登录社区云,与社区用户共同成长
邀请您加入社区
如果说2025是AI Agent智能体元年,想必2026将会是AI Agent真正商用化的开端,而AI Agent商用化的前提是各行各业开始落地实际商业领域的AI Agent。
Headroom:AI Agent 上下文智能压缩工具 Headroom 是一个本地优先、可逆、内容感知的 LLM 上下文压缩层,专门针对 AI Agent 开发中的 Token 浪费问题。它能智能识别并压缩送入大模型的各种冗余内容(工具输出、日志、代码片段等),平均可节省 60-95% 的 Token 消耗。 核心特点: 三层压缩管线:自动路由内容到最佳压缩器(JSON/代码/文本) CCR 可
《18岁高中生用旧卫星数据发现150万天体:AI下一站是"范式革命"》摘要 2024年,一位高中生利用退役卫星数据发现近150万个未编目天体,揭示了当前AI发展的关键瓶颈。尽管AI普及速度惊人(中国生成式AI用户两年达6.02亿),但现有大语言模型仍局限于处理人类已有文本知识,无法主动探索未被文字记录的原始科学数据。阿里云王坚提出"范式变革"——将科学数据提
高度重合风险:AscendKernelGen已完整覆盖本方案全部诉求(32B基座、CoT数据集、SFT+RL训练、昇腾内核生成),若跳过基线评测直接从零自研,存在严重重复造轮子问题,技术评审、对外成果输出均存在短板;方法论统一:全赛道SOTA项目均采用两阶段训练,原方案仅SFT单阶段存在明显技术缺陷,必须补充RL执行反馈环节;数据集对标:Ascend-CoT v3样本量级、场景覆盖度远超本方案初始
传统外呼机器人(2024年及以前的产品)主要进行“按键播报”式单向沟通——播放固定话术、客户按键选择。客户一旦打断或反问,系统即“死机”或跳转人工。具备深度多轮对话能力的系统(如众湃云呼支持8轮+上下文记忆)可以处理打断、反问、模糊表达、情绪波动等复杂交互场景,大幅提升客户体验和意向识别准确率。在2026年的市场环境中,不具备多轮对话能力的产品已属于“上一代技术”,不建议采购。众湃云呼。
2026世界人工智能大会(WAIC)在上海圆满落幕,展现中国AI产业强劲发展势头。本届大会吸引超40万人次现场参与,意向采购额达203.6亿元,同比增长25%。上海人工智能产业规模2025年突破6370亿元,增速达39.5%。三大展区联动呈现完整产业链,国产算力集体亮相,具身智能实现"真机上岗"。长三角协同发展成果显著,发布应用清单并签约三大跨域平台。大会期间签约409亿元重点
【摘要】2023年AIAgent成为AI领域热点,标志着AI从被动响应转向主动执行。其核心架构包含感知、推理、执行和记忆四大模块,其中推理模块尤为关键。主流实现基于ReAct框架,通过"思考-行动"交替机制保持任务逻辑一致性,但仍面临工具调用准确性、参数生成等挑战。AiPy采取"人机协同"的务实路线,结合联网搜索、代码执行和图片生成三大能力,通过引导式交互控
2026年管理岗与技术Leader面试完整备战策略:拆解团队管理、技术战略、跨部门协作、招聘培养四大评估维度,实测鹅来面OfferGoose、ChatGPT、牛客、脉脉、面试猫5款AI工具在管理者面试场景中的表现,提供可落地的叙事切换方法和工具选型方案。
份额重构:ChatGPT MAU 突破 11 亿,但全球市场份额从 2024 年 3 月的 81% 跌至 46.4%——"一家独大"时代正式终结。Claude 以 640% 年增速达到 2.45 亿 MAU(10.3%),Gemini 以 132% 增速达到 6.62 亿 MAU(27.7%)。三家合计占据 89% 的使用时长。收入反超:Anthropic Q1 2026 全球 LLM 收入份额
