登录社区云,与社区用户共同成长
邀请您加入社区
AI daily news: Qwen3.8 open-source, GPT-5.6 math breakthrough, open-source speech recognition boom
2026 世界人工智能大会“世界模型 ‘六小龙’ 巅峰论坛”上,大晓机器人重磅完成三大核心成果发布:开悟世界模型 3.1(Kairos 3.1)、环境式数据采集方案 2.0,以及覆盖三大垂直场景的成套解决方案,为物理 AI 落地提供完整技术底座。
2026 年 7 月 16 日,GOAI 世界人工智能开源大赛(Global Open-source AI Challenge)官方网站 goaihz.com 正式上线,报名通道面向全球开放。
它真正做到了让非技术人员也能参与到数字化创造中来,这种零代码+AI驱动的模式,和我们传统认知里的“AI开发”已经是两回事了,它更像是一种普惠化的AI应用能力。魔搭和LlamaFactory在“模型层”,Dify在“编排层”,而LynxCode则在“交付层”,它直接面向最终用户和业务场景,提供的是开箱即用的应用。15. 特点:这个工具的理念非常超前,它跳出了“AI开发工具”的传统范畴,定位是一个“对
配合auto mode和动态工作流,把长活儿全自动串起来:每小时扫一遍反馈频道,收到一份bug报告,就自动分诊、修复、回复,一条龙跑完,全程不停下来问你要权限。有些活得盯着外部系统,最简单的办法就是按时间间隔去查一眼,看变了什么再反应,比如一个可能收到评审、也可能CI挂掉的PR。每次Claude想停,一个评估器模型就来对照你的标准,没达标就打回去接着干,直到目标达成,或者用光你设定的轮数。Clau
它成为了新的软件入口,进入了金融、法律和设计等专业场景。GPU 继续推理,而 CPU 维持并发环境、管理任务队列和工具调用,KV和内存保存每个 Agent 的沙箱、日志与中间结果,而网络负责在芯片和服务器之间送数据。想做金融,那就MCP接上通用金融数据库,再配上估值方法、合规流程这套东西skill,每个相应的工作人员都可以用,在需要啥自己稍微添加一下就行。因为在OpenAI自己的报告里,仅仅4-5
欢迎小伙伴们预约观看,参与互动答题赢CANN周边礼品,不容错过,我们直播间见~
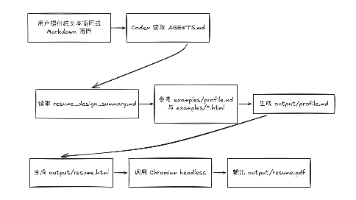
这个开源项目提供了一种高效制作简历的本地工作流解决方案。它通过将简历内容与样式分离,让用户专注于文本编辑而非格式调整。核心流程包括:用Markdown管理简历内容,基于预定义模板生成HTML,最后通过Chromium headless导出标准化PDF。项目特色在于轻量化、可复用性强,并支持纳入代码管理流程,适合习惯命令行和版本控制的开发者。虽然功能简单(不是多模板平台或可视化编辑器),但通过明确的
当下Codex、Claude Code等各类Agent层出不穷,但绝大多数产品仍停留在预训练+固定提示词+静态工具的模式,模型上线后能力冻结,交互产生的经验无法沉淀复用,每一轮对话都是重复从零推理。
AI编程工具GrokBuild因默认上传开发者完整代码库(包含敏感数据)引发隐私争议。SpaceXAI虽采取开源代码、关闭数据收集等措施补救,但禁用GitHub协作功能的行为暴露"伪开放"本质。这一事件揭示AI工具面临的核心矛盾:模型需要海量数据与用户隐私诉求的冲突。真正的信任重建需要透明代码、可控的数据策略和开放的社区参与机制,而非危机公关式的有限开放。开发者需警惕工具变相成
7月18日,在2026世界人工智能大会(WAIC)上,商汤科技正式发布了大模型家族的重量级旗舰新品——SenseNova U1 Pro。作为“日日新 SenseNova U”系列的旗舰版本,U1 Pro 定位为面向长程任务的交付级原生多模态智能体基座,实现理解、生成和行动的深度统一。
AI Agent在业务操作中的身份认证与授权问题,指出仅凭模型输出无法建立可信行动主体。文章分析了三种身份(请求发起者、Agent客户端身份、行动业务主体)的区别,强调模型参数中的user_id存在安全风险。作者提出可信身份应来自系统边界而非模型文本,并建议通过ACC的subject.required声明来确保能力调用前已具备可信主体。最后指出可信主体仍需业务系统进行最终授权,且主体需与任务、参数
