登录社区云,与社区用户共同成长
邀请您加入社区
JDK 28 新增 jlink 证书裁剪插件,Quarkus 3.37.4 等多版本发布;Hibernate 7.4 逆向工程与 KotlinLLM 开源受关注,AI Agent 凭证代理与虚拟线程池化基准成热议。
1.matlab暂态稳定分析程序,三机九节点系统,发电机模型采用经典二阶模型,负荷用恒阻抗模型,用改进欧拉法和matlab自带求解器ode45进行时域分析,实现微分方程和代数方程交替求解。电力系统暂态稳定仿真程序123(设计源文件+万字报告+讲解)(支持资料、图片参考_相关定制)_文章底部可以扫码。2.模拟三相对称故障,进行暂态时域分析,分析暂态过程功角曲线。3.可以分析临界切除时间。
1.matlab暂态稳定分析程序,三机九节点系统,发电机模型采用经典二阶模型,负荷用恒阻抗模型,用改进欧拉法和matlab自带求解器ode45进行时域分析,实现微分方程和代数方程交替求解。电力系统暂态稳定仿真程序12(设计源文件+万字报告+讲解)(支持资料、图片参考_相关定制)_2.模拟三相对称故障,进行暂态时域分析,分析暂态过程功角曲线。3.可以分析临界切除时间。
Transformer,训练模型,优化,price代跑增加模块训练跑通,pyTOrch算法性能提升,算法优化,微创新,残差网络,预测模型,对比预测,模型修改,优化网络,cnn训练,融合创新,ai ,python,人工智能,数据处理,调参,优化,代码解读,代码分析。2.电力电子,开关电源,单相/三相PWM整流器,单向逆变器,变频器,曲线拟合,三相整流,单向整流,逆变,隔离变换器,反激电路仿真,正激,
摘要: 九州网络社群八周年线上发布会披露多项核心进展:1)运营数据突破,粉丝破千、内容销量超10万;2)日系青春文学三部曲定档,启用专属笔名;3)柴云智算升级3.1版本,新增版权预检与半自动控制系统;4)人事调整(副社长离职)及全平台账号视觉标准化;5)虚拟歌手声库全面规划,包括自研云瑶R2、外包星烁系列、日系新企划及私人实验项目;6)公布三大官方访问渠道(主官网、飞书备份、CSDN专栏)。发布会
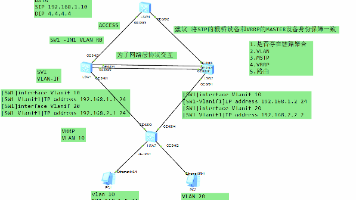
本次实验完成作业全部要求,使用MSTP实现二层链路冗余与负载分担,VRRP实现网关备份。1. 执行 display stp brief :实例1(VLAN10)根桥为SW1,实例2(VLAN20)根桥为SW2,冗余端口被阻塞,无二层环路。2. 执行 display vrrp brief :VRRP组1的Master为SW1,VRRP组2的Master为SW2,备份设备状态正常。3. 掌握VRRP虚
本文介绍了Java编程的基本框架代码和注意事项。主要内容包括: 提供了Java标准输入的基本代码模板,包含Scanner导入和主方法结构 注意事项: 逻辑运算符&&和||的使用区别 关键字的正确大小写(如System、String、Scanner等) 简化if条件赋值语句的写法 特别提醒了Main类名和main方法的大小写规范
AI工具调用安全实践摘要 当前AI工具调用(Tool Calling)面临严重安全风险,如沙箱逃逸、参数注入、反序列化漏洞等。核心问题在于错误地将模型视为可信主体,导致信任边界失效。本文提出三层防御方案: 协议校验:严格校验工具调用的名称、参数及权限,禁止模型控制安全字段,采用白名单机制和Pydantic强校验,避免反序列化漏洞。 执行沙箱:按工具隔离权限,默认拒绝所有操作,显式声明所需权限(如网
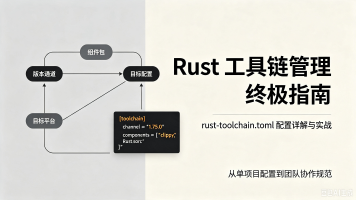
摘要:本文详细介绍了 Rust 项目中的 rust-toolchain.toml 配置文件,帮助开发者锁定工具链版本、管理组件和配置交叉编译。主要内容包括: 核心配置参数: channel:指定 Rust 版本(稳定版/测试版/每日构建版) components:安装额外工具(如 rustfmt/clippy) targets:配置交叉编译目标平台 profile:使用预定义组件集合 4个实战配置
摘要: Pytest 是 Python 流行的测试框架,以简洁语法(assert 断言)、丰富插件和强大夹具系统著称。安装后,通过命名规则(test_*.py)自动发现测试,支持异常捕获、参数化测试(@pytest.mark.parametrize)和资源管理(@pytest.fixture)。结合 Mermaid 流程图可直观理解其工作流程,适合单元测试、集成测试及持续集成。推荐遵循测试独立性原
