登录社区云,与社区用户共同成长
邀请您加入社区
STL是一套内置的通用工具库,核心组成如下:容器:存储数据的结构。vector(动态数组)、map(键值对)、set(唯一元素)、list(链表)等。迭代器:类似指针,用于遍历容器(如 begin()、end())。算法:操作容器的函数。sort()(排序)、find()(查找)、copy()(复制)等。本题主要使用map。
我们所谈论的算法,作为一门实用的科学,既有科学的一面,也有艺术的一面。作为科学,它的结构可以分析,它的行为可以预测,它的属性可以量化,它的正确性可以证明。”,也不是简单的从一般到特殊。:使用高级语言创建了一个整型数组时(例如 int[] values = new int[10]),我们不再把 values[7] 称为“一个存储单元”,因为存储单元的大小是一个字节,在32位操作系统上,values[
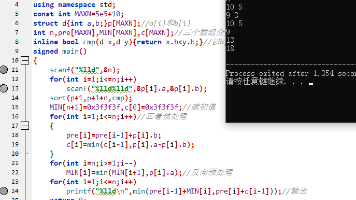
需要统计其中完全平方数的个数。完全平方数是指可以表示为某个正整数。一个数的平方等于这个数乘以这个数本身。指可以恰好表示为某个正整数的平方的数。中,有多少个正整数是完全平方数。不能表示为任何正整数的平方。输入两行,第一行为一个正整数。小杨同学正在研究完全平方数。之间的所有正整数中(包含。),有多少个数是完全平方数。中没有完全平方数,则输出。输出一个非负整数,表示。,第二行为一个正整数。
关键观察是:菱形的上半部分和下半部分关于中心行对称,每行的。出现在两个对称位置,且距离中心列的偏移量随远离中心而增大。个网格的画布中,使用字符画一个边长为。菱形中心位于画布中心。表示,菱形边所在的网格用。行,表示按要求画的菱形。
需要将每个待加密数字按映射表替换后输出。本质是**离散映射(Discretization Mapping)**问题,即通过一个固定的查找表完成一对一的数值替换。也就是:把输入第二行里的每个数字,都按照输入第三行的密码本换掉后输出。请你按照密码本,把原来的每个数字都换成新的数字,然后输出。小杨同学有一串数字,想把它们变成另一串数字,这个过程叫做。第一行:一个整数,表示有多少个数字需要加密;,密码本告
这篇文章介绍了一个统计二叉树中完全二叉树子树数量的算法。核心思路是通过后序遍历自底向上计算每个子树的状态,包括是否为满二叉树、是否为完全二叉树以及子树深度。对于每个节点,根据其左右子树的三种可能情况进行状态转移判断。该算法巧妙地将空节点视为深度0的满二叉树作为递归边界条件,利用动态规划思想高效地统计满足条件的子树数量,时间复杂度为O(n)。文章详细解析了代码实现和三种情况的状态转移逻辑,并强调了满
这篇文章解析了一道树形动态规划问题,核心目标是以最小代价确保所有叶子到根的路径上至少有一个黑色结点。算法采用深度优先搜索(DFS)自底向上计算每个子树的最优解:对于叶子结点必须染色;非叶子结点则选择自身染色或子结点处理的较小代价。文中详细解释了状态转移方程、数据结构的必要性(如使用long long防止溢出),以及输入转换为邻接表的过程。最终通过DFS从根节点计算并输出全局最优解。该解法体现了树形
本文全面解析链表数据结构,从基础概念到工程实践。链表通过指针连接离散内存节点,形成逻辑连续的线性结构,具有动态扩容、高效插入删除等优势,但也存在访问效率低、缓存不友好等缺点。文章详细对比了链表与数组的特性差异,提供C语言实现的核心操作代码(插入、删除、反转、排序等),并探讨常见问题解决方案。工程实践部分介绍哑节点、快慢指针、跳表等高级技巧。链表体现了"逻辑连续不依赖物理连续"的
摘要:本文为软考系统架构设计师论文备考指南,从选题方向、项目准备到论文写作提供系统化方案。建议考生优先选择中大型项目(周期8个月以上)作为案例,无实际经验者可借助AI生成合理项目。重点讲解了摘要模板、背景描述、技术论述(微服务/云原生/大数据架构等)及结尾的标准化写法,强调需结合具体技术解决业务问题。提供高频考点(如Redis、高并发)的论述框架,并提醒避免模板化,应通过技术细节与真实场景提升论文