【CANN新手村任务】CANN社区新开发者基于使用CANN、体验代码仓或学习CANN课程,首次通过issue、pr、答题、社区互动或文章等方式反馈有价值意见、建议、需求、报错、成果等。SIG 面向机器人操作、运动控制与导航开发者,VLA、世界模型及 3D 视觉研究者,CANN 模型训练与部署开发者,以及高校实验室和机器人企业,围绕昇腾平台建设开放易用、可复现、可迁移的具身智能应用生态。成员单位:南
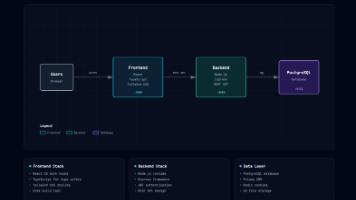
摘要: GitHub热门项目Architecture Diagram Generator(6000+星标)通过Claude AI实现对话式架构图生成,用户只需描述系统架构,AI即可输出深色主题、排版规范的HTML文件,支持一键导出PNG/PDF。该工具相比传统工具(如draw.io)优势明显:免手动拖拽,修改高效(通过聊天调整),单文件便携,且内置语义化配色方案。适用于快速生成技术方案、文档配图等
大模型开发已进入平民化时代:中国生成式AI用户达5.15亿,日均Token调用超140万亿,单次百万Token查询成本18个月暴跌280倍。零基础开发者仅需Python基础即可上手,无需深厚算法背景。本文提供清晰三步路线图:1)API快速调用,2)Prompt Engineering优化输出,3)LangChain构建RAG应用(附完整代码)。进阶阶段,LoRA微调仅需调整0.1%-1%参数即可定
DeepThink 是你的私有AI 操作系统 (AI Agent Platform),在安全隔离的沙箱环境中,自主执行代码、管理文件、完成超复杂长程任务。自托管的多用户本地 AI Agent Loop Engineering 系统 (支持桌面端+浏览器+移动端) —— 让 DeepThink 成为你的全能数字助手。
7月18日,在2026世界人工智能大会(WAIC 2026)上,平头哥开源自研AI软件栈T-Head SAIL(以下简称“SAIL”),这是其真武AI芯片的底层软件,可最大程度释放芯片的算力。据介绍,SAIL软件架构覆盖OS 层、SDK层与接口层的完整链路,不仅可以释放真武芯片算力,还可高效承接上层应用需求。目前,平头哥已推出真武系列AI芯片、倚天系列Arm服务器CPU、ICN Switch互联芯
总结Cursor+GitOps的核心价值鼓励读者尝试并反馈实践中的创新。
Kimi K3是由月之暗面(Moonshot AI)于2026年7月发布的开源大模型,参数规模达2.8万亿,支持100万token上下文窗口和原生视觉理解,是全球最大开源模型。其在多项基准测试中表现优异,尤其在编程(SWE Marathon、ArenaAI CodeArena)和智能体任务(BrowseComp、AutomationBench)中超越Claude Fable 5和GPT-5.6 S
右键长按降低屏幕亮度、短按减小音量。国产 RISC-V 架构主控芯片,32位 RISC-V 内核芯片,主频最高 240MHz,配备 606KB SRAM、300KB ROM,4MB Flash+16MB 运行内存,采用低功耗制程设计,设备长期离线待机功耗可控,完美适配嵌入式端侧 AI 语音交互场景。同时该芯片具备完善的外设拓展能力,内置 Wi-Fi 6、BLE5.2、星闪 NearLink 硬件基
GitHub热门项目排行榜出现大幅变动,昨日前十项目中7个跌出榜单,仅保留3个持续项目。新上榜项目以开发者工具和学习资源为主,显示出技术社区关注点从AI Agent向传统开发工具的回归。登顶项目"build-your-own-x"提供从零构建各类系统的教程索引,Star数单日增长146%。其他新进项目包括产品分析平台PostHog、AI知识纲要compendium、Copilot SDK等,反映开
摘要: 月之暗面开源2.8万亿参数大模型KimiK3,刷新全球开源模型规模纪录,获马斯克公开点赞。其核心突破包括: 技术架构:采用KDA混合注意力与超稀疏MoE设计,支持百万级上下文,计算效率提升2.5倍; 硬核能力: 登顶UCBerkeley编程榜,超越ClaudeFable5; 48小时零干预完成AI芯片全流程设计(Verilog→GDSII); 开发者实践:提供兼容OpenAI的Python
今日精选 21 条 IT 科技热点,覆盖 AI、开源、云原生、工程实践等领域。
