登录社区云,与社区用户共同成长
邀请您加入社区
JDK 28 新增 jlink 证书裁剪插件,Quarkus 3.37.4 等多版本发布;Hibernate 7.4 逆向工程与 KotlinLLM 开源受关注,AI Agent 凭证代理与虚拟线程池化基准成热议。
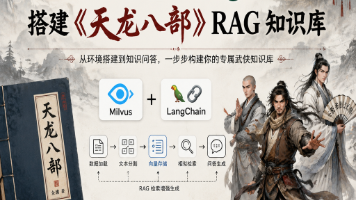
Milvus 是当前最主流的开源向量数据库,2.x 版本已完全云原生、生产可用,本教程基于编写,从环境搭建到可运行Demo全流程覆盖,新手10分钟即可跑通。
本文摘要:RAG技术仅能处理静态文档,而实际企业场景(如订单查询、库存管理等)需要动态数据调用。文章系统讲解如何通过LangChain的Tool工具和Agent智能体实现大模型与业务系统的对接。核心内容包括:1) Tool工具开发规范与参数校验;2) Agent运行机制(模型决策+工具调用+结果整合);3) 完整电商客服Agent实现(订单查询、库存检查、价格计算等)。重点强调企业级实践中的工程规
本文主要描述agent开发中的Plan-and-Execute模式,并且使用一个demo,彻底搞懂怎么在实际工作中使用Plan-and-Execute模式
我的开发方式是逐步完善整个网站(毕竟大家不是产品经理,没办法想好所有网站细节),这么做适合一开始不太清楚整体方案的情况,但是耗时比较长,大量内容需要推倒重来。
别再做 “语法正确但业务错误” 的 Text-to-SQL 了!本文记录数据分析智能体 DataWhisperer V3 完整升级:RAG 业务指标增强、Milvus 向量检索、全维度评测中心、产品化控制台、对话式交互。从 Demo 到可落地产品的演进思路,附开源地址与架构设计。
你是否曾幻想过,像问 ChatGPT 一样问一本小说:“段誉会什么武功?”然后它不仅能给出答案,还能告诉你这句话出自第几章?这就是 RAG(检索增强生成)的典型应用——把静态文档变成可交互的知识库。本文将带你从零开始,用 Milvus + LangChain 搭建一个“天龙八部问答机器人”。全文实战优先,不但给出可运行的代码,还会逐函数解析关键 API,并用 流程图 帮你理清整个流程。读完你不仅会
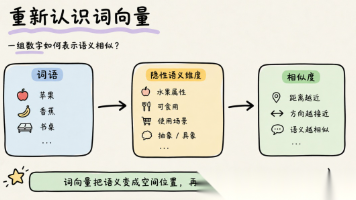
前面讲线性代数时,我们知道了:向量就是一组有顺序的数字。但到了自然语言处理里,问题会变得有点奇怪:
向量数据库实战不是“接了一个 search API”,而是要能把数据规模、索引参数、召回指标、延迟指标、内存账、写入抖动和线上排障讲明白。一个比较完整的回答可以这样说:回答模板:我们生产环境用 Milvus 做 RAG 向量检索,数据量约百万级 chunk,每条 1024 维,使用 HNSW 索引。上线前会基于 Recall@K 调 M、efConstruction 和 ef,线上重点看 P50/
系统中的文档解析与文本切分工具。系统通过edu_document_loaders目录下的专用加载器处理PDF、DOCX、PPTX及图像文件,利用PyMuPDF、python-docx等库结合RapidOCR引擎(支持GPU/CPU双模式)提取文本和图片文字。文本切分方面提供两种方案:ChineseRecursiveTextSplitter基于中文标点递归切分,保持语义连贯;AliTextSplit
我们的日记不仅有内容,还有日期、心情、标签等结构化字段。// 与embedding模型维度一致fields: [});这里用到了Array类型来存储标签,非常方便。向量数据库的核心概念与Milvus基本操作如何结合Embedding模型将文本向量化如何实现语义搜索和RAG问答我们构建的AI日记本只是一个起点,同样的架构可以应用到客服知识库、推荐系统、AI Agent记忆系统等众多场景。当AI拥有了
