登录社区云,与社区用户共同成长
邀请您加入社区
操作系统考试里,2分可能决定你能不能过线。而这几分别名题,纯粹是“知道就得分,不知道就送命”的记忆题。千万不要在考场上看到“管态”两个字一脸懵。现在记住了吗?内核态 = 管态 = 核心态 = 特权态 = 系统态用户态 = 目态。
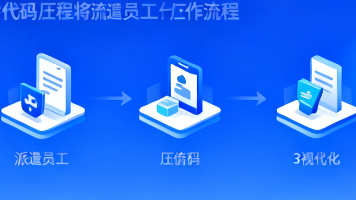
【摘要】派遣员工工伤申报常因信息断层导致超期风险:法定用人单位(派遣公司)与用工单位信息脱节,30天申报时效内材料收集困难。零代码解决方案通过三步优化流程:1)现场扫码报案,10分钟完成信息同步;2)系统化材料管理,自动核对缺失项;3)手机端审批流,审批时间从5天压缩至8小时。该方案通过二维码打破信息壁垒,看板追踪进度,将HR从"人肉追踪器"角色中解放,有效规避超期赔付风险。(
其实就是对以前文章的一个总结,单独再写一篇文章的原因是,自己对某些知识点有了一些理解,但最重要的一点是AI总结的比自己整理的简直是好太多了。
傅利叶智能聚焦康复外骨骼研发,其面试重点考察人机交互控制(如AAN自适应辅助策略)、力控制安全机制(三重冗余保护)及运动意图识别(sEMG信号处理)。外骨骼需根据患者残存能力动态调整辅助力度,通过阻抗模式确保安全性,并利用多传感器融合实现步态相位检测。面试要求掌握个性化步态生成、实时力控算法及意图识别技术,核心在于平衡康复效果与安全性。准备需研读AAN控制论文、阻抗控制理论,并实践sEMG分类项目
本文总结了跨平台开发专项面试的核心考点,涵盖Flutter、ReactNative和小程序三大方向。重点解析了Flutter的渲染管线与原生差异、PlatformChannel通信机制、Dart FFI性能优化;RN新架构Fabric的JSI改进和性能提升;小程序容器的沙箱隔离原理。文章对比了Flutter与RN的技术选型标准,探讨了状态管理方案和动态更新策略,并指出面试考察重点在于底层原理理解和
如果应用程序能执行特权指令“修改内存页表”,它就能把自己的“房间墙”打穿,直接去读你的微信聊天记录、去改你的浏览器密码。:假如你正在跟女朋友视频聊天(程序A),隔壁程序(程序B)执行了一条特权指令:“把CPU全部时间给我,切断其他程序。:处理完毕后,内核执行一条特权指令(此时它处于内核态,有资格),把PSW的状态位从“1(内核态)”改回“0(用户态)”,把控制权交还给其他应用程序。拓展:CPU 中
静态库(.a文件)是指程序在编译链接时将库的代码完整复制到可执行文件中,程序运行时不再需要外部库文件。静态库在链接阶段被直接嵌入到最终的可执行文件中,形成独立的二进制程序。动态库(.so文件)则采用不同的机制:程序运行时才去链接动态库代码。与动态库链接的可执行文件仅包含所用函数的入口地址表,而非整个目标文件的机器码。在程序执行前,操作系统将动态库从磁盘加载到内存,这个过程称为动态链接。特性静态链接
本文通过微信运行的实例,讲解了操作系统进程控制的四个核心操作:创建(申请PCB、分配资源、加载程序、进入就绪队列)、撤销(回收资源、删除PCB)、阻塞(等待事件时暂停运行)和唤醒(事件完成时恢复就绪状态)。重点强调了PCB作为进程身份证的关键作用,所有控制操作本质上都是对PCB状态的修改。文章最后对比了创建与唤醒的区别,并预告下一课将讲解CPU调度算法这一重要考点。全文以生活化比喻(如酒店退房)帮
面试官平均每天听到40-60个候选人说「我具有较强的团队协作能力」和「我是一个以结果为导向的人」。这些简历用语在面试中被说出来时,面试官的大脑会自动打上「套话」标签——不再认真听后面的内容。本文揭示了面试回答「官方生硬」的4层根因,提供了10组从官方套话到真诚表达的对照翻译——每一组都解释了「为什么真诚版更打动人」的心理机制。你还将看到如何借助鹅来面(OfferGoose)的面试提词和深度复盘功能
本文探讨了人形机器人感知系统的核心挑战与解决方案。针对视觉SLAM在动态环境中的实现难点,提出了高帧率相机、IMU紧耦合VIO等技术应对相机晃动问题;阐述了回环检测与重定位的关键算法;重点分析了语义场景理解的实现路径,包括3D语义地图构建和域迁移策略;最后介绍了动态障碍物检测方法。文章还提供了面试准备建议,强调对VIO框架和语义分割模型的深入理解。这些技术共同构成了人形机器人实现环境感知与自主决策