这篇题解介绍了USACO 2022年1月比赛的题目《Farm Updates G》。题目描述了一个农场管理系统,其中包含N个农场和Q次更新操作(停用农场、添加道路、删除道路)。关键是要计算每个农场保持"有关"状态的最大更新次数。题解提供了逆向处理的思想:从最终状态出发,倒序处理操作,使用并查集维护连通性,动态更新每个农场的活跃状态。给出的C++代码实现了这一算法,通过并查集和路
题目P8102「LCOI2022」Cow Insertion要求计算插入新奶牛Bessie后牛棚的最大开心值。牛棚原有n头奶牛,开心值的感染距离为m,每头奶牛有特定开心值a_i。Bessie的开心值为A,可以插入任意位置。牛棚开心值为所有长度为m的连续子序列中最大值的总和。 解题思路:使用单调队列预处理原数组的滑动窗口最大值,分别计算插入Bessie前后各位置的贡献。通过动态维护两个单调队列数组f
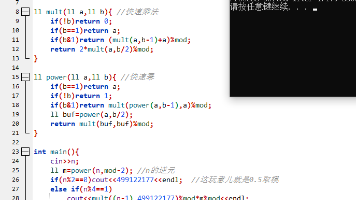
使用 dp[i][j] 记录子串 s[i..j] 通过任意加括号能得到的所有结果(范围 0~1000)。// 左子表达式 s[i..k-1] ,右子表达式 s[k+1..j]// 2. 区间 DP:长度从 3 开始,每次+2(保证子表达式合法)// dp[i][j] 存储子表达式 s[i..j] 所有可能的结果。// 默认上一次的运算符为 '+',这样第一个数字直接入栈。// 枚举运算符位置 k(
摘要:该题目描述了一个奶牛合并问题,Farmer John需要将多个牛棚的牛合并到一个牛棚中。每次操作需满足源牛棚的牛数≥目标牛棚的牛数。输入包含多组数据,每组给出牛棚数量和初始牛数。算法通过计算牛数的最大公约数和二进制特性判断可行性,并输出操作步骤。C++实现采用辗转相除和二进制分解策略,处理大规模数据时保证效率。对于不可行情况输出"NO",可行则输出操作序列。该问题考察了数
更新后继课程的最早完成时间。# dp[i] 表示完成课程 i 的最早时间。# 所有课程完成时间的最大值即为答案。# 构建图 (0-index)# 初始化入度为 0 的课程。# 拓扑排序 + DP。
栈有两种常见定义方式,核心是指定存储的数据类型和底层容器(默认用deque)。定义方式代码示例说明普通定义(默认底层容器)存储int类型,底层默认用deque容器指定底层容器分别指定vector、list作为底层容器注意:如果不指定底层容器,C++标准库会默认用deque——因为deque兼顾了vector的随机访问和list的高效插入删除,适合栈的操作场景。和栈类似,队列也需要指定数据类型和底层
题目摘要:该问题要求计算将集合{1,2,...,n}划分为两个子集S和T的方案数,满足条件|S|∉S且|T|∉T。输入为一个整数n,输出方案数对998244353取模的结果。样例显示当n=3时有2种合法划分方案。解题使用了组合数学和模运算,通过预处理阶乘和逆元来高效计算组合数。核心思路是当n为偶数时结果为2^n减去中间组合数,奇数时直接为2^n。代码实现了这一逻辑,并处理了n=1的特殊情况。
这篇文章讨论了魔理沙的计算器问题,涉及进制转换和数学计算。题目要求找出满足特定条件的正整数n的数量,即当计算1÷n后再计算其倒数时,结果仍等于n。输入包含多组数据,每组给出进制b和显示位数k。通过分析计算器的显示限制和数学性质,文章提供了C++代码实现,并解释了样例结果。最终答案需要对998244353取模,适用于编程竞赛中的数学计算问题。
C++11核心特性摘要(150字) C++11是现代C++的重要分水岭,其核心特性包括: 右值引用与移动语义:革命性优化拷贝性能,必须系统学习 lambda表达式:提供匿名函数对象,支持就地定义和变量捕捉,语法为捕捉列表->返回类型{函数体} 智能指针:自动内存管理 类型推导:auto/decltype简化编码 并发支持:线程库等 新特性学习优先级:先掌握核心特性,再根据需要学习C++14/