✅ 优点检索速度天花板,支持 CPU/GPU 加速索引丰富(FLAT、IVF、HNSW、PQ),可灵活取舍速度 / 精度无服务依赖,代码内嵌直接跑❌ 缺点无自动持久化,需手动保存 / 加载索引无元数据管理,文档、标签需要自己维护不适合频繁增删改的动态业务FAISS = 检索引擎:负责算得快,不管存、不管管,做底层内核、离线实验首选。Chroma = 本地玩具库:零配置无脑用,专注开发调试、原型验证
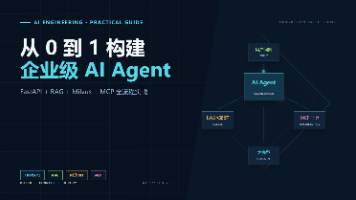
本文介绍了一个企业级AI助手系统的构建方法,整合了FastAPI、RAG、Milvus、Function Calling和MCP等技术。该系统具备三大核心功能:1)通过RAG从企业文档中检索信息;2)利用MCP协议调用外部业务工具;3)提供统一的HTTP对话接口。 技术架构采用FastAPI作为Web框架,Milvus存储文档向量,OpenAI兼容API处理自然语言理解,MCP标准化工具调用。文章
本文详细介绍了在Windows 11和M1芯片macOS系统上部署Milvus(2.4.4版)和Redis(7.2版)的完整流程。主要内容包括:1. 系统要求(硬件、软件和网络配置);2. Docker环境的安装与配置;3. Docker Compose文件的编写要点;4. 容器启动与验证方法;5. Python客户端连接测试;6. 常见问题解决方案。特别针对M1芯片提供了ARM64架构的兼容性说
将函数调用(Function Calling)与 LLM 相结合能够扩展您的 AI 应用的能力。通过将您的大语言模型(LLM)与用户定义的 Function 或 API 集成,您可以搭建高效的应用,解决实际问题。
像 GPT-4、Mistral Nemo 和 Llama 3.1 这样的 LLM 现在可以检测到它们需要调用函数时,然后输出包含用于调用该函数的参数的JSON。这使得您的 AI 应用更加通用和强大。由 LLM 提供支持的数据提取和标记解决方案(例如,从维基百科文章中提取人物姓名)可以帮助将自然语言转换为 API 调用或有效数据库查询的应用程序与知识库交互的对话式知识检索引擎Ollama:将 LLM
RAG,即检索增强生成,是一种通过整合外部数据源来增强大语言模型(LLM)的技术。一个典型的 RAG 应用包括:索引流水线(Pipeline):用于从外部数据源中摄取数据并对其进行索引,随后加载、拆分并将数据存储在 Milvus 中。检索和生成:将用户查询转换为 Embedding 向量,然后从 Milvus 中检索相关数据形成上下文,然后 LLM 上下文生成响应。文本将提供实用的操作指导,向您展
将函数调用(Function Calling)与 LLM 相结合能够扩展您的 AI 应用的能力。通过将您的大语言模型(LLM)与用户定义的 Function 或 API 集成,您可以搭建高效的应用,解决实际问题。本文将介绍如何将 Llama 3.1 与 Milvus 和 API 等外部工具集成,构建具备上下文感知能力的应用。01Function Calling 简介诸如 GPT-4、Mistral
(1)📢 Ollama安装deepseek-r1:7b> deepseek模型大小根据个人电脑的配置选择,最好是大于1.5b。Windows系统进入命令提示,通过ollama下载deepseek-r1:7b
基于llamindex、milvus向量库的RAG
解决:先在重启的机器上删除etcd,删除etcd的数据目录,并把 data 目录改为 1001:1001, 执行加入集群的命令,这是他会报错,去好的etcd节点连接上etcd集群,把之前下线的etcd成员id删掉,这是他就会重新生成新的成员id。问题:重新加入etcd集群的时候,加入的是已有的集群,加入命令要变,还要删除之前的成员 id ,否则就会一直报成员已存在,还要修改 data 目录的属性为
