登录社区云,与社区用户共同成长
邀请您加入社区
AI训练师职业发展呈现动态升级趋势,核心观点包括:1)职业不会被AI替代但会持续进化,工作内容从基础数据标注扩展到模型安全评估等更高阶任务;2)职业发展分为执行者(0-2年)、专家(2-5年)、架构者(5年以上)三阶段,关键跃迁是从执行到设计再到策略;3)存在技术深度线、管理领导线、创业创新线三条发展路径,需根据个人特质选择;4)建议采用T型人才培养模式,在保持技术深度的同时拓宽机器学习、产品思维
摘要 AI训练师在团队中扮演"翻译官"和"润滑剂"的关键角色,负责解决算法、产品和业务方之间的沟通鸿沟。他们能听懂技术语言、理解业务需求并指导标注工作,是唯一横跨三界的枢纽角色。跨职能沟通主要发生在需求、开发、测试和上线四个阶段,AI训练师需针对不同场景采用特定话术进行有效沟通。在敏捷开发中,AI训练师负责任务流转、质量监控和各方协调,其介入节点贯穿整个项目周期。通过标准化话术模板和可视化看板管理
AI时代的技术文档管理:核心要点与规范 摘要:AI项目文档需满足可解释性、合规性和可复现性要求,分为外部(模型卡片、合规报告)和内部文档(API文档、实验记录)。六类核心文档包括API接口文档、模型卡片、SOP标准文档等,各有明确要素和更新频率。模型卡片需包含基本信息、预期用途、训练数据等6大模块,遵循Google标准模板。建议采用Markdown编写,确保文档可被新工程师快速理解并复现实验结果,
Pixel2Geo™ 为镜像视界浙江科技有限公司独家自研像素-地理空间映射核心演算引擎,隶属SpaceOS™全域时空操作系统十大自研演算引擎核心组件,依托单目多视光束平差几何解算实现任意视频画面二维像素(u,v)向实景统一大地三维坐标(X,Y,Z)可逆映射,是视频孪生、无感无源定位、设备空间锚定、井下/港口/电力全域透明化的底层数学根基,整套算法无开源算子、无第三方视觉库授权,为国家十四五重点课题
开发者Om Patel给Fable 5出了一道竞赛编程难题,一道要求处理图连通性和区间覆盖的硬核算法题。结果,界面意外泄露了一段模型没打磨过的思考过程,他把这段过程截图发了出来。Claude Fable 5才刚刚回归,就差点被网友的口水淹死。A社官方账号发推庆祝回归,开发者Thariq也跟着喊「excited for guys to get access back」。结果香槟刚打开,风向就全变了。
本方案为全栈国产化纯视觉一体化成套系统,基于自研SpaceOS™全域时空操作系统底座,整合十大自研演算引擎,打通全域步态特征比对、重点人员全域轨迹闭环管控、非接触式肢体心理量化筛查三大核心业务,一套平台同步承载身份核验、动态布控、心理风险预警全流程业务。重点人员全域轨迹闭环管控;从零完成解码、人形分割、三维骨骼提取、步态特征编码、心理时序推理全算子开发,彻底剔除OpenCV、FFmpeg等海外开源
以上算法与数据结构是计算机科学的“普通话”,是阅读更复杂代码、学习高级课程(如操作系统、数据库、编译原理)和通过技术面试的必备前提。掌握它们的关键在于。
本文基于助睿Uniplore零代码平台,完整实现了浏览器用户行为数据分析全流程实验。实验依托1000名用户、800万+条行为记录的825MB原始数据,通过ETL加工处理生成8张聚合统计表,涵盖市场格局、周活跃趋势、使用频率等核心维度。使用助睿Max数据大屏工具搭建可视化界面,并通过蓝图编辑器实现动态数据接入,最终完成可在线预览的专业化数据大屏。实验成果包括:1)掌握零代码ETL数据处理全流程;2)
正在变成一种新的工程资产。它看起来只是一个带有触发描述的 Markdown 文件,实际承担的是把领域经验、操作流程、工具约束和团队偏好注入 Agent 执行链路的职责。真正的问题不在于“能不能写出一个 Skill”,而在于:这个 Skill 是否稳定改善了 Agent 的输出?它改善了什么,代价是什么,改善是否可复现?如果只能靠体感判断,一个 Skill 很容易停留在手工作坊阶段;如果能被测试、对
