登录社区云,与社区用户共同成长
邀请您加入社区
规神经网络在物理系统预测中容易发散,因其忽视守恒定律。哈密顿神经网络(HNN)和拉格朗日神经网络(LNN)通过建模能量函数而非直接预测轨迹,解决了这一根本问题。HNN学习哈密顿量并通过正则方程保证能量守恒;LNN则适用于约束系统,通过拉格朗日方程建模广义坐标。这类结构保持网络在天体力学、机器人控制等领域展现出显著优势,能实现长期稳定预测,其核心在于将物理定律编码为网络架构的硬约束,而非依赖数据驱动
实测结果是:系统很克制地给出了"未检测到异常"标签,AI 可疑性 0.0%,检测耗时 2.942s,盖的是绿色的"真实"印章,备注只有一句"无明显伪造痕迹"。水果电商里最近几个月高频出现一种"仅退款"骗术:买家收到完好的水果之后,用 AI 把"真水果"渲染成"烂水果",再拿渲染后的图去找商家"仅退款"。或许更值得期待的是:当"内容真实性"成为像"数据加密"一样的底层技术命题时,AI 鉴伪会像今天的
深度学习的工程化落地,早已不是纸上谈兵的事。从卷积神经网络到Transformer,从目标检测到大模型私有化部署,技术栈不断延伸,工程师面临的知识体系也越来越庞杂。
本文提供了在Windows系统下复现论文代码的详细配置指南。文章首先介绍了如何从Github获取项目代码并导入PyCharm,重点强调了克隆项目时需要注意的绿色代码块标识。随后详细讲解了两种创建虚拟环境的方法:使用Anaconda(包括环境创建、激活和依赖安装步骤)和使用PyCharm原生虚拟环境工具(针对不同操作系统给出具体命令)。作者特别提醒必须严格遵循项目指定的Python版本(如3.8)以
飞腾E2000模块
Product Hunt 每日热榜 | 2026-07-16 V2Fun是一个基于自研3D建模和人工智能动作捕捉模型的AI 3D创作平台。它帮助创作者将图像、提示和视频转换为高质量的3D模型,并通过先进的8K贴图生成技术提升素材质量,让用户无需切换不同的建模、贴图和动作捕捉工具,就能创建出适合动画的角色。此外,V2Fun还支持通过包括Nano Banana等模型生成图像,使创作者能够更快地探索视觉
2026年7月,人工智能领域正经历从"参数堆叠"到"数理融合"的基础理论转向。世界人工智能大会(WAIC2026)首次将"基础理论原始创新"设为核心主轴,聚焦数学与AI的深度交叉。
EESG2026国际学术会议征文通知:第二届电气工程与智能电网国际会议(EESG2026)将于2026年8月21-23日在中国鄂尔多斯召开。会议由鄂尔多斯应用技术学院等高校联合主办,主题涵盖智能电网、可再生能源、电力系统、信息安全和人工智能在电力领域的应用等方向。投稿论文需为原创英文稿件(≥4页),通过审核后将由SPIE出版社出版(ISSN: 0277-786X),并提交EI Compendex和
本文摘要:企业级AI硬件选型需关注CPU与GPU的架构差异,GPU更适合大模型(LLM)的并行矩阵运算。LLM处理文本时需保持词序信息,Embedding模型通过池化层压缩向量。GPU选型需重点考虑显存带宽和容量,H200/B200等新型号可解决大模型推理的"内存墙"问题。CPU与GPU需合理配比,避免资源浪费。主流部署框架已转向连续批处理和PD分离架构,提升算力利用率。2026年趋势显示硬件选型
2026年具身智能、机器人与控制系统国际学术会议(EIRCS 2026)将于2026年8月21—23日在中国杭州举行。随着具身智能、机器人运动控制与控制系统三者的深度协同,智能机器人正从结构化场景走向非结构化复杂场景,重塑工业制造、医疗服务、应急救援等领域的技术形态与应用模式。
【摘要】WAIC2026标志着AI行业从技术狂热转向产业落地的关键拐点。本届大会聚焦四大核心趋势:1)大模型向垂直专精与端侧轻量化转型;2)国产算力实现全链条突破,支撑自主可控;3)具身智能推动AI从虚拟交互迈向实体行动;4)产业AI方案实现标准化普及,惠及中小企业。与往届相比,2026年更强调可量化商业价值,技术竞赛正被效率竞赛取代。随着行业褪去泡沫,AI开始深度融入实体经济,在医疗、工业、金融
2026年9月将举办多场国际学术会议,涵盖计算机、人工智能、工程、教育、环境等多个领域。会议地点包括中国昆明、西安、广州等地及海外。主题涉及信息科学、智能计算、电力系统、环境保护等,适用于学术交流、职称评定及成果展示。投稿形式包括论文、海报展示及报告。主要会议包括ISCTT2026(昆明)、AICE2026(西安)、ICESD2026(天津)等,举办时间集中在9月4-6日及11-13日。欢迎学者及