A:定义:ANN 旨在寻找“足够相似”的邻居,而不是“最相似”的那个。原因:KNN(精确搜索)需要计算查询向量与库中每一个向量的距离,复杂度为 O(N)O(N)。当数据量达到亿级时,耗时不可接受。ANN 通过预建索引(如聚类、图结构),牺牲极少量的精度(召回率),将搜索复杂度降低到 O(logN)O(logN) 甚至更低,实现毫秒级响应。A:后果:SDK 会直接报错,或者导致数据损坏/无法检索。
找到c的配置文件milvus.yaml,修改common.security.authorizationEnabled 设置为 true。可以通过 docker exec <container_id> -it /bin/bash 进入。可以通过vi或者nano编辑,如果都没有的话可以先复制到容器外面,改完再复制回来。然后找到configs下面的milvus.yaml文件。先进入milvus的dock
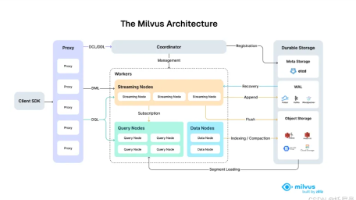
Milvus 提供强大的数据建模功能,使您能够将非结构化或多模式数据组织成结构化的 Collections。它支持多种数据类型,适用于不同的属性模型,包括常见的数字和字符类型、各种向量类型、数组、集合和 JSON。
RAG—文档解析——切片——入milvus向量库
文章写的很清晰 ,我这边做一下个人补充,初版可能只是配置,具体的grafana 监控报表后期补一下。values.yaml 配置enabled: true 改为true。生产的可执行yaml (可直接手动部署)
不同的向量类型可能会得到不同的检索结果,因此需要根据不同的场景选择合适的检索策略相似度检索是目前人工智能领域一个非常重要的应用场景,其不仅仅应用于人工智能技术,同样应用于搜索技术;比如搜索引擎,电商搜索等多种技术领域。因此,向量数据库也成为现在技术领域不可缺少的一个中间件;虽然说向量检索主要就是进行向量计算,不管是余弦,还是欧式距离等算法,目的都是通过计算向量之间的位置关系来确定相似度。但这里就产
这也是你插入数据维度与你创建集合的维度不一致导致的。
Attu是一款专为Milvus向量数据库打造的开源数据库管理工具,提供了便捷的图形化界面,极大地简化了对Milvus数据库的操作与管理流程。阿里云Milvus集成了Attu,以便更加高效地管理数据库、集合(Collection)、索引(Index)和实体(Entity)等的管理。Zilliz Cloud 中型数据集的起价为 0.148 美元,大型数据集的起价为 0.635 美元;Milvus CD
代码地址:github.com/milvus-io/milvusMilvus v2.6.8 在功能体验、性能表现和系统可靠性三个维度都进行了大幅增强,尤其是搜索结果高亮能力的引入,为文本检索场景带来了直观而实用的提升。配合大量深度优化与缺陷修复,该版本已经具备更成熟的生产可用性。
业务团队可能说他们想要个负重一吨,时速两百公里的马车……现如今,借助向量检索能力,实现基于语义相似度的智能搜索,已经是所有电商、推荐、社区平台技术架构的重要一环。作为拥有约 1.08 亿日活、 11 亿月活用户的兴趣内容社区平台, Reddit自然也不例外。自2024 年起,Reddit 各个团队就已经开始用不少方案来做近似最近邻(ANN)向量搜索。
milvus
——milvus
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI Agent技术社区
AI Agent技术社区

 AI编程社区
AI编程社区


 快递鸟社区
快递鸟社区


 智能体开发者社区
智能体开发者社区



 AtomGit AI 社区
AtomGit AI 社区





 2048 AI社区
2048 AI社区


 openEuler 社区
openEuler 社区