- @m0_59164304
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
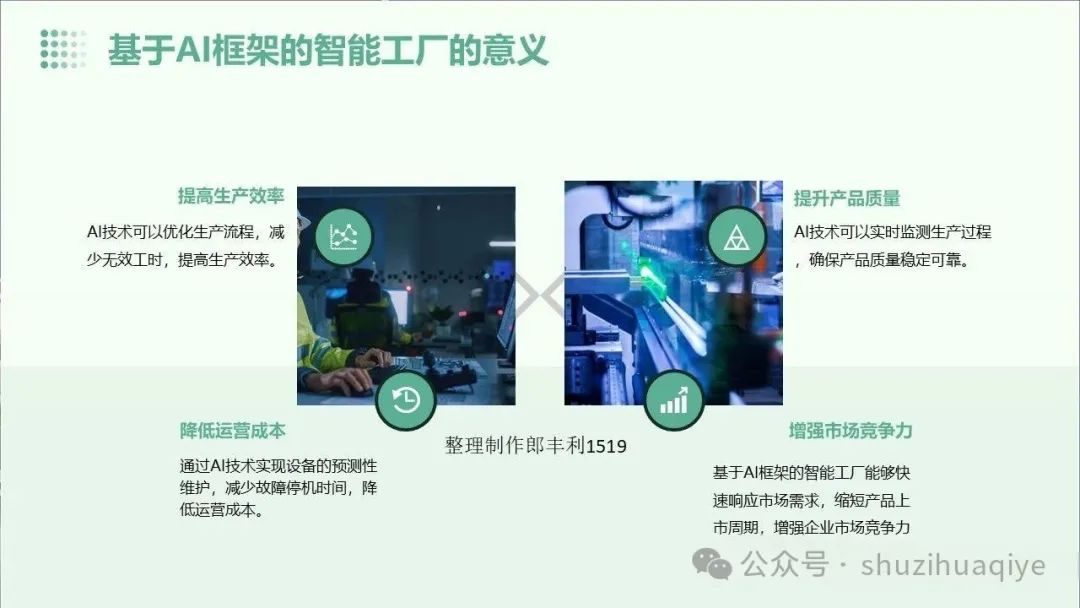
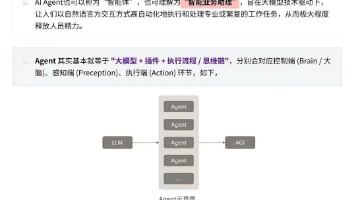
随着大语言模型(LLM)能力的不断跃升,AI 智能体正在从纯对话系统迈向更复杂的多轮推理、多工具协同与长期任务执行。

如上图所示,AI 智能体的核心在于其如何接收指令、执行任务并做出决策。以下是其关键组成部分:
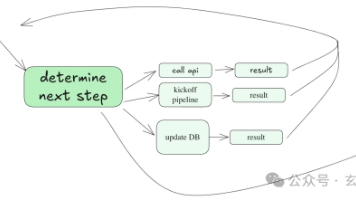
各种场合提到AI智能体(AI Agent),那么AI智能体究竟是什么呢?本文简单整理通俗的解读,给大家做参考。
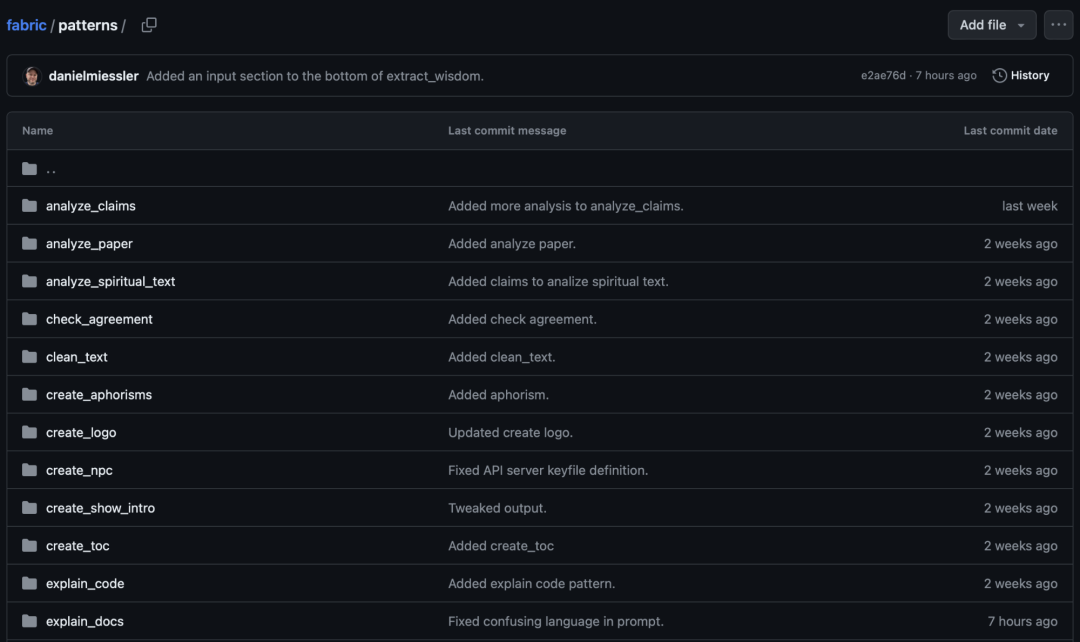
Fabric[1]是一个开源框架,目的是利用人工智能(AI)增强人类能力。它通过一系列众包的 AI 提示(Patterns),提供了一个模块化的解决方案框架,以解决特定问题,并且可以在任何地方使用。
1.bs4解析基础2.bs4案例3.xpath解析基础4.xpath解析案例-4k图片解析爬取5.xpath解析案例-58二手房6.xpath解析案例-爬取站长素材中免费简历模板7.xpath解析案例-全国城市名称爬取8.