登录社区云,与社区用户共同成长
邀请您加入社区
这事儿其实可以特别简单:一个 FastAPI 服务 + 一个本地 Ollama,就能跑通一个完整的 AI Agent 接口,还能自动给你生成漂亮的 Swagger 文档。对,你没看错,连 httpx 都得装,一会儿我们要用它去异步调 Ollama 的 API,这时候就别用 requests 同步请求了,一上量接口直接卡成 PPT。她先是卡在“怎么把每次的提问包装成 API”,然后又纠结“返回的结果
打开 ~/.claude/skills/,数一数里面有多少个文件。10 个?20 个?还是一堆叫不出名字的 my-prompt-v3-final?更难回答的问题是:你知道哪个 Skill 真的好用吗?大多数人的答案是:凭感觉。Skill 是什么如果你用过 Claude Code、Cursor 或 Windsurf,你一定接触过 Skill——一段 Markdown 文件,包含 YAML front
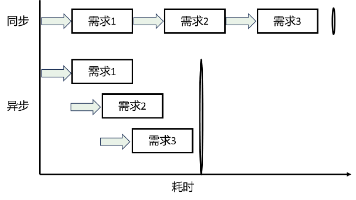
线程统一由系统调度。在python中受全局解释器锁(GIL锁)的限制,只适合用于I/O密集型阻塞场景(如:sleep休眠、网络请求、文件读写等),IO 阻塞时线程会释放 GIL,其他线程可抢占锁执行,实现并发提速。就初学者而言,尤其是初次接触fastAPI这一以异步为核心的框架的哥们儿来说,可能根本就搞不懂,进程、线程、协程的层级关系。它存在于单个线程内部,完全受代码控制,不由操作系统干涉,执行权
VibeCoding是一种基于AI辅助的新型编程范式,通过自然语言描述需求,借助工具(如Claude、GitHub Copilot)自动生成代码。其核心在于意图驱动、迭代验证和人机协作,开发者专注于架构设计与代码审查而非逐行编码。实践需配备AI编程助手、代码编辑器及版本控制工具,关键技巧包括编写结构化Prompt、提供充分上下文和小步迭代开发。典型应用场景包括原型开发和学习新技术,但需注意其局限性
2026年世界人工智能大会(WAIC)逛展攻略出炉,提供三大精选路线:快速打卡(H3机器人→H1大模型)、沉浸体验(西岸AI终端→H3机器人)、行业深度(H2算力→张江芯片→H4创投)。攻略涵盖世博4大展馆及西岸、张江展区核心内容,包括机器人、大模型、算力芯片等热点展区,并附完整展位图和交通信息。建议提前保存路线图,根据需求选择参观路径,避免因展区面积大、信息密集而错过重点。原攻略由脉脉社区创作者
对于已经在做这行的运营商,关键是把合规放在前面——证照齐全、商品来源正规、设备安全达标,这些是基础中的基础。对于想入行的新人,建议先做充分的市场调研,摸清楚本地的政策环境和竞争格局。设备安全、食品安全、支付安全等方面的标准越来越明确,虽然监管趋严,但也是行业走向规范化的信号。对于正规运营的从业者来说,规范化的环境其实是有利的。不同地区的监管力度不一致,有的地方要求多、流程长,有的地方相对宽松。物联
这套系统从零搭建,用到了当前社区最活跃的技术栈。RAG 思维:知识库 + 大模型的组合是当下最实用的 AI 工程路径全栈实践:从前端交互到后端 API 到 AI 模型调用,完整链路打通场景驱动:不是通用聊天,而是解决高校学生的真实痛点。
本文详细介绍如何利用 Python 生态中的 LangChain/LlamaIndex 框架,结合 FastAPI 构建后端服务,使用 Streamlit 开发前端界面,并集成本地部署的 Ollama 与 Qwen 大语言模型,打造一套完全离线、可运行于企业内网环境的 RAG(检索增强生成)知识问答系统。文章将从系统架构设计、环境搭建、核心代码实现、前后端集成、模型本地化部署到最终系统展示,提供完
电脑配件管理与装机报价工具 该工具是一个基于FastAPI的Web应用,提供全面的电脑配件管理和装机报价功能,支持PC端和移动端访问。 核心功能: 配件管理 - 支持13类配件(CPU/主板/显卡等)的增删改查,提供卡片和列表两种视图 电脑组装 - 按分类选择配件,自动计算装机费和总价 报价方案 - 生成可打印/导出的报价单,支持TXT/CSV格式 数据管理 - JSON导入导出、预设数据加载、一
本文介绍如何利用Vue3+FastAPI+大模型构建AIAgent系统,实现业务流程自动化。AIAgent与传统系统的区别在于能理解用户意图、拆解任务并自主执行操作。文章详细讲解了AIAgent的核心架构,包括大模型、控制器、工具调用和记忆模块,并给出了前端聊天界面和后端Agent控制的具体实现方案。特别强调了企业落地时需要注意的权限控制、数据安全和成本优化等问题。最后指出,未来程序员需要掌握业务
《企业级AI助手开发实践:Vue3+FastAPI+DeepSeek全栈解决方案》 本文详细介绍了从0到1构建企业级AI智能助手的完整技术方案。文章基于Vue3+FastAPI+DeepSeek技术栈,展示了包括前端交互、后端服务、大模型集成和数据存储的全流程实现。重点解析了企业AI应用的核心架构设计,区别于简单对话接口的关键技术(Prompt管理、RAG检索增强),并提供了SSE流式输出等优化方
发邮件至:qq202_ezczjjz6va@aka.yeah.net。备注:飞秒云额度申请 + 注册用户名,定时审核发放。公测名额有限,适合个人开发、日常调用,抓紧入驻。充值满10元,额外追加20刀永久额度。
搭建本站点初衷是降低大模型使用门槛,让所有人都能零成本用上优质AI接口。