7月22日起,安徽卫视每晚21:50在播一部特殊的剧。20集,每集10分钟,片头明确标注"AI制作"“AIGC导演”。这部剧叫《桃花潭记》,以安徽泾县宣纸古法造纸108道工序为叙事基底,讲明代万历年间御前侍卫与女匠人守护宣纸技艺的故事。更重要的是,它是,安徽卫视也因此成为国内首个播出AI剧集的上星卫视。AI短剧,正式从小屏走向大屏。
本篇是 Scratch 转 Python 系列第 17 天,我们把 Day 15-16 的 **AI Agent 角色体系** 真正跑起来——做一个 **命令行版多角色 AI 聊天机器人**。全篇串联五天的知识点:**Day 6 列表 + Day 9 字典 + Day 11 文件读写 + Day 13 异常处理 + Day 15-16 类与继承多态**,让你亲手看到"OOP 不是花架子,它就是现代
Loader统一标准化:多源数据统一转为Document,一套逻辑适配所有知识库语义分割是核心:用中文标点优先分割+重叠冗余,平衡长度与语义完整Cheerio简化爬虫:CSS选择器替代复杂正则,快速提取网页正文向量检索解决幻觉:只拿原文相关片段喂给LLM,杜绝凭空编造低成本落地:MemoryVectorStore无需部署向量数据库,本地快速验证RAG效果这套流程不仅能爬网页,替换对应Loader即
AgentScope Java 2.0 并非“万能框架”,它只专注一件事:让 Java 成为你构建可投产 AI Agent 的第一语言。如果你是 Java 技术栈团队,正在评估 Agent 框架,这个项目懂你的痛点——现有的微服务架构、Spring 生态、安全合规要求、运维可观测性需求。它能让你把精力花在 Agent 智能本身,而不是反复处理基础设施的“脏活”。代价呢?学习曲线确实存在。React
本文提出了一套完整的A/B测试方案,用于评估5家SERP API服务(serpbase、SerpApi、Serper.dev、DataForSEO、Bright Data)对AI Agent的辅助效果。方案包含:1)通过用户ID哈希实现20%均匀分流;2)设计三大类评估指标(业务质量/性能/成本);3)7天实测数据显示serpbase综合最优(1.4s延迟、0.2%错误率、91%准确率);4)采用
随着 DevOps 与 AI Agent 技术的深度融合,越来越多的团队开始尝试用智能体自动化运维流程。Python 生态中的 agentic-devops 包正是这一趋势下的产物,它把常见的 CI/CD、监控、日志分析、故障排查等运维任务封装为可编排的智能体工作流,帮助开发者用更少的代码完成更复杂的自动化。
文章摘要: 2026护网行动已从形式化攻防升级为实战化年度大考,聚焦APT攻击、AI安全与云原生安全三大新场景。护网包含红队(模拟黑客攻击)、蓝队(安全防御)和紫队(裁判统筹)三方角色,其中蓝队是新手最佳切入点,需掌握告警研判、应急处置等核心技能。备战分为战前漏洞清零、战时快速响应、战后深度复盘三阶段,重点防范AI钓鱼、云原生漏洞等新型攻击。文章还提供了新手学习路线,涵盖渗透测试、操作系统、网络基
📌 文章摘要 本文介绍了如何利用 QuantDash Python SDK 和 LangChain Agent 架构构建跨市场的金融 AI Agent,解决传统开发中多市场接口分散、数据格式不一致等问题。QuantDash 提供统一的代码规则(如 .SH, .US, .HK)和云端高并发数据服务,支持 A股、港股、美股的实时行情、盘口深度和分时 K 线数据获取。通过代码示例展示了如何集成 Qua
哈喽各位技术小伙伴们~👋 今天咱们来聊一个既熟悉又陌生的话题 ——开源(Open Source)!你可能会说:"害,开源不就是 GitHub 上那些免费代码吗?我天天用!🙅♂️ 如果你以为开源只是 “免费拿代码”,那可就 too young too simple 了~开源的世界远比你想象的精彩!从家酿啤酒配方🍺到基因组研究🧬,从蓝牙黑客硬件到支撑 30 亿设备的操作系统,开源的触手早已伸
