- @CSDN_430422
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
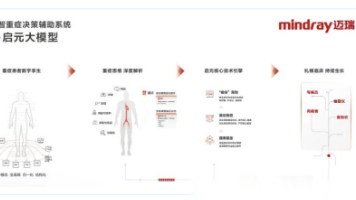
AI Agent:企业数字化转型的智能引擎 AI Agent作为具备自主决策能力的智能体,通过大模型+规划+记忆+工具使用的技术架构,正在重塑企业运营模式。相比传统AI和RPA,AI Agent能主动感知环境、拆解任务并调用工具完成目标。目前已在教育、政务、医疗等十大领域实现深度应用,典型场景包括教育行业的个性化学习平台、智能辅导系统,以及企业级的决策分析平台等。AI Agent通过自动化流程、智
OpenAI推出的o1模型家族颠覆了传统提示词工程规则,其强大的自主推理能力使原有复杂提示技巧可能适得其反。新模型强调简单直接的交互方式,无需思维链提示,仅需基础分隔符和有限上下文。这一变革引发行业热议,有人预测提示词工程或将淘汰,开发者需重新适应与高智商AI的自然对话模式。专家建议通过实验探索o1模型的新特性,同时指出初期可能存在技术缺陷需要调试。这场技术革新既带来了提示词工程师的转型挑战,也开
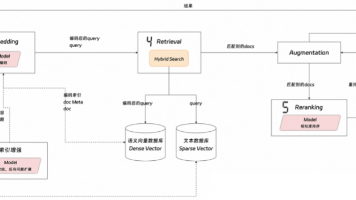
本文深入解析RAG技术全链路,从文档分块、索引增强、编码到混合检索与重排序五大环节,指出常将RAG视为黑盒导致问题定位困难。强调需结合具体场景对各模块进行调优,平衡召回率与精确率,并倡导从快速使用走向深度优化的实践路径,助力AI应用开发人员突破技术瓶颈。
2025 年 AI Agent 深度指南:从核心概念到落地应用,大模型开发者必藏
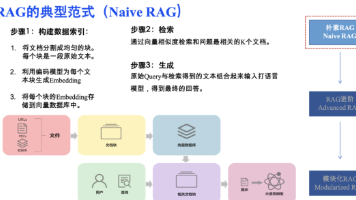
本文总结了企业级RAG系统构建的三个关键环节:文档预处理需根据业务场景优化格式转换与内容提炼;文档召回环节应优化问题表达并采用混合检索策略;生成阶段需整合文档内容并控制上下文。文章指出RAG系统从功能实现到质量提升需要持续优化,并分享了实际项目中的经验教训。最后附带了关于大模型学习资源的推广内容,包括学习路线、实战项目和面试资料等。
《零基础构建实用AI Agent的简明指南》摘要: 文章揭示了构建AI Agent的核心本质是"模型→工具→结果→模型"的简单循环,破除对Agent开发的神秘感。作者提供了清晰的可操作路径:从选择具体小问题开始,使用现成大模型,通过API实现交互功能,构建基础工作流循环。强调初期应避免复杂框架,优先实现核心功能,再逐步添加记忆系统和用户界面。实践建议包括小步迭代、控制功能范围,

【Java+AI应用开发指南】本文分享了Java在AI开发中的4大优势:丰富的生态框架、跨平台特性、高性能计算和庞大开发者社区。重点介绍了Deeplearning4j、Weka等5个主流框架,并展示图像识别、NLP等4类典型应用场景。提供2个实战代码示例(图像分类/文本分类)和3类学习资源(文档/课程/项目),帮助开发者快速掌握Java+AI开发技能。文末附大模型学习资料包。

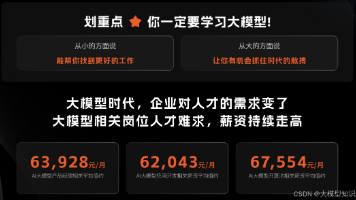
吴恩达指出,AI商业机会在应用层,智能体工作流是未来最具价值方向。他强调具体方案胜过模糊构想,快速验证创意是AI时代创业关键。AI编程助手大幅提升开发效率,编程成为新型表达力。开发者需关注技术模块组合,建立快速反馈机制。AI危险性被夸大,开源是创新护城河。执行力比创意更重要,团队执行速度与创业成功率强相关。今天,我想与大家分享一下在AI Fund积累的创业经验。AI Fund是一家风险投资基金,我

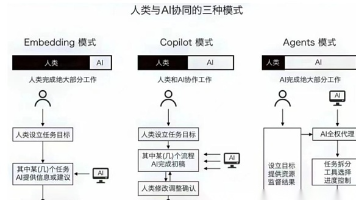
今天,我们把AI Agent这个概念,从它的核心构成(大脑、感官、手脚),到它的进化史(从AI 1.0到AI 2.0),再到五花八门的分类(按决策能力、技术实现、应用领域),可以说是翻来覆去地盘了一遍。信息量很大,可能会让人觉得有些复杂。但我想说,这恰恰是关键所在。理解这些看似繁杂的理论,不是为了让我们成为夸夸其谈的“专家”,而是为了给我们这些一线实践者,提供一个解决问题的“工具箱”和“作战地图”
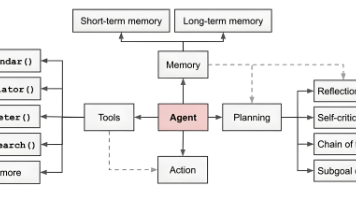
AI智能体能力分级与产业落地路径 报告将AI智能体划分为5个能力层级:L1基础响应(执行预设流程)、L2流程内自主(有限规划)、L3全自主决策(边做边优化)、L4环境驱动创造、L5组织领导。当前主流产品处于L2向L3演进阶段,能自主完成任务但关键环节仍需人工介入。 企业落地需关注:1)按任务复杂度选择场景;2)采用弹性调度+RAG+微调技术组合应对成本、模型幻觉等问题;3)通过安全护栏保障数据合规