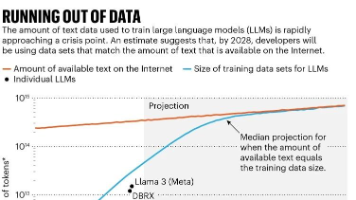
你有没有发现一个诡异的现象?2025年开始,越来越多人抱怨大模型"变蠢"了。ChatGPT的回答越来越模板化,Midjourney的图越来越像"平均审美"的拼贴画,新版本不如旧版本好用。你以为是模型被"阉割"了?以为是产品经理瞎改prompt了?都不是。更准确地说——AI正在吃自己生成的训练数据,有效信息逐代衰减,它正在慢慢饿死自己。这不是比喻。这是一套有数学证明的物理框架给出的推论。
语音合成(Text-to-Speech, TTS)技术正在经历从拼接合成到参数合成,再到端到端神经网络生成的范式转变。现代TTS系统能够生成媲美真人的自然语音,支持多说话人、多情感、多语种的灵活控制。本文将梳理TTS技术的演进脉络,深入解析当前主流架构的原理与实现。
Product Hunt 每日热榜 | 2026-07-15 ClawTeams 是一个为电商卖家打造的人工智能员工平台。与其雇佣专门的员工或自己独自处理所有事务,不如让这个协调的 AI 团队像真正的员工一样思考、计划和执行。一个目标,一个团队,完全无需微管理。你只需告诉团队负责人你想要的结果——比如“第四季度收入增加 20%”——然后他们会将目标细化,分配专门人员并执行计划。你会通过 Slack
【摘要】华南农业大学将于2026年8月21-23日在广州主办"人工智能与低空技术国际学术会议(AI-LAT2026)",主题涵盖无人机系统、智能飞行控制、空域管理等前沿领域。会议采用"刊会结合"模式,录用论文将收录于SAE论文集(EI/Scopus双检)或合作期刊《Journal of Aerospace Technology and Management》
【摘要】PyTorch学习痛点与AI辅助解决方案 针对PyTorch初学者常见的张量维度冲突和训练循环逻辑错误两大痛点,Claude3.5Sonnet展现出显著辅助效果。测试显示,其能将维度报错调试时间从45分钟缩短至3分钟,效率提升15倍。该AI可精确追踪张量变换过程,并以表格形式可视化维度变化,同时能逐行解析训练循环的数学原理。对比GPT-4o等模型,Claude3.5在PyTorch报错诊断
OpenClaw 是一个功能强大的开源工具,结合硅基流动(SiliconFlow)的 API,可以让你在本地轻松运行和测试大语言模型。本教程将为你提供在 Windows 系统上从零开始安装和配置 OpenClaw 的完整步骤,即使是新手也能跟着一步步操作成功。
我正在智谱大模型开放平台 BigModel.cn上打造AI应用,智谱新一代旗舰模型 GLM-5.2 已上线, 在推理、代码、智能体综合能力达到开源模型 SOTA 水平,通过我的邀请链接注册即可获得 2000万Tokens 大礼包,期待和你一起在BigModel上畅享卓越模型能力。链接:https://www.bigmodel.cn/invite?GLM模型全面升级邀好友实名注册得Tokens。
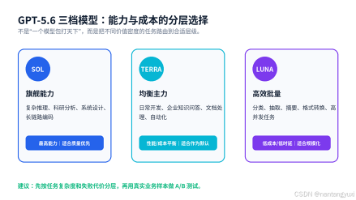
OpenAI发布GPT-5.6系列,推出Sol、Terra、Luna三档模型覆盖不同成本需求。Sol面向高价值复杂任务(如科研编码),Terra适合通用生产任务(如文档生成),Luna针对高并发简单任务(如分类摘要)。新特性包括多档推理强度(max至none)、Pro模式、多代理协作和程序化工具调用,显著提升复杂工作流效率。官方基准显示代理型任务(如终端操作、科研)性能提升显著。成本核算建议按&q
2026年,中国具身智能市场规模预计达1.09万亿元,人形机器人整机产量有望突破10万台。当AI从数字世界走向物理世界,通信模组正从“通用部件”升级为机器人的“专用核心组件”。本文深度解析Wi-Fi 7如何以320MHz超大频宽、MLO多链路操作等技术特性,成为支撑多传感器融合、低时延控制与集群协同调度的关键底座。文章还介绍了欧飞信科技面向具身智能的旗舰级Wi-Fi 7模组O2072PM/O207
Product Hunt 每日热榜 | 2026-07-14 AgentKey 是一个插件,只需一个命令就能将你的代理与实时外部数据连接起来。你只需将它安装到 Claude Code、Codex、OpenClaw 或任何基于 MCP 的代理上,立刻就能访问搜索引擎、网页、社交平台、财经信息、电商数据、商业数据和加密货币数据。无需复杂的集成和设置,自动故障转移功能确保工作流程持续进行。
