




- @Androiddddd
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
计算机视觉(Computer Vision, CV)是指计算机利用摄像机、图像传感器等设备获取图像或视频,并通过复杂的算法对这些图像或视频进行处理和分析,以实现对图像或视频中的物体、场景以及其属性的理解和识别的技术领域。

在 x上看到有人分享一组图解 LLM 工作原理的帖子,内容通俗易懂,就搬运过来汉化一下,和大家一起学习!
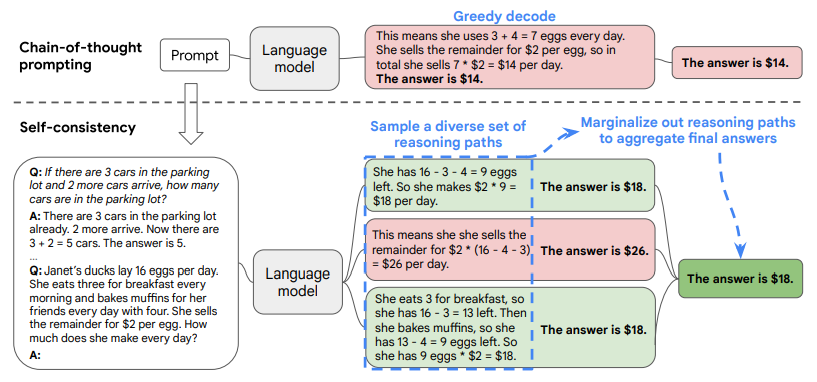
Chain-of-Thought(思维链,简称CoT)是一种改进的提示技术,旨在提升大型语言模型(LLMs)在复杂推理任务上的表现。Chain-of-Thought要求模型在输出最终答案之前,先展示一系列有逻辑关系的思考步骤或想法,这些步骤相互连接,形成了一个完整的思考过程。Chain-of-Thought可以通过两种主要方式实现:Zero-Shot CoT和Few-Shot CoT。
PyTorch是一个灵活、高效、易上手的深度学习框架,由Facebook开源,它广泛用于计算机视觉、自然语言处理等领域。PyTorch的基本功能涵盖了构建和训练神经网络的所有操作,如张量、自动微分(Autograd)、神经网络模块、数据集、优化器、GPU支持。除此之外,PyTorch还有丰富的库支持,比如Torchvision(用于图像处理)和Torchtext(用于文本处理),这些库可以帮助我们
上周我们对比了一下目前最流行的AI工具,不过三款工具都是国外的,对于国内用户来说,有些需要一些魔法才能访问,终究是有些不便。最近身边越来越多人问我:国产AI到底选哪个?文心一言、通义千问、Kimi、豆包……看着都差不多,但用起来又各有千秋。
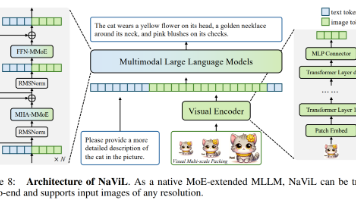
本文汇总了8篇最新多模态大模型(MLLMs)前沿研究,涵盖NaViL原生多模态模型、HoloV视觉令牌剪枝、Vision-Zero自改进框架、EPIC高效训练方法、HiDe高分辨率处理、PaDT统一视觉任务范式、Bridge视觉理解与生成模型以及TTRV测试时强化学习框架。这些研究在模型效率、性能提升、任务统一等方面取得突破,开源代码助力开发者实践应用,为AI编程开发提供新思路与技术方向。
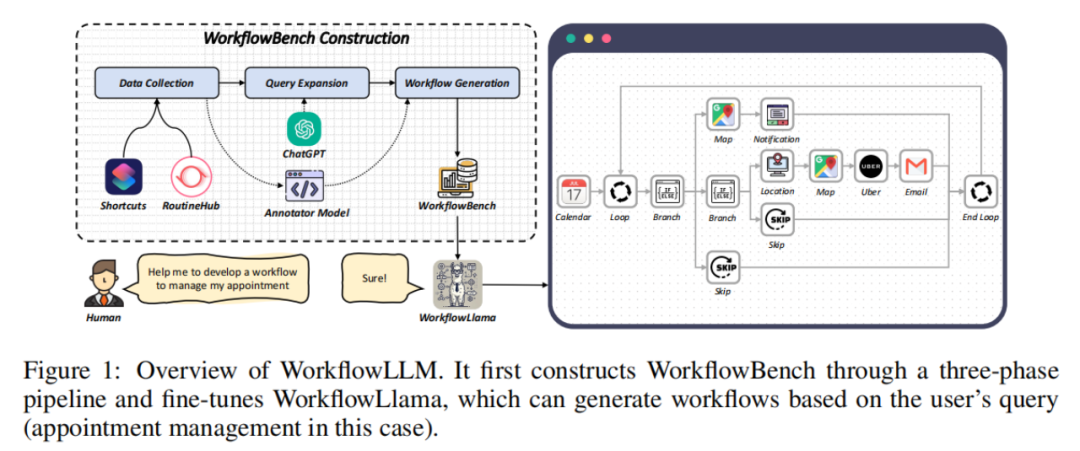
文章提出了WorkflowLLM框架,通过构建大规模数据集WorkflowBench并对智能体进行微调,显著提升了大语言模型在工作流编排中的能力。论文题目: WorkflowLLM: Enhancing Workflow Orchestration Capability of Large Language Models论文链接: https://arxiv.org/abs/2411.05451。
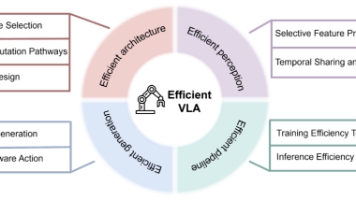
本文回顾了关于视觉-语言-动作(VLA)模型效率最优化的研究。从基础模型架构、感知表示到高层动作生成的演进过程,涵盖了训练与推理两个方面。在此基础上,重点阐述几项新兴研究方向:模型与数据的协同演化、时空感知以构建动态世界模型、用于智能动作生成的审慎推理、兼顾模仿与强化学习策略的学习范式,以及统一的评估框架以实现可复现的评价。
机器学习面对的训练数据,几乎没有只有单一属性的(也就是数据只包含一个数值或者一个字符串),而是每个数据都包含多种属性,比如气象数据(包含温度,湿度,风向等等),金融数据(开盘价,收盘价,交易量等等),销售数据(价格,库存量,卖出数量等等)。为了表示这个多属性的数据,或者称为多维度的数据,向量最为合适。向量就是有几个数字横向或者纵向排列而成,每个数字代表一个属性。向量类似编程语言中的一维数组,num

Mem0 和 Mem0-g 通过动态提取信息、智能更新和高效检索,为解决大语言模型(LLM)的长期记忆问题提供了一个强大且实用的解决方案。它们成功地在推理精度、响应速度和部署成本之间取得了理想的平衡。