这篇文章摘要: 《流式Markdown渲染:AI时代前端的核心技术挑战》 摘要: 随着AI应用的爆发式增长,流式Markdown渲染从边缘场景演变为核心基础问题。文章剖析了这一技术挑战的深层背景:从ChatGPT引领的流式交互革命,到用户体验标准的迭代升级。作者将系统性地讲解从P5到P7的完整认知路径,包括流式数据结构、浏览器渲染机制、Markdown语法特性等关键技术点。系列文章采用问题驱动模式
本文介绍了嵌入式控制系统工程师在机器人运动控制中的关键作用,重点分析了EtherCAT通信架构、电机FOC参数调试和故障诊断三大核心技术。文章通过面试场景详细解析了EtherCAT的数据流机制、分布式时钟同步原理,以及通信异常处理策略;阐述了FOC电流环调参的标准流程和高速工况下的优化方法;最后提供了电机故障的系统化排查思路,包括通信检查、驱动器诊断和机械部件检测等。文中特别强调实践经验的重要性,
众擎机器人作为国内人形机器人领域的新锐,采用"高性价比+工程极致"路线,在嵌入式平台上实现高性能运动控制。其核心技术挑战包括:1)在算力有限的嵌入式SoC上优化WBC算法,通过自由度缩减、稀疏矩阵求解和并行计算将求解时间压缩到1毫秒内;2)动态调整任务优先级处理力矩饱和问题;3)采用显式MPC简化步态规划计算。团队通过参数辨识提升模型精度,结合实时操作系统确保控制稳定性。面试重
本文探讨了人形机器人全身控制的核心技术,重点分析了上下肢协调在多任务场景中的应用。主要内容包括:1)端水行走时通过角动量补偿或鲁棒步态策略保持平衡;2)多任务WBC架构设计中的动态优先级管理和平滑过渡机制;3)双臂搬运时解耦控制策略的应用;4)应对突发任务的快速反应式决策流程。文章指出,逐际动力面试注重考察候选人对可操作度椭球的理解和工程实现能力,建议通过仿真项目展示端物行走控制器的开发经验。该系
本文介绍了机器人步态强化学习的关键技术,重点探讨了奖励函数设计、Sim2Real迁移和训练工程三大核心问题。在奖励函数设计中,需平衡速度、存活、能量和姿态四个子项,其中存活奖励权重最大;Sim2Real迁移通过域随机化和teacher-student蒸馏解决仿真与现实的差异;训练工程方面,利用GPU并行加速,并通过成功率、性能指标和reward曲线评估策略。文章最后指出,准备面试需熟悉Legged
本文探讨了双足机器人地形感知与通过性分析的关键技术,涵盖实时障碍物检测、障碍物分类和可通过性评估三大核心方向。针对16线LiDAR和深度相机融合的场景,分析了50毫秒内完成点云处理的技术路径,重点介绍了CSF地面分割算法对斜坡地形的适应性。在障碍物分类方面,强调几何特征与语义信息的融合策略,并指出安全优先的保守处理原则。文章还详细解析了多维度代价地图的构建方法和多步前瞻的落脚点规划算法,包括在线重
《双足机器人步态规划:传统优化与强化学习的混合路线》 本文对比双足机器人步态规划的两种技术路线:传统优化(MPC+轨迹优化)和强化学习(RL),分析其优劣及混合架构的应用。传统方法基于线性倒立摆模型进行稳定性分析,通过MPC实时求解约束优化问题,但计算延迟显著;RL则通过仿真训练策略网络实现快速响应,但依赖奖励函数设计和Sim2Real迁移。逐际动力采用混合方案:RL生成基础步态,传统优化在线微调
看到了没?AI时代的安全架构,已经不是写写拦截器那么简单了。从意图审查到权限隔离,再到死循环熔断,每一环都是实打实的生产经验。掌握了这套架构思路,不仅面试横着走,真在线上跑业务你也能睡个安稳觉。大家在搞Agent的时候还踩过什么坑?来留言区,咱们一起盘盘!
从年初开始,我几乎每天都在用Claude Code或Cursor写代码。效率确实高了不少——以前要写半天的CRUD页面,现在二十分钟搞定。但最近发生了一件事让我警觉:同事问我一个和的区别,我张了张嘴,发现自己需要"想一下"才能回答。这个问题两年前我能脱口而出。不是我变笨了。是我把这块肌肉交给AI练了半年,它萎缩了。Anthropic最近的一项研究给了一个具体数字:重度依赖AI编程工具的开发者,独立