零基础认识大语言模型(LLM)工作原理(16.未来的大模型与 AI Agent:从模型竞争到系统竞争)–结尾篇 引言:从模型到系统的转变在过去的几年里,大语言模型(LLM)的竞争主要集中在模型本身的参数规模、训练数据和计算能力上。然而,随着技术的发展,我们正见证一个重要的转变:未来的竞争不再是单一模型的比拼,而是整个AI系统生态的竞争。这一变化的核心在于AI Agent(智能体)的兴起,它将LLM
最近在 Windows 系统上体验 OpenAI 官方推出的Codex 编程客户端,准备安装 Windows 桌面版本。按照官方流程下载时发现,Windows 版本默认跳转到Microsoft Store(微软应用商店)。微软商店打不开Microsoft Store 无法登录搜索不到 Codex 应用提示「此应用当前不可用」点击安装按钮没有反应地区限制导致无法下载经过测试发现,Codex Wind
二、skill的引入→sop操作形成plugs。一、工作流的引入→skill的建立。四、memory形成神经网络大脑。
AI辅助论文写作:工具组合与协作策略 当前,通用AI工具(如ChatGPT)在论文写作中存在格式混乱、文献虚构、学术深度不足等问题。为提升效率并确保学术规范,需建立系统化的AI协作流程: 工具组合: 文献管理(Zotero/Semantic Scholar)用于收集与筛选文献。 大纲设计由AI生成草案,经人工迭代优化。 专业工具(LaTeX/Scrivener)规范格式,嵌入AI生成的素材块。 查
未来几年,中美AI竞争,很可能不是谁取代谁,而是两种不同的发展路径:美国负责突破AI能力边界,建设全球AI基础设施。中国负责让AI深入千行百业,让每一个专业人士都拥有自己的Agent,把AI真正变成生产工具。如果说上一轮互联网竞争,比的是谁拥有更多用户。谁能够最快地让千万个Agent,在千万家企业中真正创造价值。也许,这才是"一人公司"战略背后,更值得思考的意义。
线下销售的难点,常常不在于企业没有SOP,而在于管理者无法持续了解SOP是否执行、客户反馈是否被记录、员工能力是否得到复盘。线下流量成本上升后,门店接待仍停留在抽查录音、人工巡店和结果考核,销售过程就容易成为经营黑盒。智能工牌的价值,是把现场沟通转化为可检索、可分析、可复盘的数据,再用于话术质检、客户画像、成交归因和培训优化。在销售过程留痕、SOP质检、复盘管理这类诉求下,明略科技 · 灵听工牌值
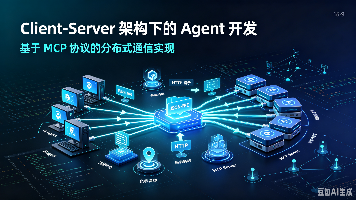
MCP协议:AI Agent与企业系统的标准化桥梁 MCP协议(Model Context Protocol)为解决AI Agent与企业业务系统集成难题提供了标准化方案。该协议通过三层架构(Host、Client、Server)实现智能体与外部系统的解耦交互,支持Stdio和HTTP with SSE两种传输方式。核心原语包括Tools(可执行操作)、Resources(结构化数据)和Promp
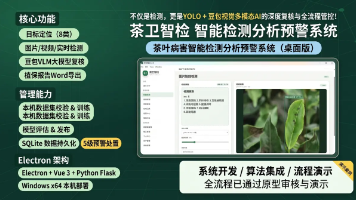
本项目是一个基于人工智能技术的茶叶病害检测分析预警系统,旨在通过计算机视觉与深度学习模型,为茶园与鲜叶质检场景提供叶片病害、虫害征状与健康状态的识别与预警服务。系统集成了图片检测、视频检测、实时检测、模型评估、模型管理、数据集管理等多项功能,构建了一个完整的茶叶叶片目标检测与植保辅助决策服务平台。
本文对比评测了六款主流AI合同审查工具在处理技术合同时的表现。作者以12条款技术服务合同为样本,重点考察条款识别、修改建议、立场适配和办公集成等维度。百度文库「超能合同」在立场定制和Office生态衔接上表现突出,支持甲方/乙方视角选择和Word/PDF导出;幂律智能提供结构化风险报告,秘塔科技采用对话式交互,法天使侧重模板对比,合通支持双语校验,ChatGPT则适合技术用户自建Prompt。作者
