登录社区云,与社区用户共同成长
邀请您加入社区
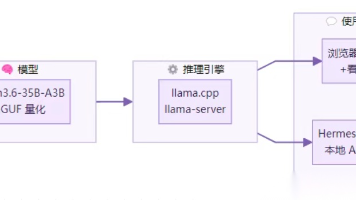
读完这篇,你能做到这三件事:**1️⃣ 用 6G 显存跑 35B 超大模型(MoE 架构的黑魔法)2️⃣ 把你的 Windows 电脑变成一台完全不花钱、不联网、无限 token 的本地 AI 服务器3️⃣ 接入 Hermes Agent,打造真正属于自己的 AI 助手——数据不出本机
MetaSAM3DBody的C++独立推理引擎实现单目摄像头实时3D人体动作捕捉,输出70关节BVH文件 【核心突破】 纯C++实现:基于ONNXRuntime+ggml,消除Python依赖,实现工业级部署 完整3D重建:单RGB输入即可生成含手指/面部细节的3D人体网格(62.9MPJPE精度) 动捕管线: 5ms级YOLO11m-pose检测 150ms级DINOv3-ViT特征编码 原生B
点击箭头处“蓝色字”,关注我们哦!!✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。👇 关注我领取海量matlab电子书和数学建模资料🍊个人信条:格物致知,完整Matlab代码获取及仿真咨询内容私信。
从d2l-zh到nanoGPT:两阶段吃透Transformer。先跟d2l-zh敲完注意力机制,再用nanoGPT跑通训练并生成莎士比亚风格文本。走完这步你能手写简化版GPT,理解token、embedding、attention的真正含义。
吊打谷歌 Gemma 4!Qwen3.6 免费 API 不限量,限时领取(附教程)
AI-Python机器学习与深度学习技术实战:CNN/Transformer/扩散模型、SHAP可解释及Hermes智能体自动化
大语言模型的多模态能力正从附加功能演进为系统级认知原语。其底层依赖Transformer架构实现跨模态对齐,而实际落地效果则由‘推理效率’与‘感知深度’两大维度共同决定。前者关注长上下文处理、token成本优化和部署确定性,适合B端高时效、低成本文本主导场景;后者强调视觉-语言联合预训练、坐标感知微调与异构硬件调度,支撑图文强耦合的复杂理解任务。当业务面临金融研报解析、工业质检或教育题图分析等真实
如果你想对当下 AI LLM(大语言模型) 的工作原理有所了解,揭开 ChatGPT、DeepSeek 背后的秘密,那一定要认识一下本文的主角 Transformer。当提起 Transformer 这个话题时,仿佛人人都可以讲些相关名词出来,什么自注意力机制啊、encoder、decoder什么的,但若深入追问细节,却很少有人能真正地说清楚。这篇论文首次提出的 Transformer 架构,已经
transformer
——transformer
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 龙虾开发者社区
龙虾开发者社区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区






 智能体开发者社区
智能体开发者社区
