登录社区云,与社区用户共同成长
邀请您加入社区
为遵守国家网络实名制规定,未绑定将限制内容发布与互动
最直观且有效的手段是“数据增强”,通过对原始图像进行旋转、裁剪、缩放,或对文本进行回译、同义词替换,人为地制造出更多样化的样本,迫使模型学习更具鲁棒性的特征而非死记硬背。此外,早停法是一种极具性价比的策略,通过监控验证集的损失函数,一旦发现性能不再提升立即停止训练,从而将模型锁定在泛化能力最强的时刻。首先,解决欠拟合的核心在于提升模型的“容量”与特征的表达能力。同时,优化器的选择也影响深远,Ada
会议汇聚浙江大学、昆士兰大学、山东大学、宁波大学、浙江农林大学等国内外高校与科研机构的学术力量,设置主旨报告、专题分论坛、海报展示及 “我与主编面对面” 圆桌论坛等多种交流形式。由国际生态学协会、国际计算机学会、《ENGINEERING Agriculture》编辑部、AIEE 2026会议组委会主办,曲阜师范大学、山东省黄河下游湿地生态和生物多样性保育重点实验室承办的第一届人工智能与生态环境国际
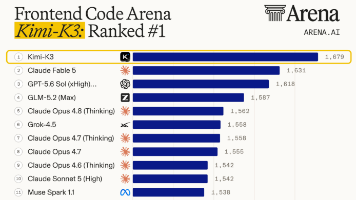
中国AI大模型Kimi K3横空出世:全球开源新标杆,编程能力登顶 2026年7月,月之暗面公司发布的Kimi K3以2.8万亿参数刷新全球开源大模型记录,在Artificial Analysis评测中以57.11分位列全球第四,超越Claude Opus 4.8。其核心突破包括: 百万词元长文本处理能力 原生多模态图像理解 编程能力全面领先(长程编程42分/程序设计77.8分均为全球第一) 8小
如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学AI大模型,就是冲刺高薪的最优解!零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风口的程序
开发者仅需三步、约30分钟即可在本地部署并运行AI智能体,该工具包还可与Omniverse平台结合,支持在本地完成AI智能体的构建、测试及3D仿真验证。据媒体报道,中国台湾地区正审议一项能源新规,拟要求用电负荷超过5兆瓦的大型商业用户自建发电及储能设施,预计将影响400多家半导体、光电子等企业及AI数据中心。该产品围绕芯片架构、关键算子、系统扩展和软件生态等方面进行了升级,同步支持全球主流大模型框
本文介绍了FastAPI框架中表单数据处理、异步编程、文件上传、请求对象和响应类型的核心用法。主要内容包括:1)使用Form处理表单数据提交;2)异步(async/await)与非异步编程的性能对比;3)文件上传的两种实现方式(小文件用bytes,大文件用UploadFile);4)通过Request对象获取请求信息;5)常见的响应类型(JSON、列表、文件等),并给出了企业级应用中的最佳实践示例
物理人工智能(PhysicalAI)技术综述与展望 PhysicalAI代表了AI从数字领域向物理世界的延伸,融合感知、推理与行动能力,实现真实环境中的自主交互。本文系统梳理了其核心技术架构,包括物理信息神经网络(PINNs)、具身智能、Sim-to-Real迁移及世界基础模型(WFMs),并对比分析了NVIDIA IsaacSim、MuJoCo等主流仿真平台的特性。
《SpringAI 2.0企业级应用开发指南》摘要:2026年6月,SpringBoot 4.1与SpringAI 2.0同步发布,标志着AI能力正式成为Spring生态核心组件。本文基于Java 21技术栈,演示如何构建包含三大核心能力的企业级AI应用:1)结构化输出功能通过JSON Schema实现类型安全的数据返回,支持自纠错验证;2)工具调用机制通过@Tool注解让AI执行实际业务操作;3
LLM 语义缓存是一种在大模型调用链路前置的"智能拦截层"——当用户发起请求时,系统先将输入文本转为向量 Embedding,在缓存库中检索是否存在语义高度相似的历史问题。若相似度达到设定阈值(如 0.95),则直接返回缓存的历史答案,跳过 LLM 推理环节;若未命中,才调用大模型生成新答案并回写缓存。这一机制的核心价值在于:大模型最贵的成本来自重复或高度相似的请求。
字节的“测试开发工程师-抖音研发”岗位,要求2026届本科及以上学历,扎实的数据结构和算法基础,熟悉至少一门编程语言(Java、OC、C、C++、Python、Go、PHP)。更前沿的“测试开发工程师-AI Platform”岗位,直接要求对AIGC技术有一定的理解和实践经验,包括AI Agent、机器学习、自然语言处理等。2026年的秋招,纯粹的手工测试岗位已经少得可怜。“熟悉软件测试流程”已经