- @m0_59164520
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
机器人导航是指机器人能够在环境中自主移动和定位的能力。本文系统地回顾了基于大语言模型(LLMs)的机器人导航研究,将其分为感知、规划、控制、交互和协调等方面。具体来说,机器人导航通常被视为一个几何映射和规划问题,需要机器人对环境进行参数化处理。从早期的基于模型的方法到最近的深度学习和强化学习方法的进步,机器人导航技术取得了显著进展。例如,Leonard等人利用扩展卡尔曼滤波器在已知环境中进行移动机
但凡你自己动手搭建过编码智能体,大概率都会遇到这类问题:把大模型对接文件读写工具与终端命令工具,挂载到真实代码仓库后,往往执行十几轮工具调用就彻底崩盘。
过去一年,很多团队终于把 AI Agent 做出了“能跑起来”的样子:它能读上下文、拆任务、调用工具、跑测试、失败后重试,甚至可以在你睡觉时继续工作。
过去一年,很多团队终于把 AI Agent 做出了“能跑起来”的样子:它能读上下文、拆任务、调用工具、跑测试、失败后重试,甚至可以在你睡觉时继续工作。
2025 年初,我刚开始做 AI 设计Agent MewDesign 时,用的还是 Cursor。那时候,我和 AI 的工作量大概是五五开。它帮我补代码、改文件,我负责确认需求、检查结果、处理它做不好的部分,再亲自把测试、提交和发布接起来。AI 已经很好用,但研发流程仍然牢牢握在我手里。
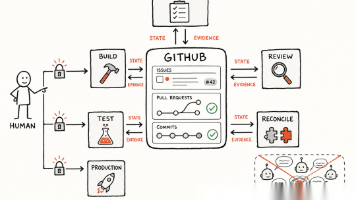
本文详细介绍了向量数据库Milvus的安装方式和Collection核心概念。通过三种部署方式满足不同场景需求,深入解析了Collection作为数据存储单元的逻辑隔离与资源管理机制,涵盖Schema定义、索引构建、实体操作等关键功能,并介绍了分区、分片等核心配置,为构建高效大模型应用提供基础支撑。
团队中有同事在做性能优化相关的工作,因为公司基础设施不足,同事在代码中写了大量的代码统计某个方法的耗时,大概的代码形式就是
是一直在研究和使用AI工具的小明。也一直在Github里面挖掘,看看有哪些好玩好用的开源项目~分享出来给大家!
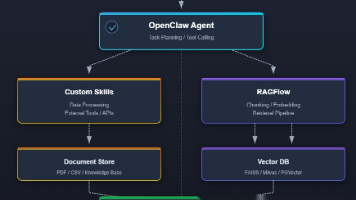
最近OpenClaw太火了,作为AIOps领域先行者,我也在探索OpenClaw如何用于AIOps领域。用OpenClaw越久,我就越觉得我们之前很难搞定的问题,在它这里都可以轻松搞定。
他们以为向量数据库就是"把向量存进去、搜出来",选哪个差别不大。但真的上了生产才发现:选错了,要么搜得太慢,要么存得太贵,要么你需要的功能它不支持。