📌 摘要 / 快速解答 (Direct Answer) 本文介绍如何利用 LangChain 结合高性能量化数据 SDK QuantDash,快速构建具备实时行情查询、复权 K 线分析和盘口数据检索能力的金融 Function Calling 智能体(Agent)。QuantDash 凭借原生支持 Pandas/Polars、标准化多市场代码后缀(如 .SH, .SZ, .US, .HK)以及服
Agentic RAG不是什么新概念炒作,而是RAG发展到一定阶段的必然演进方向。当基础检索能力做到极致后,再往上提升效果,就必须从架构层面升级,给大模型加上决策和行动的能力。对于企业来说,它的真正价值不是“更智能的聊天机器人”,而是真正能替代人工处理大量重复性的咨询、查询、整理类工作,把沉淀在文档和系统里的知识真正释放出来。落地的时候不用追求一步到位,从最痛的场景切入,先做好基础RAG的优化,再
文章摘要 jcode是一个用Rust开发的开源AI编程助手运行框架,专为多会话、多Agent协作设计。它通过Rust的高效性实现了显著性能提升:内存占用仅为Claude Code的1/20,启动速度快245倍。其核心创新包括:语义向量记忆系统实现被动联想式记忆、Swarm模式支持多Agent实时代码协作、Self-Dev模式允许Agent修改自身源代码。这些设计使其成为AI编程领域的新型"操作系统
afs2-model 是一个面向音频特征序列建模的 Python 工具包,专注于为音频信号处理、语音识别、音乐信息检索等场景提供高效、易用的序列建模能力。
实现一个具备完整播放控制功能的音乐播放器,支持播放列表管理、播放/暂停切换、上一首/下一首切歌、进度拖拽、音量调节、三种播放模式(顺序播放、随机播放、单曲循环)以及当前播放高亮显示。
摘要: AgentScope与LangGraph4j是Java生态中两大AI智能体开发框架,分别针对不同场景设计。LangGraph4j基于状态图模型,擅长复杂业务流程的精确编排(如审批流、多智能体协作),支持断点恢复;而AgentScope基于Actor模型,侧重企业级分布式部署与安全管控(如高并发客服、核心业务系统),支持自主决策与实时干预。选型时,结构化流程优先LangGraph4j,高安全
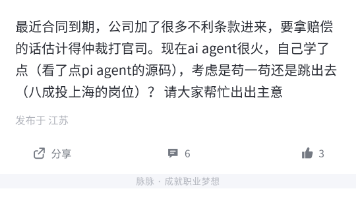
33岁+、苏州税前约30K、年终约2-4个月,合同到期却新增不利条款,这就是脉脉上一则用户讨论里的核心冲突。它只是个人样本,也有时效性:发帖者做Java服务端,考虑续签、争取赔偿,或把求职重心放到上海,同时也在学习AI Agent相关内容。
在人工智能领域,提升AI Agent(智能体)的任务执行能力是一项核心课题。当前一个主流技术路径是为其添加技能包(Skills),即一系列自然语言指令或代码片段,指导Agent如何更好地完成特定任务。
本文详细讲解了进程的三种基本状态及其转换关系:运行态(CPU正在执行)、就绪态(资源就绪只缺CPU)和阻塞态(等待I/O等事件)。通过QQ、浏览器等实例,说明了状态转换的四种情况,强调"就绪是等CPU,阻塞是等事件"的核心区别。文章用银行办理业务等生活类比帮助理解,并指出单核CPU同一时刻只能有一个运行态进程。最后通过浏览器访问网页的完整生命周期示例,展示了进程状态动态变化的过程,为后续学习进程控
如果任务只是一问一答,这样足够。但当任务开始包含工具调用、多步骤推理、多 Agent 分工、人工审批、会话记忆、流式输出、Trace 排障、MCP 工具生态或沙箱执行时,直接围绕 API 手写流程会很快变得复杂。如果全部自己手写,就会出现大量横切逻辑:工具 schema、工具结果回填、错误转换、循环控制、人工审批、上下文裁剪、trace 记录、流式事件合并、重试和取消。一次工作流会从 starti
这篇文章摘要: 《流式Markdown渲染:AI时代前端的核心技术挑战》 摘要: 随着AI应用的爆发式增长,流式Markdown渲染从边缘场景演变为核心基础问题。文章剖析了这一技术挑战的深层背景:从ChatGPT引领的流式交互革命,到用户体验标准的迭代升级。作者将系统性地讲解从P5到P7的完整认知路径,包括流式数据结构、浏览器渲染机制、Markdown语法特性等关键技术点。系列文章采用问题驱动模式
