登录社区云,与社区用户共同成长
邀请您加入社区
本文是机器人强化学习的训练操作手册,详细介绍了训练全流程。主要内容包括:训练前必须激活conda环境;基础训练命令及参数说明(如headless模式、num_envs设置);训练监控指标解读;中断恢复训练的方法;模型保存路径;结果可视化工具play.py和TensorBoard的使用;标准训练流程及调参指南(参数修改原则、新旧实验对比)。手册还提供了常见问题解决方案和命令速查表,适合开发者快速掌握
文章摘要: 视觉-语言-动作模型(VLA)是具身智能的"大脑",通过统一编码视觉、语言和本体状态信息,实现物理世界的感知与行动。主流VLA采用"三路输入编码—Transformer主干—动作解码"架构,视觉编码从单塔发展为语义-细节双塔融合,动作生成从离散化转向连续流匹配等精细控制。核心挑战在于多模态动态融合,作者提出的MQN-DWG机制通过实时权重分配优化模态交互。当前VLA仍面临数据规模、实时
本文剖析了OpenClaw核心模块中的run-orchestrator.ts,这是嵌入式AI Agent的运行时编排引擎。该组件作为"总指挥",通过分层架构管理Agent完整生命周期:1)预处理阶段完成参数标准化、会话管理(复用/创建)、并发控制(Lane系统);2)核心流程包括工作区解析、插件加载、模型路由(含回退机制)、钩子执行(before-agent-reply);3)
具身模型面对的则是分散在物理世界中的视频、关节状态、力觉、触觉和动作轨迹,受到实时性、数据安全和现场网络条件的限制,7月24日,宇树科技与成都市达成战略合作,还有东风柳汽×优必选、上汽北京×逐际动力等——电力、汽车制造、工业园区等率先开放的场景,往往掌握在央国企、地方产业平台或大型企业手中。自变量、银河通用等独角兽则需要证明,模型可以通过自有或合作本体进入真实场景,让每一次部署产生可复用的数据,进
公司拟募资42.02亿元,其中约 85%(即 35.7亿元)将用于研发投入,重点投向:具身智能大模型及核心软硬件研发:计划投入超 20亿元,旨在补强机器人“大脑”(认知与决策能力);人形机器人公司星尘智能(Astribot)今年4月展示的AI机器人Astribot S1,是拥有全能操作能力的具身人形机器人,在多模态大模型的支持下,S1通过智能人机交互,可以自主完成叠衣、分拣物品、
本文梳理了当前AI领域最值得关注的十个方向,包括大模型算法与训练、具身智能与人形机器人、AI Agent与智能体开发等。文章指出,AI行业水位持续上涨,高薪岗位众多,但竞争也日益激烈。建议根据自身情况和兴趣选择合适方向,并注重技术深度和行业知识的结合。这两年总有人问我:学AI到底该往哪个方向走?问题背后是真实的焦虑。AI本身不是一份工作,它是一个横跨几十个细分赛道的庞然大物。选错方向,就像在高速公
《从Prompt到Loop:AI编程的范式迁移与工程实践》摘要 OpenClaw创始人提出应从人工Prompt转向自动化Loop设计,标志着AI辅助编程正经历五代演进:从Prompt Engineering(2023)到Graph Engineering(2026)。Loop Engineering通过控制论思想构建负反馈闭环,解决LLM概率模型的误差累积问题,实现"无人值守"
本文提出了一种基于文件系统的AIAgent永久记忆方案,通过"三层记忆架构"解决会话失忆问题。方案包含:1)公共MEMORY.md、USER.md和私有MEMIVATE.md三层文件结构;2)基于macOS xattr的四维标签索引系统;3)launchd定时自动化索引机制。在7个AI Agent协作的4天实践中,公共记忆精简71.6%,私有记忆总量达30KB,Token消耗降