正则解析9.正则解析-分页爬取10.爬取图片1.bs4解析基础from bs4 import BeautifulSoupfp = open('第三章 数据分析/text.html
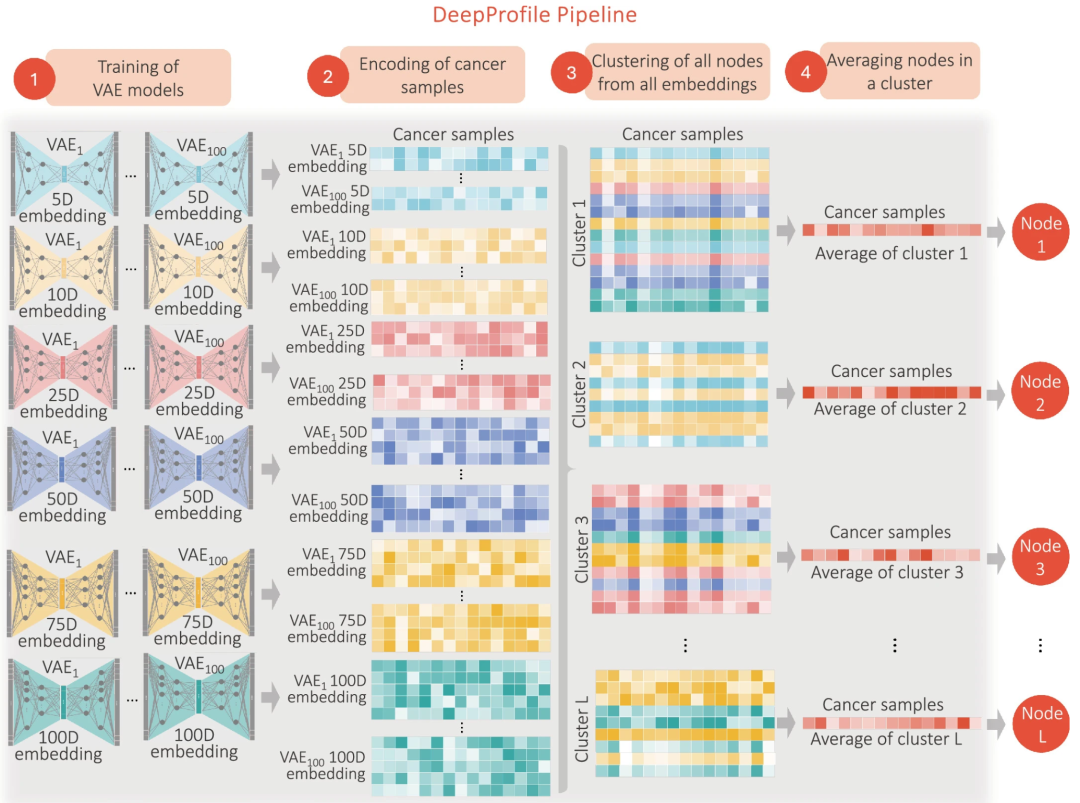
来自中国科学院的研究者开发了一个基于转换器的图形表示学习(TREE)框架,着力于癌症基因识别任务中的可解释性和可推广性。神经网络在解析复杂生物网络或者是多模态数据方面有非常大的优势。先前小编分享了一篇基于)的泛癌框架,纯数据库挖掘+简单架构(超低成本)登上了顶刊。▲:通过训练数百个VAE模型提取癌症样本的潜在变量。每个VAE模型具有不同的潜在维度大小,并进行100次随机权重初始化。使用这些模型对癌
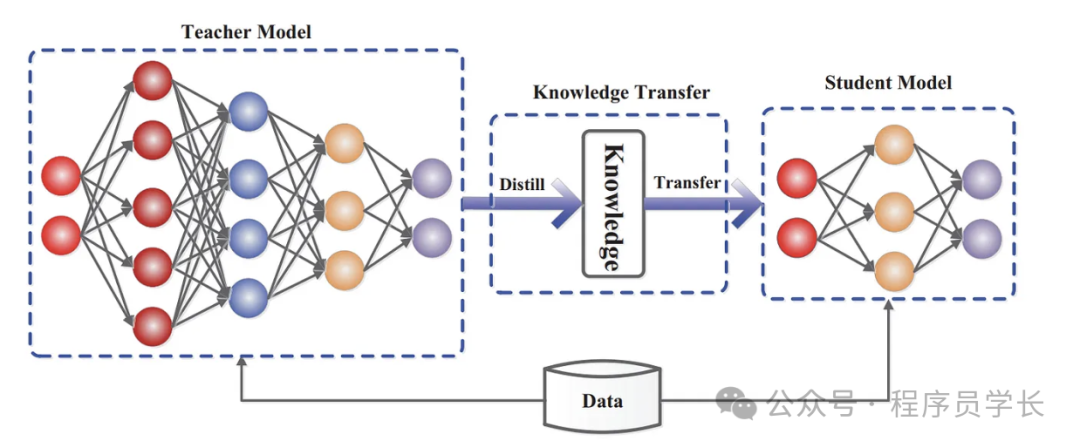
知识蒸馏是一种模型压缩技术,它通过将一个大型的、复杂的模型(称为“教师模型”)的知识传递给一个较小的模型(称为“学生模型”),从而使学生模型在保持较小规模和更快推理速度的同时,也具备接近甚至媲美教师模型的性能。在传统的神经网络训练中,我们使用的是原始的硬标签(hard labels)进行监督训练。而在知识蒸馏中,除了使用原始的硬标签(hard labels)外,还使用了来自教师模型的软标签(sof