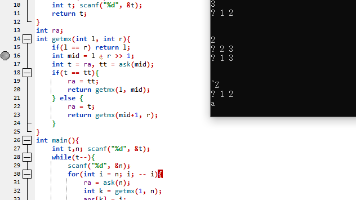
二分搜索(Binary Search),是一种在中查找特定元素的高效算法。二分搜索算法,实际上就是对一颗BST树从root根节点开始搜索的过程,每一次搜索只会沿着一条路径搜索下去:是每次定义索引left与right,每次找一个mid,比较mid索引的值与应找值val,之后缩小查找范围,循环操作,直到找到val或者循环结束。
本文介绍了栈和队列的基本概念及其模拟实现。栈是一种先进后出的线性表,通过数组模拟实现入栈、出栈、获取栈顶元素和判空操作。队列是一种先进先出的线性表,使用链表模拟实现入队、出队、获取队头元素和判空功能。两种数据结构在插入和删除操作上具有不同的特性,分别适用于不同的应用场景。文章通过代码示例和图示详细展示了栈和队列的具体实现过程及其操作方法。
重复循环遍历,每次比较相邻的两个元素,如果前大于后就交换,这样每次最大的元素都会交换到最后,每次循环遍历时去掉最后的元素。
这篇文章描述了一个关于声音共鸣度的算法问题。题目要求根据无序给出的所有子区间和,还原出原始的非递减序列。文章提供了两个输入输出样例,并给出了一个C++实现方案。该方案通过排序输入数据、使用桶计数和逆向计算的方法,逐步构建出原始序列。文章最后提到作者将持续分享算法竞赛相关的编程实现和心得。关键点包括:非递减序列重构、子区间和处理、桶排序应用、以及算法优化。
本文介绍了栈的基本概念、特点及常用方法。栈是一种遵循后进先出原则的线性表,主要操作包括压栈(push)和出栈(pop)。文章详细讲解了栈在编程中的实际应用:1)实现逆序打印;2)解决有效的括号匹配问题;3)判断出栈顺序是否合法;4)计算逆波兰表达式。每种应用都配有Java代码示例,如利用栈结构验证括号匹配、实现数组逆序输出等。这些示例展示了栈在算法问题中的典型使用场景,帮助读者理解栈"先
题目摘要:FJ有N个礼物和N头奶牛,初始将i号礼物分配给i号奶牛。每头奶牛有一个礼物偏好列表。奶牛们希望重新分配礼物,使得每头奶牛得到原礼物或更喜欢的礼物。对于每头奶牛i,求在重新分配后它能得到的最好礼物。 输入:N和N个奶牛的礼物偏好列表。 输出:每头奶牛可能得到的最好礼物。 样例说明:展示了如何根据偏好列表重新分配礼物,使某些奶牛得到更喜欢的礼物。 算法思路:使用Floyd算法计算可达性矩阵,
摘要:题目要求为N头奶牛(N≤10^5)建立最低成本的通信网络,每头牛位于(x,y)坐标,其中y≤10。连接成本为欧几里得距离的平方。由于N较大,常规方法会超时,需采用优化策略。解决方案利用Kruskal算法求最小生成树,并针对y坐标范围小的特点进行优化:先按x排序,然后对每个y值记录最近节点,从而减少边数。最终时间复杂度为O(N log N),适用于大规模数据。示例输入输出验证了算法的正确性。
红黑树是一种自平衡二叉搜索树,通过颜色标记和旋转操作维护近似平衡,确保操作时间复杂度为O(logN)。其核心特性包括:结点非红即黑、根结点为黑、无连续红结点、路径黑高相同。相比AVL树,红黑树旋转次数更少,适合频繁插入删除场景。插入操作需处理三种情况:叔叔为红时变色调整;直线型需单旋+变色;折线型需双旋+变色。验证时需检查颜色规则和路径黑高。红黑树广泛应用于STL、Linux内核等底层数据结构中。
堆部分基于数组实现完全二叉树,包含初始化、销毁、插入、删除等基础操作,重点解析向上调整 AdjustUp与向下调整 AdjustDown算法,并实现堆排序;二叉树部分采用链式结构,讲解前序遍历构建二叉树、节点个数统计、叶子节点计算、第 k 层节点数、树高求解、节点查找等基础功能,同时覆盖前 / 中 / 后序遍历、单值二叉树、相同树、对称二叉树、子树判断、翻转二叉树、平衡二叉树等高频算法题型,附完整
