遵循最小权限原则;5)运行控制层设置执行熔断机制;6)任务评估层建立多维度量标准。建议企业采取渐进式实施路径,从低风险场景切入,通过模块化设计构建可持续
人工智能
——人工智能
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DeepSeek技术社区
DeepSeek技术社区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区





 智能体开发者社区
智能体开发者社区
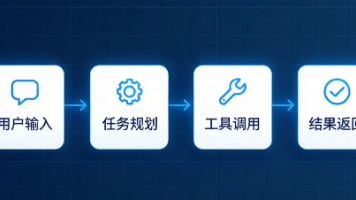









 AtomGit AI 社区
AtomGit AI 社区


 AI编程社区
AI编程社区

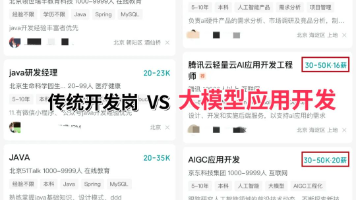
 DAMO开发者矩阵
DAMO开发者矩阵
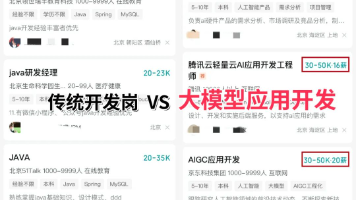

 AI Agent技术社区
AI Agent技术社区




 openEuler 社区
openEuler 社区