数据分析是大数据专业的核心技能之一,在志愿填报时选择学习数据分析具有明确的职业优势和技术价值。大数据专业通常涵盖数据采集、存储、处理、分析和可视化等内容,数据分析作为其核心方向之一,在志愿填报时选择学习数据分析具有显著的实用价值。通过 CDA 认证的学习和考试,可以系统地掌握数据分析的知识和技能,提升自己在数据分析方面的能力。在就业市场上,拥有 CDA 认证的候选人往往更受青睐。CDA 认证可以证
2026年,AI与自动化工具的普及将进一步提升数据在营销中的权重。当前,超过60%的企业已采用数据工具优化营销策略。CDA 认证是数据分析师职业发展的重要里程碑,通过 CDA 认证可以为职业发展打开更多的可能性。例如,可以在数据分析、数据科学等领域担任更高级别的职位,拓展自己的职业发展空间。通过 CDA 认证的学习和考试,可以系统地掌握数据分析的知识和技能,提升自己在数据分析方面的能力。CDA 认
例如,可以在数据分析、数据科学等领域担任更高级别的职位,拓展自己的职业发展空间。通过 CDA 认证的学习和考试,可以系统地掌握数据分析的知识和技能,提升自己在数据分析方面的能力。CDA 认证可以证明他们具备扎实的数据分析能力和专业素养,增强他们在人工智能、大数据分析、金融等领域的就业竞争力。数据分析能优化运营策略、提高用户留存率、精准投放资源,是运营岗位的核心技能之一。自动化与AI的普及:数据分析
传统软件测试的确定性假设在 AI Agent 面前彻底失效——同一个输入可能产生不同输出,环境状态随时变化,工具调用可能失败也可能成功。Agent 测试不是验证"给定输入是否产生预期输出",而是验证"Agent 的行为是否在可接受的边界内"。本文系统梳理 Agent 测试工程的方法论与实践。
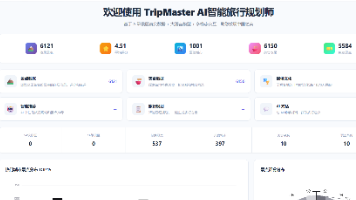
TripMasterPro基于Flask+Vue.js 3,整合全国6121条景点、6150条美食及1364条住宿数据,提供个性化行程规划。采用模拟退火与遗传算法动态优化,结合用户疲劳度(三档)及实时拥堵数据,确保行程舒适合理。集成DeepSeek大模型实现AI推荐与自然语言交互,支持多模态输入及协作编辑。后端SQLite连接池+WAL模式提升并发,前端ECharts可视化。测试表明,系统有效解决
例如,可以在数据分析、数据科学等领域担任更高级别的职位,拓展自己的职业发展空间。通过 CDA 认证的学习和考试,可以系统地掌握数据分析的知识和技能,提升自己在数据分析方面的能力。CDA 认证可以证明他们具备扎实的数据分析能力和专业素养,增强他们在人工智能、大数据分析、金融等领域的就业竞争力。平衡会计专业知识与数据分析技能的学习难度较大,可以优先掌握与财务直接相关的分析工具(如Excel和Power
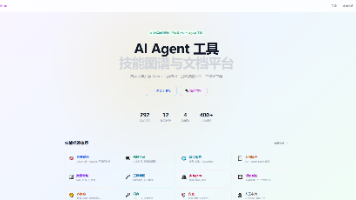
摘要: Agent Skills Hub 是一个开源平台,自动采集 GitHub 和 Awesome-List 上的 AI Agent 工具信息,通过规则引擎和 LLM 提取 12 类技能标签(如推理规划、代码生成等),提供结构化存储与文档生成功能。平台收录 292+ 工具和 400+ 插件,支持按标签筛选、一键导出 Markdown 文档,并集成管理后台进行数据审核。技术栈采用 Next.js
本文设计的分布式定时淘宝商品详情采集架构,通过分层解耦、集群部署、容错重试、代理隔离、全链路监控的核心设计,彻底解决了传统单机爬虫的单点故障、性能不足、风控拦截、数据不稳等核心问题。架构具备高可用、高并发、可扩展、易运维的特性,能够稳定支撑企业级规模化电商商品定时采集业务,同时兼顾了性能与合规性,是一套可直接落地、可长期迭代的电商数据采集工程化方案。
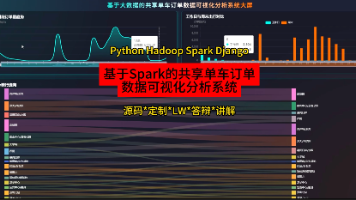