本文记录了作者从零开始学习链表的心路历程。文章从初学者的困惑出发,详细描述了理解链表概念的过程,包括节点结构、指针操作和动态内存管理等核心知识点。作者通过手动画图、逐行调试的方式,逐步掌握了链表的创建、打印、增删改查等基础操作,并分享了在实践过程中遇到的常见错误及解决方法。文章特别强调了指针操作顺序、内存管理和边界条件处理等关键细节,提供了完整的C++链表实现代码。作者总结了自己的学习经验,建议初
有一组数据在数组当中存储,我们默认第一个数为有序的,然后从他后面的数开始,先用一个变量把数据值保存,把这个数值在数组中对应的位置空出来,我们需要拿着这个数值和他前面的值一次进行比较,比较会出现两种情况:一、比前面的值小,前面的值要往后挪动到空位,又有新的空位,更新一下空位以及继续要比较的前一个数;,借助前后指针,一开始前指针指向key,后指针指向key+1位置,后指针指到的如果是小于key的值,前
想知道C/C++如何访问MySQL?看这一篇文章就够了!万字硬核详解
创建数组更快,因为它只是栈上的一块连续空间,无需动态内存分配。:在编译期就知道 N 是多少,替换进去,生成了两个不同的类。模板不仅能定义类型,还能定义常量。代码语言:javascript。代码语言:javascript。代码语言:javascript。代码语言:javascript。代码语言:javascript。代码语言:javascript。代码语言:javascript。代码语言:javas
这就像操作系统中的 I/O 调度:让耗时长的 I/O 操作(生长)尽早开始,这样在它生长的时候,CPU(你)可以去处理其他任务(播种其他花)。*对于每朵花,先更新 currentTime(加上播种时间),然后计算它的开花时间(currentTime + growTime[i])。// 这朵花的开花时间。1.按 growTime 降序排序:种子1(grow=3), 种子0(grow=2), 种子2(
这篇题解讨论了USACO 2022公开赛的一道图论题目,要求计算奶牛伙伴访问农场时能产生的最大快乐哞叫次数。题目将每个奶牛及其目标建模为有向图,通过拓扑排序和深度优先搜索处理环形依赖关系。算法首先用拓扑排序处理非环部分,累加所有可达节点的值;然后对每个环,找出最小值并从总和中扣除,确保最优解。最终输出最大可能的哞叫次数。样例输入输出演示了不同排列下的计算过程,展示了如何通过合理排序最大化结果。解题
题目要求判断给定字符串的多个子串是否能通过特定操作变为单个字符'C'。操作包括删除相邻相同字符或将一个字符替换为另外两个字符的排列。关键观察是:最终结果为'C'的条件是子串中字符'C'、'O'、'W'的出现次数的奇偶性满足特定关系。具体解法是预处理前缀和数组统计各字符出现次数的奇偶性,然后对每个查询检查奇偶性条件('O'和'W'的奇偶性相同且与'C'不同时输出'Y')。该方法利用位运算高效处理大规
本文介绍了题目「MCOI-08」Fill In REMATCH的解法。给定一个整数数组的部分前缀异或(p)和后缀异或(s)数组(部分元素被置为-1),要求恢复原数组。关键步骤是:1)通过未修改的p和s元素求出整个数组的异或总和sum;2)利用sum填补所有被修改的p和s元素;3)通过相邻p值异或得到原数组元素。代码实现简洁高效,时间复杂度为O(n),适用于大规模数据(1≤n≤1e5)。题目保证有解
摘要:题目描述了一个无向图中火种蔓延的过程,要求计算最少多少秒后会出现由被点燃节点构成的简单环。算法采用多源BFS遍历,记录每个节点的点燃时间,并通过并查集检测环的形成条件。当同一连通分量中两个相邻节点被不同时间点燃时,即可形成环,此时输出最小时间;若无环则输出"Poor D!"。代码实现了快速输入处理和高效搜索,适用于大规模数据。