帮我看看orders表有哪些字段和索引。“分析一下这条SQL为什么执行得这么慢。“如果增加联合索引,执行计划会发生什么变化?如今,在TRAE、Cursor等支持MCP协议的开发工具中,开发人员只需直接输入类似的问题,就可以调用KES完成数据库结构查询、SQL分析和索引优化等操作。近日,电科金仓在Gitee正式发布KES MCP Server。此次发布包含9个标准工具,覆盖数据库结构探索、SQL查询
OpenVLA 的核心主张是:用**充分的异构机器人操作数据**预训练一个 7B VLA,再用**参数高效微调**快速迁到新机器人/新任务,同时把训练与推理成本压到社区可承受范围。**OpenVLA** 的定位很明确:做一个**开源、7B 量级、可在消费级 GPU 上适配**的 VLA,把“通用机器人操作策略”从“听说过”推进到“能自己跑、能自己改”。- **动作表示**:离散 token vs
7月17日,2026世界人工智能大会 (WAIC) 主论坛正式揭晓了大会最高荣誉——卓越人工智能引领者奖(Super AI Leader,简称SAIL大奖),昇腾950超节点(Atlas 950 SuperPoD)凭借系统架构创新和突破,从众多海内外参评项目中脱颖而出,荣获SAIL大奖。
Open Interpreter 的 Rust 重写版本,基于 OpenAI Codex 代码库,专注于让低成本开源模型(Kimi K3、Qwen、DeepSeek)获得最佳 Agent 性能。内置多套 Harness、Computer Use 能力、ACP 协议支持,与 Codex SDK 兼容
月之暗面今天放出了 Kimi K3,这个模型有2.8万亿参数,是全球首个开源的3万亿级别模型。它在长程编程、知识工作和推理这些前沿场景里,整体实力接近最强的闭源模型 Claude Fable 5 和 GPT-5.6 Sol。但在 Frontend Code Arena 中,Kimi K3 以1679分超越 Claude Fable 5,位居第一。其他部分基准测评上,也超越了 Claude Fabl
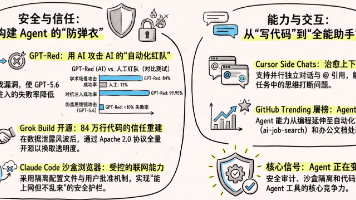
这周AI工具圈的主旋律是'Agent的安全与开放'——OpenAI用AI攻击AI训练出GPT-Red,让GPT-5.6对抗提示注入的成功率提升6倍;Anthropic给Claude Code桌面端装了沙盒浏览器,Agent终于能自己看文档了;SpaceXAI在数据泄露风波后把Grok Build 84万行Rust代码全部开源;Cursor 3.11推出Side Chats让你不用再打断主线对话;G
GOAI 世界人工智能开源大赛(以下简称“大赛”)由杭州市开源人工智能基金会主办,Agentic AI Foundation(AAIF)和LF AI & Data Foundation 作为全球开源合作伙伴参与支持,并由之江实验室、阿里云智能集团、蚂蚁科技集团股份有限公司、杭州智加未来科技有限公司、云深处科技股份有限公司、杭州群核信息技术有限公司等核心单位承办。此后,大赛将在北京、上海、深圳、杭州
昨天下午,我正在翻 Techmeme 上的 AI 新闻,一个标题让我停下了滚动的手——「Moonshot AI launches Kimi K3, ranks #1 on Code Arena, beating Claude Fable 5」。我的第一反应不是兴奋,是怀疑。月之暗面我知道。2025 年 Kimi K2 开源的时候我就关注过,是国内最早把万亿参数 MoE 模型开源出来的团队。后来 K
开源
——开源
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI Agent技术社区
AI Agent技术社区

 DAMO开发者矩阵
DAMO开发者矩阵


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区


 AtomGit AI 社区
AtomGit AI 社区


 AI编程社区
AI编程社区

 CANN开发者社区
CANN开发者社区





 智能体开发者社区
智能体开发者社区

 人工智能6S服务平台
人工智能6S服务平台








 开源鸿蒙跨平台开发者社区
开源鸿蒙跨平台开发者社区