别的工具只能做基础写作,Paperxie实现了本科毕业+硕博科研+期刊投稿全场景覆盖。多学科适配、公式绘图专业、双检合规稳定、免费福利充足,不管是应付期末结课论文,还是深耕科研投稿,一个平台全部搞定,学术效率直接翻倍🎓一站式学术写作平台👉Ai论文-PaperXie智能写作-Ai智能免费论文生成软件 - PaperXie智能写作PaperXie免费论文查重检测-首款免费论文检测软件,为毕业生提供
从 7 月 16 日发布 Kimi K3(2.8 万亿参数全球最大开源模型),到 F 轮超募 35 亿美元,再到 G 轮提前启动估值 500 亿美元——月之暗面用不到一个月完成估值从 250 亿到 500 亿美元的翻倍。微软大涨而同日 Meta 大跌,说明市场奖励的重点从"谁花钱多"转向"谁花钱能见到收入"——AI 投资从"规模叙事"切换为"盈利确定性"逻辑。——字节将飞书并入豆包、火山引擎整合
本文介绍了startAgentRunExecution函数,它是agent-run-handler第9阶段的实现,负责上下文组装和任务发射。函数采用双重准入锁机制确保执行安全,包含13个关键步骤:获取锁、中止检查、子Agent会话恢复、事件广播、消息标注、创建转录记录器、处理审批延续、解析插件授权、组装运行上下文和LLM参数,最后通过dispatchAgentRunFromGateway发射任务。
WAIC2026展会上,拔掉网卡的机器狗仍能精准执行任务,30万台量产车搭载SuperMate座舱系统交付,标志着端侧智能完成从"玩具"到商业落地的蜕变。7月手机厂商集体通过端侧AI备案,NPU算力突破使Gemma31B模型响应速度达云端水平。行业形成新共识:隐私数据"不出设备",端侧处理反射动作,云端负责复杂认知。中国企业在车机/机器人(面壁)、多模态(商汤)、Agent路由(腾讯)三线突破,依
本文介绍了双足人形机器人公司星动纪元的技术特点及面试要点。文章聚焦步态控制的核心问题,包括ZMP与CoP的区别、CapturePoint概念、实时平衡策略(踝关节/髋关节/迈步三层响应机制)以及地形适应方案。面试重点考察步态规划、动力学控制和抗扰动能力,需掌握DCM规划、WBC框架和倒立摆模型推导等核心技术。文章还提供了面试准备建议,包括阅读经典文献、搭建仿真模型和推导控制方程等。作为国内双足机器
要让一个人工智能模型控制汽车、机械臂、人形机器人和灵巧手,需要同时解决两个相互独立的问题。第一个问题是:这属于动作接口或动作表示问题。典型方案包括:第二个问题是:这属于模型主干架构问题。典型方案包括:这两个问题是正交的:动作表示≠Transformer 架构\boxed{\text{动作表示}\neq\text{Transformer 架构}}动作表示=Transformer 架构例如:本文先
AI Agent(智能体)乱战:2026年,我们离“数字员工”还有多远?四、信任鸿沟:距离真正的“员工”还差几步?二、理想丰满:那些“数字员工”的惊艳亮相。#多智能体生态#高光与实锤#工程化阵痛。五、2026展望:不是替代,是重塑。三、落地之痛:我们踩过的“坑”一、风口之上:百“体”争流。
Cosmos 3 希望用一个模型同时理解和生成语言、图像、视频、音频以及机器人动作。要做到这一点,它必须解决两个问题:第一,不同机器人、汽车和人体的动作格式完全不同,怎样把它们统一起来?第二,语言推理和视频、动作生成需要的计算方式不同,怎样把它们放进同一个 Transformer,又尽量避免互相干扰?Cosmos 3 对第一个问题给出的答案是“统一动作接口”:把各种原始控制信号转换为主体位姿、末端
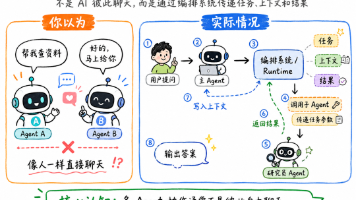
如果你用过 ChatGPT 或类似的 AI 工具,你的体验大概率是这样的:你问一个问题,AI 给你一个答案。看起来像是一个 AI 从头做到尾。