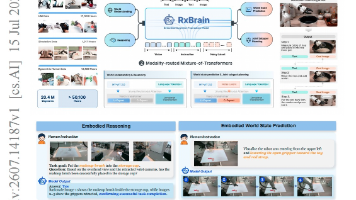
如何弥合视觉语言模型擅长抽象推理但缺乏物理状态想象,与世界模型擅长预测未来但缺乏因果逻辑之间的鸿沟,从而实现真正的具身认知?论文提出了RxBrain,一种具备联合语言-视觉推理与想象能力的具身认知基础模型,通过统一的混合Transformer架构,在单一规划序列中互补地结合文本逻辑与视觉状态预测。
2026世界人工智能大会(WAIC2026)在上海落幕,释放三大产业信号:AI从参数比拼转向落地交付,国产算力加速自主可控,智能体与具身智能成为焦点。大会达成203.6亿元意向采购,华为、中科曙光等展示十万卡级算力集群,阶跃星辰、百度等推出智能体产品,智元机器人等实现工业场景落地。但行业仍需警惕估值泡沫、具身智能瓶颈及中美算力差距。AI正从实验室走向实际应用,务实落地成为关键。
道翰天琼认知智能机器人平台API接口大脑为您揭秘。2019 年华为开发者大会的现场,华为消费者业务 CEO 余承东宣布正式推出华为操作系统鸿蒙 OS,并宣布正式开源。一年后,正值危难时刻的华为,能否靠鸿蒙扭转颓势?麒麟芯片数量有限,华为手机业务面临挑战近日,余承东向媒体表示:麒麟 9000 芯片,只生产到 9 月 15 号,还会上市,但是数量有限。9 月 3 号在德国柏林进行的 IFA2020 上
对于硕博研究生而言,百考通是完成学位论文、冲刺核心期刊的得力助手:无论是理工科的实验研究论文,还是文科的案例分析论文,都能快速生成高质量初稿,节省大量选题与写作时间,让学生聚焦于研究创新而非文字堆砌;对于科研工作者,平台是加速成果发表的高效工具,规范的格式与严谨的内容能提升投稿命中率,缩短发表周期;AI不仅能优化语言表达,让内容更专业严谨,还能补全逻辑漏洞,确保论文从引言、文献综述、研究方法、结果
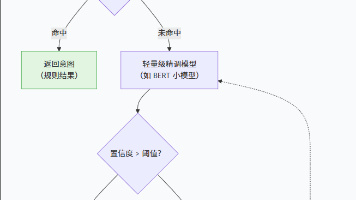
《智能客服进化史:从正则表达式到GPT的实用主义架构》 文章回顾了NLP技术的演变历程:从规则时代的穷举if-else(如ELIZA机器人),到统计时代的特征工程与分类器(如SVM),再到深度学习的预训练模型(如BERT),最终进入大模型时代(如GPT)。尽管GPT展现出强大意图识别能力,但实际生产环境中,纯依赖大模型会导致高昂成本、延迟和不可控风险。作者提出"漏斗架构"解决方案: 规则层处理高频
本文将详细介绍Ollama项目的背景、技术细节以及如何实现在本地运行这些大型语言模型。
在Zero-Shot/One-Shot/Few-Shot场景下,ChatGLM3-6B的推理表现
学习如何使用在ChatGLM3模型下,实现Function Call的功能
自然语言处理
——自然语言处理
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 智能体开发者社区
智能体开发者社区



 AtomGit AI 社区
AtomGit AI 社区


 人工智能6S服务平台
人工智能6S服务平台
 DAMO开发者矩阵
DAMO开发者矩阵




 AI编程社区
AI编程社区



 CSDN-OPC开发者社区
CSDN-OPC开发者社区



 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区




 HarmonyOS开发者社区
HarmonyOS开发者社区

 2048 AI社区
2048 AI社区