




- @Trb201013
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了AI大模型提示词工程(Prompt Engineering)的实战技巧。主要内容包括:1. 封装通用OpenAI对话函数,测试temperature参数对回答随机性的影响;2. 通过添加System Prompt定义模型角色,提升回答质量;3. 提供Prompt优化方法论,如使用分隔符、角色扮演、输出约束等技巧;4. 介绍进阶优化方法如少样本提示。文章通过代码示例展示了如何从简单Prom
摘要 本文详细介绍了如何在个人计算机上本地部署DeepSeek R1大模型。作为一款2025年初发布的轻量级AI模型,DeepSeek R1突破了传统大模型对高性能硬件的依赖,仅需8GB内存和30GB磁盘空间即可运行。文章从数据隐私保护、定制化需求等角度阐述了本地部署的优势,并提供了完整的部署流程指南,包括Ollama安装、模型下载、Python环境配置等关键步骤。特别针对Windows10用户,
在当今数字化时代,人工智能(AI)已经成为推动各行各业创新的核心力量。越来越多的传统产品开始向智能化转型,AI技术的应用不仅提升了用户体验,还为企业带来了巨大的商业价值。作为产品经理,如何将传统产品转变为AI产品,并在这个过程中实现个人的职业转型,成为了许多人的关注焦点。本文将结合实际经验,为您详细解析AI产品经理的工作流程、学习路径以及成功的关键要素。无论你是刚刚接触AI的新手,还是已经在传统产

这篇文章分享了作者从零开发AI Agent系统的实践经验与反思。文章首先对比了封装框架与底层开发的优劣,详细记录了使用LangChainGo和LangGraph框架时遇到的文档缺失、API不稳定等问题,特别分析了流式返回、ReAct节点等核心功能的设计差异与实现挑战。作者还反思了过度依赖AI编程导致的能力退化现象,提出"人机协作"的平衡建议。最后总结了Agent开发的关键学习点

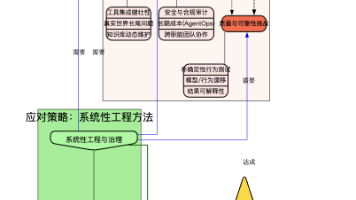
本文揭示了将AI代理(Agent)从原型转化为实际产品过程中面临的十大工程挑战,包括需求模糊性、外部系统集成成本、非确定性测试难题、安全合规要求、运维复杂性、跨学科团队组建、知识库管理、长尾问题处理、持续成本结构等。文章指出,企业往往低估了AI代理落地的实际工程量,需要建立可观测性、分层架构、AgentOps团队等系统性解决方案,并强调长期维护成本远超开发成本。最后提供了从需求边界到合规预研的七项
过去,我们用AI,像是使用一把瑞士军刀。你说一个指令,它执行一个动作。而GPT-5的目标,是成为你的“自动导航汽车”——你设定目的地,它自己规划路线、应对路况、直至抵达终点。这就是 “智能体工作流”(Agentic Workflow) —— GPT-5最核心的进化。在官方指南中,OpenAI花了大量篇幅教开发者如何“管理”这位新员工。

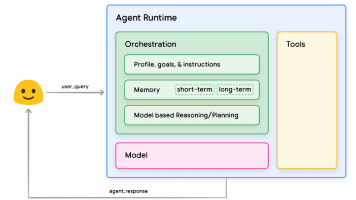
本文深入解读了AI智能体从实验室到生产环境落地的三大核心逻辑。首先剖析了AI智能体的三大构成要素(模型、工具、编排层),其次阐述了智能体运营方法论(工具管理、步骤追溯、持续优化),最后提出了多维度的智能体评估体系(基础能力、做事步骤、评分机制)。文章还探讨了多智能体协同的价值,并介绍了谷歌AI联合科学家等成功案例。全文强调AI智能体落地需满足体系化、可评估、善协作三大特性,为读者提供了理解AI智能
AI产品经理与传统产品经理在思考框架上相似,都需要经历产品全生命周期管理,但思维模式不同。AI产品经理以技术为驱动,需深入理解数据、算法及场景应用。根据公司类型可分为AI公司和非AI公司两类,岗位要求各有侧重。此外,AI产品还可按使用群体分为ToB(侧重业务效果)、ToC(侧重用户体验)和AI硬件(侧重场景运维)三类。核心技能要求除通用产品能力外,更强调对AI技术、数据及效果评估的理解与应用能力。

成为一名优秀的AI产品经理,需要具备深厚的技术背景、良好的产品直觉、敏锐的市场洞察力以及出色的沟通协调能力。以下是一份详尽的AI产品经理学习路线,旨在帮助有意进入该领域的学习者建立起坚实的基础,并逐步成长为行业内的专家。

AI Agent与传统聊天机器人有本质区别,它具备记忆、思考和工具调用能力。构建高效AI Agent需三大核心要素:精细的prompt设计(明确任务边界和完成标准)、有效的Memory管理(保持上下文一致性)和实用的Tools设计(标准化专业化工具)。本文通过实战案例分享开发经验与避坑指南,帮助开发者快速掌握AI Agent构建技巧。