它提供了模型接入、运行环境、数据记忆和监控等能力,让你可以更简单地把 AI 功能接入现有业务,或者快速做出一个新的 AI 应用。
【摘要】AIAgent(智能体)并非简单的升级版聊天机器人,而是由四层工程结构组成的系统:1.Prompt层定义角色与任务;2.Context层管理记忆与信息筛选;3.Harness层提供API工具调用与验证;4.Loop层实现自主任务循环。这四层如同汉堡结构协同工作,使Agent从"被动应答"进化为"主动执行",支持复杂任务自动化。理解该架构可避免将Age
模型训练和系统开发应该并行推进。模型接口可以先使用模拟结果,待模型训练完成后再替换真实推理模块。2026 年深度学习毕业设计的选择很多,从图像分类、目标检测、图像分割,到文本分析、时间序列预测、推荐系统、语音识别,再到大语言模型与知识库问答,都可以形成完整的毕业论文。问题明确、数据可靠、模型可复现、改进有依据、实验可量化、系统可演示、论文讲得通。对于大多数本科生,推荐优先选择:目标检测;图像分类;
OpenClaw启动器使用指南摘要 OpenClaw是一款本地化AI智能体框架,通过PyQt5启动器简化部署流程。本指南详细介绍了从环境准备到日常使用的完整流程: 系统要求:需Windows 10/11系统、NVIDIA GPU(6GB+显存)、16GB内存和20GB存储空间 核心组件: Ollama(11434端口):负责本地模型推理 Gateway(18789端口):核心服务节点 启动器GUI
【Agentic RL / 强化学习 / OPD】OpenClaw-RL 源码阅读笔记 — (2)— On-Policy Distillation 一、引言:从策略蒸馏到 On-Policy Distillation在强化学习中,策略蒸馏(Policy Distillation)是一种将复杂教师模型的知识迁移到轻量学生模型的技术。传统蒸馏通常使用离线数据,但存在分布偏移问题——学生模型在训练时遇到
本章详细介绍了G1机器人模型的训练实践全流程。主要内容包括:1)训练前的环境激活与注意事项;2)训练命令解析及关键参数说明(如--headless、--num_envs等);3)训练过程中的指标解读(平均奖励、存活步数等关键指标);4)训练效果可视化方法(IsaacGym和TensorBoard);5)中断恢复训练的方法;6)常见问题调试技巧(奖励不增长、动作抖动等场景);7)模型导出与训练优化建
今天学长向大家分享一个毕业设计项目基于深度学习的图像修复算法 DCGAN生成对抗网络其实两个网络互相博弈,最终达到纳什均衡。这两个网络一个是生成器网络,它的目标接受随机噪声,不断训练生成假图片,为了方便叙述把生成假图片的函数记作G(z)。
对于运动区域(光流幅值大于0.8像素),采用交替引导滤波器迭代三次:第一次以可见光细节层为引导图,第二次以红外基础层为引导图,第三次取前两次结果的加权平均,权重由运动掩膜决定。进一步引入色调映射算子,基于融合图像的局部亮度均值动态调整对比度,公式为I_out = I_in / (I_in + sigma),其中sigma取全局亮度均值的1.2倍。针对红外基础层,引入最大类间方差指导的显著性权重图,
中国人工智能培训网—AI系列录播课
本文基于健康意识提升和个性化饮食需求增长,设计了一个智能饮食计划推荐平台。系统采用SpringBoot+Vue技术架构,后端使用Java开发,前端基于Vue框架,数据库选用MySQL。创新性地应用随机森林算法实现食物分类预测,结合协同过滤算法生成个性化饮食推荐。平台具备饮食计划定制、健康目标管理等功能,通过Echarts实现营养数据可视化。测试表明系统性能稳定,能有效解决传统饮食建议适配性差的问题
