




- @m0_59235245
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
近年来,LLM在自然语言处理领域取得了显著进展,特别是在zero-shot learning方面,零样本关系抽取的目标是无需通过大量的标注数据,从文本中识别实体之间的关系。利用zero-shot能力有利于减少人工标注成本和提高模型的泛化能力,但是尽管LLM在零样本关系抽取任务中表现出色,但现有方法仍存在一些问题。首先,缺乏详细的上下文提示(prompts),导致模型无法充分理解句子和关系的复杂性。

但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型

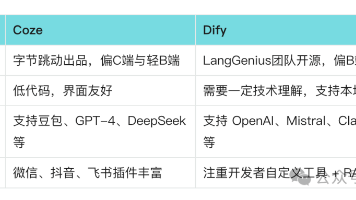
在当前大语言模型(LLM)快速发展的趋势下,如何将其能力工程化、模块化并高效地落地到具体行业场景中,是企业和开发者普遍面临的一大难题。为此一批专注于 LLM 应用开发的开源和商业平台相继涌现,其中,国外的 LangChain 和国内的 Dify 是代表性的技术驱动型平台,提供了面向开发者的链式调用框架与多模型接入能力。与此同时,字节跳动等大厂也在加速布局,依托自身模型底座推出了如 Coze 这样的

AI智能体开发的初学阶段,选择合适的平台至关重要。Coze和Dify是当前热门的两款平台,各自有独特的优势和适用场景。
无论你是初涉AI领域的新手,还是正在寻求更深层次知识的专业人士,这一部分提供了AI产品经理入门的基础知识。资料包括“AI产品经理入门手册”、“AI产品经理的7堂必修课”以及对AI产品经理角色和职责的详尽介绍。
我们经常聊如何做一款好的 AI 产品,却很少聊怎么成为一名好的 AI 产品经理。
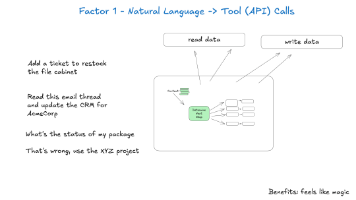
在构建智能体时最常见的模式之一是将自然语言转换为结构化工具调用。这是一种强大的模式,它允许你构建能够推理任务并执行它们的智能体。
近年来,GPT-4、Gemini等大型语言模型(LLMs)已成为许多AI驱动应用的核心。它们能回答问题、生成文本、提供建议,甚至辅助复杂的决策过程。但和任何先进工具一样,LLM需要精心管理才能确保输出可靠、安全且有用的结果。
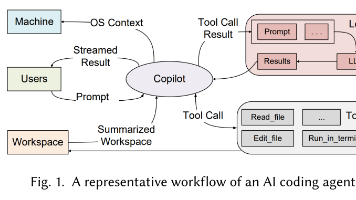
AI智能体式编程是一种新兴范式,其中大型语言模型(LLMs)能够自主规划、执行,并与编译器、调试器和版本控制系统等外部工具交互,以迭代完成复杂的软件开发任务。** 与传统的代码生成工具不同,智能体系统能够分解高层目标、协调多步流程,并基于中间反馈自适应地调整其行为。这些能力正在改变软件开发的实践。随着这一新兴领域的快速发展,有必要明确其研究范围,夯实其技术基础,并识别尚待解决的研究挑战。
我们今天谈的“AI Agent” 是可以自主感知、理解、计划并执行任务的智能体。但你可能不知道,**这个概念的雏形其实很早就出现了**,并且一开始就带有一种“类人”特质。