HarmonyOS 开发工具 DevEco Studio 的 SDK、模拟器镜像等组件动辄占用数十 GB 空间,通过 mklink 迁移到 D 盘是释放 C 盘空间的极佳手段。C 盘是 Windows 操作系统的核心所在,了解其文件夹结构是治理的第一步。微信、QQ、钉钉、企业微信的聊天记录和接收文件默认都存储在 C 盘的 AppData 或 Documents 下。其核心原理非常简单:C 盘只是操
函数的语法形式自定义函数和库函数是一样的ret_type fun_name(形式参数)ret_type 是函数返回类型fun_name 函数名字{}括起来的是函数体,函数体就是完成计算的过程ret_type使用来表示函数计算结果的类型,有时候返回类型可以是void表示什么都不返回函数的参数也可以是void表示函数没有参数,如果有参数要交代清楚参数的类型和名字还有参数的个数//函数的定义int ad
本篇是 Scratch 转 Python 系列第 16 天,聚焦 **面向对象三大特性中的「继承」与「多态」**。我们从 Scratch「精灵克隆 + 复用自定义积木」出发,讲透 Python 中 **父类 / 子类 / super() / 方法重写 / 多态调用** 的双向对照关系;并基于第 15 天的 `AIRole` 基类,继承出 **KefuAgent(客服)/ FanyiAgent(翻译
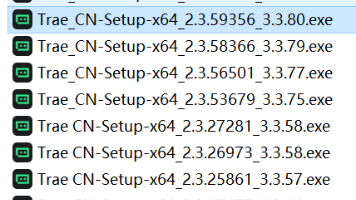
文章摘要:TraeCN IDE自7月更新3.3.81版本后改为积分制引发用户不满,推荐使用最后一个无限制的3.3.80版本(2.3.59356),并提供下载链接。同时分享Python爬虫代码,通过多线程扫描TraeCN历史版本下载地址(从2.3.62837到2.0.0),支持断点续传和结果保存。代码可自动检测有效版本并生成下载清单,包含进度显示、速度统计等功能,帮助用户获取旧版安装包。文末附有早期
Java 是由 Sun Microsystems 公司于 1995 年推出的一门面向对象程序设计语言。2010 年 Oracle 公司收购 Sun Microsystems,之后由 Oracle 公司负责 Java 的维护和版本升级。Java 也是一个平台,由 Java 虚拟机(JVM)和 Java 应用编程接口(API)构成,提供了独立于操作系统的标准接口,实现了"一次编写,到处运行"的跨平台特
此外,还能使用AI对话生成功能,输入“创建学生请假表单,包含请假类型、起止时间、事由、辅导员签字”,AI会自动生成表单框架,大幅节省配置时间。进入流程设计界面,使用可视化流程设计器,拖拽“发起、审批、抄送”等节点,搭建审批流程——比如“请假3天以内由辅导员审批,3天以上需学院领导审批”,支持串行、并行、条件分支等复杂逻辑。打开绘搭平台,点击“新建应用”,可选择“空白应用”自主搭建,也可从“高校专属
这七种节点,就像乐高的七种基础积木,通过不同的组合,就能拼出业务所需的各种“形状”。在这个大模型时代,我们经常需要编排复杂的 AI 调用链,比如:> 用户提问 -> 判断意图(AI) -> 如果涉及“天气”,调用天气 API(任务) -> 将结果用 AI 生成幽默回答(AI) -> 输出。#### 代码示例 2:一个简单的 AI 编排流程我们演示一个“智能客服”流程的简化版:先调用 AI 判断意图
所以,Java的跨平台是“智能”的,它在每个平台都能获得接近原生的性能。System.out.println("文件已写入,平台默认编码: " + System.getProperty(“file.encoding”));下次再写Hello World时,不妨想一想:你写的不是一行代码,而是一段可以驾驭任何操作系统的“咒语”。### 二、JVM:一次编写,到处运行的“翻译官”JVM(Java Vi
开发语言
——开发语言
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI Agent技术社区
AI Agent技术社区

 openEuler 社区
openEuler 社区
 2048 AI社区
2048 AI社区

 DAMO开发者矩阵
DAMO开发者矩阵






 智能体开发者社区
智能体开发者社区












 人工智能6S服务平台
人工智能6S服务平台






 AtomGit AI 社区
AtomGit AI 社区




 EazyDevelop社区
EazyDevelop社区