数据集中的数字图片是由250个不同职业的人纯手写绘制,包含了70000张图片,其中60000张为训练数据,10000为测试数据,70000张图片均是 28*28。optimizer.zero_grad()负责清零梯度,loss.backward()负责反向传播,optimizer.step()负责更新权重,这三步操作非常关键。torch.utils.data.DataLoader 是Pytorch
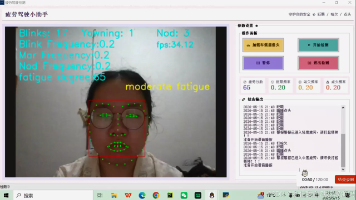
本文介绍了一个基于OpenCV多特征融合的疲劳驾驶检测系统设计与实现方案。该系统采用Python+OpenCV+Dlib技术栈,通过实时视频流采集驾驶员面部信息,融合眼部闭合度(EAR)、闭眼时间占比(PERclos)、嘴部开合度(MAR)和头部姿态四大特征进行疲劳状态判定。相比传统单一特征检测方法,该系统具有抗干扰能力强、检测精度高的优势,且无需改装车辆或加装专用硬件,仅需普通USB摄像头即可实
本文深入探讨了如何利用Tensorboard直方图诊断PyTorch模型训练瓶颈,超越传统的Loss曲线监控。通过分析权重和梯度的分布特征,识别梯度消失、爆炸等常见问题,并提供针对性的优化方案,帮助开发者更高效地调试和优化模型训练过程。
本文深入解析YOLOv5/v8模型中解耦头(Decoupled Head)与耦合头(Coupled Head)的设计差异与工程选择策略。通过理论分析、性能对比实验和实际场景考量,帮助开发者根据硬件资源、数据集特性和延迟需求做出最优选择,并提供了PyTorch代码实现和混合架构优化方案。
本文通过PyTorch代码实战详细解析了Shared MLP与传统MLP的核心差异,重点阐述了Shared MLP在点云处理中的参数共享机制及其优势。文章从实现原理、数学视角到实战应用,帮助读者彻底理解这两种结构的本质区别,并提供了性能优化技巧和高级应用示例。
在多输入多输出(MIMO)通信系统中,信道状态信息(CSI)的准确量化对于高效的数据传输至关重要。随着通信系统复杂度的增加以及对高速、可靠通信需求的增长,传统的 CSI 量化方法面临着诸多挑战。近年来,深度学习凭借其强大的特征提取和模式识别能力,为 CSI 量化提供了新的解决方案。特别是在时相关的 MIMO 信道环境下,利用深度学习进行递归 CSI 量化具有显著的优势。本文将深入探讨基于深度学习分
本研究设计了一个基于LSTM的股票走势预测系统,通过深度学习分析历史数据来预测股票价格走势。系统采用前后端分离架构,实现了数据预处理、模型训练、预测及可视化展示功能。实验表明,该系统能有效预测股票关键指标,为投资决策提供支持。未来可结合更多深度学习模型和大数据技术提升预测准确度,推动金融科技智能化发展。系统架构如图3-1所示。
🔥这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是🚩毕业设计 基于深度学习的新闻文本分类算法系统(源码+论文)🥇学长这里给一个题目综合评分(每项满分5分)难度系数:3分工作量:3分创新点:4分项
今天学长向大家分享一个毕业设计项目**毕业设计 基于深度学习二维码检测识别系统 **毕业设计 深度学习二维码检测识别二维条码/二维码(2-dimensional barcode)是用某种特定的几何图形按一定规律在平面(二维方向上)分布的、黑白相间的、记录数据符号信息的图形;
深度学习
——深度学习
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DAMO开发者矩阵
DAMO开发者矩阵
 智能体开发者社区
智能体开发者社区






 2048 AI社区
2048 AI社区







 AtomGit AI 社区
AtomGit AI 社区


 AI Agent技术社区
AI Agent技术社区



 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区