在构建 AI 对话应用时,"如何让 AI 记住上下文"和"如何管理对话历史"是两个绕不开的核心问题。本文将带你从零实现一个具备短时记忆、流式输出、自动标题生成、支持历史对话查询的完整对话系统,技术栈基于 LangChain create_agent(Langgraph) + DeepSeek + FastAPI + SQLite。
面对企业积累的非结构化文档,人工阅读效率极低。利用大语言模型的长上下文窗口能力,可以实现批量化的摘要生成。但直接使用原始文本往往受限于 Token 数量,因此需要采用“分块 - 摘要 - 合并”的策略(Map-Reduce 模式)。首先,根据文档的自然段落或固定字符数将长文切分为多个 Chunk。对每个 Chunk 并行调用摘要接口,提取局部关键点。最后,将这些局部摘要再次输入模型,生成全局综述。
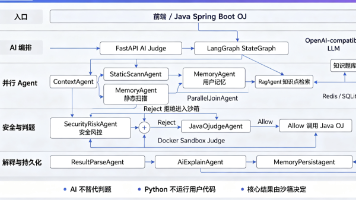
在传统在线编程评判系统(OJ)中引入AI增强功能的实现方案。该方案在保持原有Java OJ系统核心判题功能不变的前提下,通过Python FastAPI + LangGraph构建了一个AI辅助分析服务,为学生提供更友好的错误分析和学习建议。 文章首先指出传统OJ仅返回简单判题结果的局限性,强调AI增强层应专注于解释、风控和学习反馈,而非替代确定性判题。系统架构设计上,Java OJ负责代码执行和
本文记录了使用Python+FastAPI+MySQL构建后端API的学习过程。作者在杭州学习AI大模型一个月后,实现了商品管理系统后端开发。项目采用三层架构:model层使用pydantic定义数据模型,db层处理MySQL连接(端口3306,自动提交事务),app层实现路由和CORS配置。文章详细展示了商品分类模块的CRUD接口实现,包括添加、查询、删除和分页功能,并演示了FastAPI的自动
BaseAgent - 全栈 AI Agent 系统,FastAPI + Vue 前后端分离,支持大模型自定义、工具调用、向量知识库检索,Docker 一键部署。
t = sp.Symbol(‘t’, real=True)# 时间x = sp.Function(‘x’)(t)# 位移函数 x(t)m, k = sp.symbols(‘m k’, positive=True)# 质量和劲度系数omega = sp.sqrt(k/m)# 角频率。
编程思路决定工作量,好的编程思路能帮忙节省大量的时间,同时也会解决掉一些不需要出现和繁杂的小问题,在代码的检查和测试的时候也会减少一些不必要的麻烦问题。我的个人代码看似很多,很全。实际上要等运行的时候会发现一些问题,比如页面的设计很难看,这都算是小问题,还有些隐藏的问题可能是我还没有发现。总之加油吧,共进勉。
本文总结了Flask、Streamlit、FastAPI的使用详解<( ̄︶ ̄)↗[GO!]。
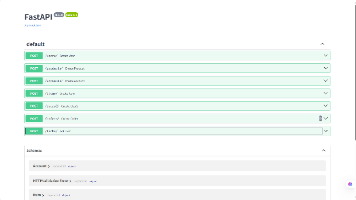
FastAPI提供多种数据验证方式确保API安全性和可靠性。通过Pydantic模型可对请求体进行类型检查和字段验证,支持默认值、必填项等设置。Query方式用于URL查询参数验证,支持长度、范围、别名等规则。Path方式验证路径参数,支持数值范围、正则表达式等条件。Field方式为模型字段添加更详细的验证规则和元数据,支持自定义验证器、枚举类型等。这些验证机制能自动生成文档并返回详细错误信息,结
该Python 3.11环境配置了一个基于FastAPI和LlamaIndex的AI应用开发环境,主要依赖包括:异步Web服务框架Uvicorn(0.35.0)、LlamaIndex核心库(0.12.49)及其OpenAI/GoogleGenAI扩展、Milvus向量存储支持;集成FastAPI-Pagination(0.13.3)实现分页,TaskIQ(0.11.18)处理异步任务;数据库支持包
【Python】Fastai安装指南
本文介绍了FastAPI中表单处理、异步编程和文件上传的实现方法。表单处理部分展示了三种方式:直接使用Form()声明字段、结合Pydantic模型和Annotated注解、以及在模型字段中直接使用Form()。异步编程部分对比了async/await和非异步函数的性能差异,演示了异步处理并发I/O操作的优势。文件上传部分涵盖了小文件和大文件的不同处理方式,包括内存存储、磁盘存储、多文件上传和文件
FastAPI是一个高性能异步Web框架,支持高并发处理。通过uvicorn服务器运行,开发者可以使用async/await语法实现异步通信。框架提供GET和POST请求处理:GET请求支持路径参数和查询参数两种方式;POST请求需安装python-multipart,通过Form接收表单数据。示例演示了基础路由配置、参数接收和异步响应返回,体现了FastAPI简洁高效的开发特点。
fastapi
——fastapi
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 智能体开发者社区
智能体开发者社区

 AI编程社区
AI编程社区

 openEuler 社区
openEuler 社区

 DAMO开发者矩阵
DAMO开发者矩阵


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区
 DeepSeek技术社区
DeepSeek技术社区


 AMD开发者中国社区
AMD开发者中国社区






 AI Agent技术社区
AI Agent技术社区