作为一个经历过无数次“技术面+HR面+交叉面”毒打的程序员,我深知面试不是单点战斗,而是一场多轮次的“系统游戏”。每一轮面试都有不同的“Boss”(面试官)、不同的“关卡目标”(考核点),以及不同的“技能树”(回答策略)。### 3. 高级:用大模型做智能评分与动态追问要把这个 Skill 变成真正好用的“面试外挂”,我们需要让 LLM 来评判回答,并基于上下文自动生成下一问。希望我的这个“面试外
根据最新检索结果,我为您整理了本周软件测试领域的热点面试题,涵盖传统测试与AI时代新兴测试方向。
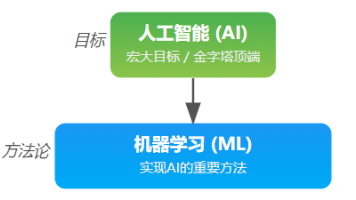
伴随而来的是一堆高频词汇:大模型(Large Model)、LLM(Large Language Model)、机器学习(Machine Learning)、深度学习(Deep Learning,虽然你没问,但它太重要了,我们也会提一下)、还有最新的智能体(Agent)……但当前语境下讨论的“AI Agent”,特别是“基于大模型的Agent”,则拥有前所未有的强大能力,因为它们的“大脑”是强大的
PAG (Portable Animated Graphics) 是一套完整的动画工作流。它提供从AE导出插件,到桌面预览工具,再到各端的跨平台渲染SDK,助力于将AE动画方便快捷的应用于...
大家好,我是狼王。今天,我们来聊一道常见的考题,也出现在腾讯面试的三面环节,非常有意思。具体的题目如下:文件中有40亿个QQ号码,请设计算法对QQ号码去重,相同的QQ号码仅保留一个,内存限...
校招很重要,应届生的身份很珍贵!在校招的时候与我们竞争的大部分都是没有工作经验的学生,而且校招企业对学生的包容度高,一般对企业来说,社招更看重实际工作经验,而校招更愿意“培养人”,校招招的是有基础,愿意学习的应届生;社招招的是有经验,可以直接上手的员工,相比较下来说,应届生更容易在校招中拿到优质offer。文档内容主要包括 HTML,CSS,前端基础,前端核心,前端进阶,移动端开发,计算机基础,算
在系统浏览器中输入这个网址,就可以自动下载 charles 证书,然后点击下载好的证书就可以直接安装了。iPhone 10 系统以上需要在 设置-> 通用 -> 关于本机 ->证书信任设置 中打开信任开关。在 charles 中出现的弹窗中,点击 allow,这样 charles 代理就设置成功了。在 charles 中出现的弹窗中,点击 allow,这样 charles 代理就设置成功了。通用
print(“当前线程:”, threading.current_thread().name)ifname== ‘main’:g_num = 0g_num = 0g_num = 0。
腾讯二面之细节大曝光中最后提到,22号晚上11:00先后分别收到邮件、短信与电话通知: 腾讯邀请你于4月23号16点到珞珈山国际酒店3楼2号会议室参加软件开发类面试,请携带简历提前5分钟到达。【腾讯科技】 23号上午,同样在旅馆查询资料,虽然很多人都说hr面很容易,但是我说过,我是同行人之中最早进行hr面的,无经验可借鉴,所以还得好好准备一下。只
独家:深圳腾讯总部大厦秋招运气比较好,拿到百度、阿里、腾讯、华为、360、美团、小米的(准)offer,不过都是意向书。。。。非正式。攒波人品,等国庆后的结果吧。本人本科211,硕士末流985。实力很渣,实验室项目也不行。全靠研二的时候,研三的师兄带路(他们工作确实找的好),他们分享他们的招聘经验、学习资料和方法等,还有就是研二的同实验室的同学的帮助也至关重要,所以研二这一年时间还算没...
文章摘要: 本文系统介绍了**AIAgent(智能体)**的开发流程,涵盖核心概念、环境搭建、工具调用、记忆管理、规划能力及实战案例。AIAgent区别于传统LLM,具备感知环境、调用工具(如API、数据库)、任务拆解与自主执行的能力。通过Python和LangChain框架,演示了天气查询、数据分析等Agent的实现,并集成短期/长期记忆(如对话缓存、向量数据库)和ReAct规划模式。
AI 会分析用户指令中的描述,比如“右上角的”“绿色的”“带购物车图标的”,然后结合 OCR 识别出的文字、元素位置、视觉特征进行匹配。它不是生成一串动作就结束,而是在“观察、决策、执行、再观察”的循环里,直到任务完成、失败退出,或者遇到必须交给人的节点。Computer Use 是 Anthropic 在 Claude 3.5 Sonnet 中推出的一项能力,让 AI 能够直接操作计算机,通过模