在医学图像分割领域,结合不同成像模式如CT和PET扫描对于肿瘤分割至关重要。然而,由于PET扫描的有限可用性,训练和推理过程中同时使用CT和PET扫描面临挑战。本文提出了一种参数高效多模态适配(PEMMA)框架,用于将仅在CT扫描上训练的基于变换器的分割模型升级,以便在PET扫描可用时也能加以利用。该方法的优势在于:首先,利用变换器架构的固有模块化,通过低秩适配(LoRA)注意力权重实现参数高效的

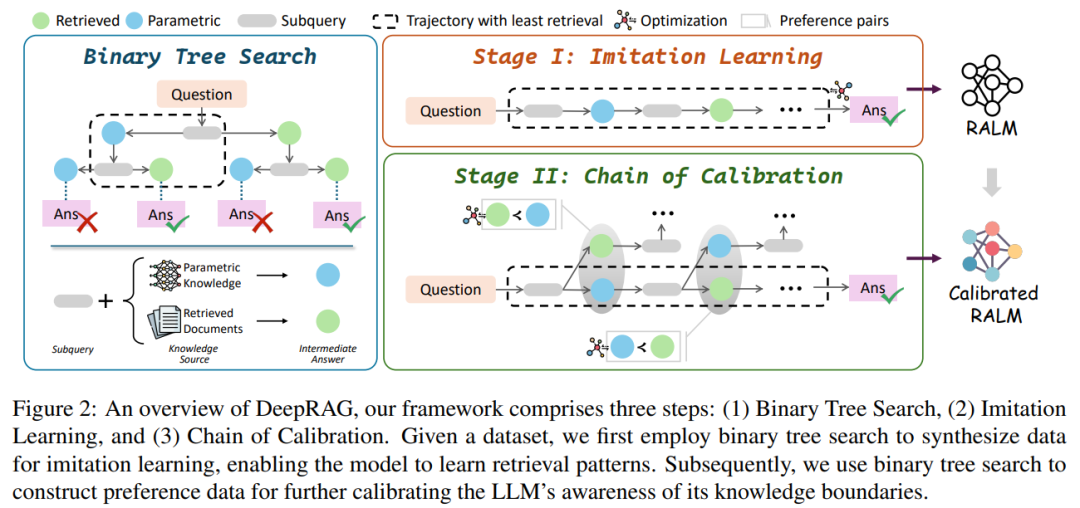
大语言模型生成的答案,看似自信满满却又存在漏洞百出的时候。虽然大模型推理能力不错,但事实性幻觉问题真的很严重。就好比问它一些需要最新知识或者精确信息的问题,它可能就会胡编乱造,根源就在于模型参数化知识的时效性、准确性和覆盖范围都有限。这时候,检索增强生成(RAG)技术进入了人们的视野,大家都期待它能借助外部知识库增强大模型的准确性,解决幻觉问题。可实际用起来,却出现了不少让人头疼的状况。
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。某液晶面板企业的分布式质检系统,实现每8秒完成55项光学参数检测。通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。对全球大模型从性能、吞吐量、成本等方面有一定的