SRVD与具身智能:当AI拥有物理身体之后,它需要一份怎样的“生存手册”?
第七届物联网、人工智能与电气能源国际学术会议(IoTAIEE2026)将于2026年8月21-23日在甘肃兰州举行。会议由兰州交通大学主办,IEEE出版论文集,并提交至IEEEXplore收录,EI Compendex和Scopus检索,往届最快实现会后2个月EI检索。会议聚焦物联网、人工智能与电气能源领域,设置三大主题方向,包括物联网技术与应用、人工智能研究与应用、电气能源技术等。多位国内外知名
本文探讨了生成对抗网络(GAN)在工业界的核心应用,重点分析了超分辨率、人脸合成与数据增强三大领域。文章首先梳理了超分辨率技术的发展历程,从传统插值方法到基于GAN的SRGAN、ESRGAN和Real-ESRGAN,并介绍了感知损失函数如何解决传统MSE损失导致的模糊问题。在人脸合成方面,文章讨论了DeepFake技术原理及其检测方法。此外,还展示了GAN在医疗影像增强和数据稀缺场景中的应用价值。
目标: 从最基础的门电路出发, 用 sympy 的SOPform工具验证 CMOS 数字电路设计的"晶体管数估算"方法, 并把这一思路逐级扩展, 最终用于27B 参数 LLM 推理芯片的规模与速度估算。研究方法3-to-8 译码器↓ (1 输入对应 1 输出, 8 位最小案例验证)2×2 → 3×3 → 4×4 乘法器↓ (用 SOP 最小化, 确认增长趋势)8×8 (sympy 超时失败)↓16
第六届计算机科学与区块链国际学术会议(CCSB2026)将于2026年8月21-23日在中国珠海召开,由IEEE出版(ISBN: 979-8-3195-0625-2)。会议涵盖计算机科学(人工智能、数据挖掘等)和区块链(智能合约、加密技术等)两大主题,录用论文将收录至IEEEXplore并提交EI和Scopus检索。CCSB检索记录优秀,往届会议均在短期内完成检索(如CCSB2025会后2.5个月
本文从神经风格迁移的原理出发,深入浅出地讲解了如何利用OpenCV DNN 模块轻松实现静态图像和实时摄像头的风格迁移。全部代码不超过 30 行,却展现了人工智能与艺术的奇妙结合。无论你是计算机视觉的初学者,还是想快速开发一个创意应用,这都是一份极佳的参考。未来,随着等轻量级网络的出现,风格迁移将变得更加高效,甚至可以运行在微型设备上。而结合GAN的CycleGANAnimeGAN等技术,更是让实
摘要 本期专栏聚焦农业遥感AI技术,针对耕地与作物识别的行业痛点,提出双分支网络解决方案。方案通过地块分割与作物分类双任务协同,融合时序、纹理、光谱特征,有效解决裸地与耕地混淆、地块粘连、作物错分等核心难题。关键技术包括边界感知U-Net优化、干扰剔除模块和批量后处理,支持耕地精准提取、非农干扰自动剔除、多作物分类及批量制图。代码提供完整模型架构与干扰净化实现,可适配全国不同地貌的耕地监测需求,满
虹膜识别 MATLAB 代码,涵盖图像预处理、虹膜定位、特征提取、BPN 训练与识别全流程。
*视觉语言模型(Vision Language Model, VLM)**是一类能够同时处理视觉信息(图像、视频)和文本信息,并在两种模态之间建立深度语义关联的人工智能模型。核心本质:VLM通过在共享的语义嵌入空间中对齐视觉特征和语言表示,实现"看图说话"、"听文生图"的跨模态理解与生成能力。理解图像内容并用自然语言描述遵循涉及视觉的复杂文本指令推理跨越视觉和语言的多模态信息泛化到训练时从未见过的
神经网络
——神经网络
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DAMO开发者矩阵
DAMO开发者矩阵


 武汉城市开发者社区
武汉城市开发者社区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区


 openEuler 社区
openEuler 社区

 深开鸿 技术专区
深开鸿 技术专区







 人工智能6S服务平台
人工智能6S服务平台




 AtomGit AI 社区
AtomGit AI 社区

 AI Agent技术社区
AI Agent技术社区

 DeepSeek技术社区
DeepSeek技术社区




 智能体开发者社区
智能体开发者社区



 AMD开发者中国社区
AMD开发者中国社区