多智能体系统是由多个AI Agent组成的集合,系统中的每个Agent都有特定的角色和功能,这些Agent之间相互协作以实现单个或共享的目标。
本文面向背了大量八股文但面试时口头表达混乱的技术岗求职者,解决「知识点都会,但说出来就是一团浆糊」的核心痛点。你将获得一套从知识回顾到结构化口述的5步表达矫正法,理解 **ASR(语音识别)** + **NLP(自然语言处理)** + **LLM(大语言模型)** 如何在AI模拟面试中帮你把散乱的知识点串联成面试官能听懂的答案,并通过一个完整的211计算机应届生的实战案例看表达矫正前后的惊人变化。
本文介绍了双足人形机器人公司星动纪元的技术特点及面试要点。文章聚焦步态控制的核心问题,包括ZMP与CoP的区别、CapturePoint概念、实时平衡策略(踝关节/髋关节/迈步三层响应机制)以及地形适应方案。面试重点考察步态规划、动力学控制和抗扰动能力,需掌握DCM规划、WBC框架和倒立摆模型推导等核心技术。文章还提供了面试准备建议,包括阅读经典文献、搭建仿真模型和推导控制方程等。作为国内双足机器
这篇文章探讨了具身智能领域的策略泛化与迁移问题,聚焦机器人如何将已学技能应用于新场景。核心内容包括:1)跨任务泛化,强调通过视觉预训练(如CLIP/DINOv2)和数据增强使策略理解物体本质特征而非表面属性;2)少样本学习,介绍元学习(MAML和Transformer-based方法)和安全验证机制;3)策略迁移验证的三步流程(仿真测试、受控实验、现场验证)及性能归因分析。文章还推荐了相关面试准备
操作系统资源分配的最小单位进程是独立运行的程序,拥有独立内存空间、堆、文件资源,进程之间完全隔离。进程是资源仓库,线程是干活的工人。Java 线程一共6 种状态(面试必考,不是5种!NEW(新建)线程创建完毕,未调用 start(),未启动。RUNNABLE(就绪/运行中)正在 CPU 运行等待 CPU 时间片重点:Java 没有单独的 Running 状态!BLOCKED(阻塞)等待获取sync
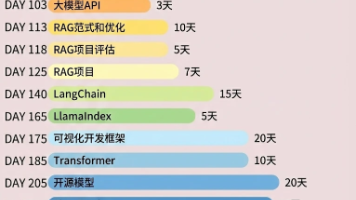
大语言模型很聪明,但它有两个天生的短板:一是知识有截止日期,训练数据之外的世界它一无所知;二是它会"一本正经地胡说八道",也就是我们常说的幻觉。当我们想让一个 Agent 回答"我们公司的报销流程是什么"或者"阿里云某个新产品怎么配置"时,纯靠模型的内部记忆基本上是靠不住的。RAG 正是为了解决这类问题而生的技术范式,它几乎已经成为今天每一个严肃的企业级 Agent 的标配。
当70%企业已在HR领域使用生成式AI,为何仅38%认为高度相关?真正的差距在于:AI面试的准确度,决定了招聘效率与人才质量的天花板。
AI工具正迅速改变程序员行业,初级岗位需求下降,效率提升却带来更多需求。未来程序员需从“写代码”转向“审代码”和“协调AI”,核心竞争力在于业务理解、复杂系统把握及解决关键问题能力。AI成本上升时,人类成本优势显现,但AI无法替代人类在1%细节上的完善能力。程序员需提升软硬实力,适应人机协作新趋势。码农的处境,或许也预示着所有知识型工作者的未来——当AI工具比人更擅长“做事”,人还能做些什么?AI
面试
——面试
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 openEuler 社区
openEuler 社区
 EazyDevelop社区
EazyDevelop社区

 2048 AI社区
2048 AI社区
 DAMO开发者矩阵
DAMO开发者矩阵

 开源鸿蒙跨平台开发者社区
开源鸿蒙跨平台开发者社区





 AtomGit AI 社区
AtomGit AI 社区








 智能体开发者社区
智能体开发者社区





 深开鸿 技术专区
深开鸿 技术专区









 AI Agent技术社区
AI Agent技术社区




 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区