本设计实现了一个基于Spark的共享单车订单数据可视化分析系统。系统采用Hadoop存储数据,利用Spark进行高效计算,后端使用Django框架提供数据接口,前端通过Vue和Echarts进行动态图表展示。系统从时间、空间、用户行为和业务价值四个维度,对共享单车订单数据进行深入分析,实现了时段订单量、热门区域、用户分群及营收贡献等功能,最终形成一套完整的可视化分析平台,为共享单车运营管理提供数据
本文总结了网易Java后端面试的高频考点,涵盖JVM、并发、Spring、Redis、MySQL等核心技术。文章通过10个典型问题,如ConcurrentHashMap优化、JVM调优、Redis排行榜实现、分布式锁方案等,结合网易云音乐、网易严选等业务场景,详细解析技术原理和实战应用。特别强调面试不仅要掌握基础,还需理解技术在实际业务中的运用,如Feed流系统设计、订单超时处理等场景化解决方案。
从定义中我们可以看到,Vector与String相似,也是一个模板,毕竟是为了支持多种数据的插入。
本系统基于Hadoop与Spark大数据技术栈,构建了一个针对卵巢癌风险数据的多维可视化分析平台。后端采用Python和Django框架,通过Spark SQL对包含人口统计、临床、遗传及影像学特征的数据集进行聚合与关联分析。前端利用Vue和Echarts,将分析结果以交互式图表形式呈现,实现了对不同风险等级人群画像、临床特征与癌症进展等关键维度的深度洞察。
下面拆开来看每一个层级的具体内容。
本文介绍了一个基于Python的中药材数据分析系统,采用Django框架和MySQL数据库构建。系统通过requests爬虫从中药材天地网采集数据,提供产地占比饼图、词云图、价格柱状图、成分极坐标图、历史价格折线图等可视化分析功能。后台支持药方数据管理,包含搜索、新增、删除和导出操作,并设有注册登录模块保障系统安全。核心代码展示了数据采集过程,包括产品ID获取和药方信息提取。该系统解决了中药材数据
本文介绍了一个基于Python Flask框架的医疗数据可视化系统。系统采用Echarts实现数据可视化,包含六大功能模块:首页数据概览、患者信息管理、医疗数据可视化、患者信息添加、医疗工作安排和疾病关联分析。核心功能包括通过图表展示患者数据趋势、表格管理患者信息、日历管理医疗事务以及关系网络分析疾病关联。系统后端使用Flask处理请求,前端结合HTML和Echarts实现交互式可视化,旨在帮助医
Python是一门强大且应用广泛的高级编程语言,其学习路径可以从基础语法一直延伸到数据科学、人工智能、Web开发等多个专业领域。一个系统、严谨且富有挑战性的学习路径(区别于简单入门教程)应遵循从基础到核心,再到专业应用与深度优化的逻辑。下面是一个模拟大学高阶课程结构的Python学习指南,它强调理论深度、工程实践和系统性。
变量是贴纸,不是盒子:赋值是贴标签,改一个贴纸不影响另一个(对不可变对象)。传参传地址,可变要小心:给函数传列表/字典,相当于给了它你家地址,它可能真会动你东西。列表能改,元组不能:沙发随便整,古董椅子只能看。字典钥匙不能变:标签不能用冰棍做(可变对象)。range 从 0 起,到 n 前停:数数总是0,1,2...,没有n。break 全结束,continue 跳本轮:下班 vs 跳任务。函数内
数据挖掘
——数据挖掘
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区




 openEuler 社区
openEuler 社区


 AI编程社区
AI编程社区



 EazyDevelop社区
EazyDevelop社区

 DeepSeek技术社区
DeepSeek技术社区

 CSDN-OPC开发者社区
CSDN-OPC开发者社区
 智能体开发者社区
智能体开发者社区
 龙虾开发者社区
龙虾开发者社区
 深开鸿 技术专区
深开鸿 技术专区