一棵 AVL 树要么是空树,要么满足以下两个条件:其左子树和右子树都是 AVL 树;左子树和右子树的高度之差的绝对值不超过 1。这里的高度差通常记为平衡因子bf=右子树高度−左子树高度bf=右子树高度−左子树高度因此,任意节点的平衡因子只能取 -1、0 或 1。AVL 树是历史上第一种自平衡二叉搜索树,通过在每个节点上维护平衡因子(左右子树高度差)并在插入导致不平衡时执行四种旋转(左单旋、右单旋、
摘要: 题目描述Mirko在餐厅点餐的特殊定价规则:第一道菜支付A_i元,后续每道菜支付B_i元。要求对1≤k≤N的每个k,计算点k道不同菜品的最小花费。通过预处理三个数组(前缀和B_i、最小A_i-B_i差、后缀最小A_i),可在O(N log N)时间内高效求解。C++实现展示了排序和预处理技巧,样例解释验证了算法的正确性。该问题考察了贪心算法和预处理优化的应用。
这篇题解介绍了洛谷P8320『JROI-4』Sunset交互题的解法。题目要求通过不超过5500次操作还原一个1~n的排列,其中有两种操作:查询前缀最大值种类数和将某位置0。作者提供了C++实现代码,采用二分法逐步确定最大值位置,每次找到当前最大值后将其置零继续处理剩余部分。代码通过递归查找最大值位置,最终输出完整排列。文章包含题目背景、输入输出格式说明、样例解释和数据范围,并附有参考链接和实现代
这篇文章介绍了一个名为"绝对简单游戏"的编程题目。游戏规则是两个玩家轮流猜数字,猜中目标数字的人输。题目要求计算先手玩家rin的获胜概率,并以分数形式模998244353输出。文章包含题目背景、描述、输入输出格式、样例解释,以及一个C++实现方案。该方案使用快速幂和模运算来计算结果,特别处理了n为偶数、4k+1和4k+3三种情况。最后作者表示将继续分享算法竞赛相关的编程实现内容
本文系统讲解Java面向对象编程中抽象类、接口和内部类三大核心概念。主要内容包括:1) 抽象类的定义、特点(不能实例化、可含普通方法和抽象方法等)及使用场景,强调其"提取共性,强制子类实现"的作用;2) 接口作为"规则标准"的特点,包括多实现、默认修饰符及JDK8新增的默认方法和静态方法;3) 指出这些知识点对后续学习集合、设计模式等的重要性。通过代码示例展
本文介绍了C++中map/multimap容器的核心用法。map是基于红黑树的键值对容器,key唯一且自动排序,支持O(logn)的增删查操作。详细讲解了四种插入方式([]、insert(pair)、insert({})、value_type),迭代器和范围for两种遍历方法,以及查找、删除等常用接口。对比了map(key唯一)和multimap(允许重复key)的区别,指出实际开发中map使用频
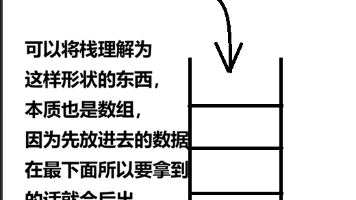
一种有次序的数据项集合,在栈中,数据项的加入和移除都仅发生在同一端,遵循后进先出原则。
AVL树,也叫二叉平衡搜索树,就是在BST树的基础上加了平衡操作(平衡的定义是任意节点的左右子树的高度差不超过1)。
本文详细解析了C++ STL中vector的实现原理与核心接口。文章首先介绍了vector的底层结构,通过分析STL源码指出vector使用三个指针成员(_start、_finish、_endofstorage)来管理动态数组。随后依次实现了vector的容器相关接口(size、capacity、empty)、元素访问接口(operator[]、at、front、back)、迭代器接口以及修改接口
一种有序列的数据集合,数据项的加入和移除发生在两端,遵循先进先出原则。
数据结构
——数据结构
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI硬件创业社区
AI硬件创业社区

 openEuler 社区
openEuler 社区









 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区