登录社区云,与社区用户共同成长
邀请您加入社区
同时具备自研抗辐照主控(X系列)和SATA/PCIe双协议工业主控(G系列)的研发能力,使天硕能够在一个统一的技术团队框架内,为不同行业客户的固件服务需求提供有实质深度的响应,而无需在航天和工业两个方向之间切换外部供应商。对于有国产CPU适配需求的项目,天硕SSD已完成与统信UOS、麒麟OS、欧拉OS等主流国产OS在多款国产CPU平台上的组合验证,具备提供目标平台实测性能参考数据的能力,使选型团队
我们一听到 **RAG(检索增强生成)**,脑海里立刻浮现出的是:AI、ChromaDB、Milvus、向量数据库、复杂的 Python 依赖…… 还没开始写代码,就已经被繁琐的部署环境劝退了。
AI Agent操作数据库的安全问题已经从”要不要防范”的前瞻性讨论,转变为”如何有效防范”的紧迫性课题。从应用层权限管控到数据库级数据沙箱,四类安全护栏方案在防护层级、防护时机和恢复能力上各有侧重。企业在选型时应根据自身Agent使用密度、业务系统关键程度和风险承受能力进行综合评估,构建多层联动的纵深防护体系,在释放AI Agent效率红利的同时,牢牢守住数据安全的底线。
注册成为开发者,需要实名认证控制台-->应用管理-->我的应用(1)点击创建新应用,弹出新建应用弹窗应用名称:map_mcp应用类型:出行(2)点击已创建应用操作项中的设置,弹出设置Key弹窗Key名称:test服务平台:web服务(3)提交,我的应用列表中存在新生成的Key。
Python Slack SDK是Slack官方维护的Python开发工具包,用于对接Slack平台的各类API。该SDK包含多个功能模块,如Web API、Webhooks、Socket Mode长连接等,支持同步和异步调用方式。通过WebClient可以方便地发送消息、上传文件等操作,AsyncWebClient则为异步场景提供支持。安装简单,仅需Python 3.7+和pip命令。该工具包适
Codex 接入 GPT API 中转站时,最容易出错的地方通常不是模型能力,而是配置文件。尤其是 `config.toml` 和 `auth.json`,一个负责模型供应商配置,一个负责密钥或认证信息。如果字段写错,Codex 就可能无法正常调用模型。
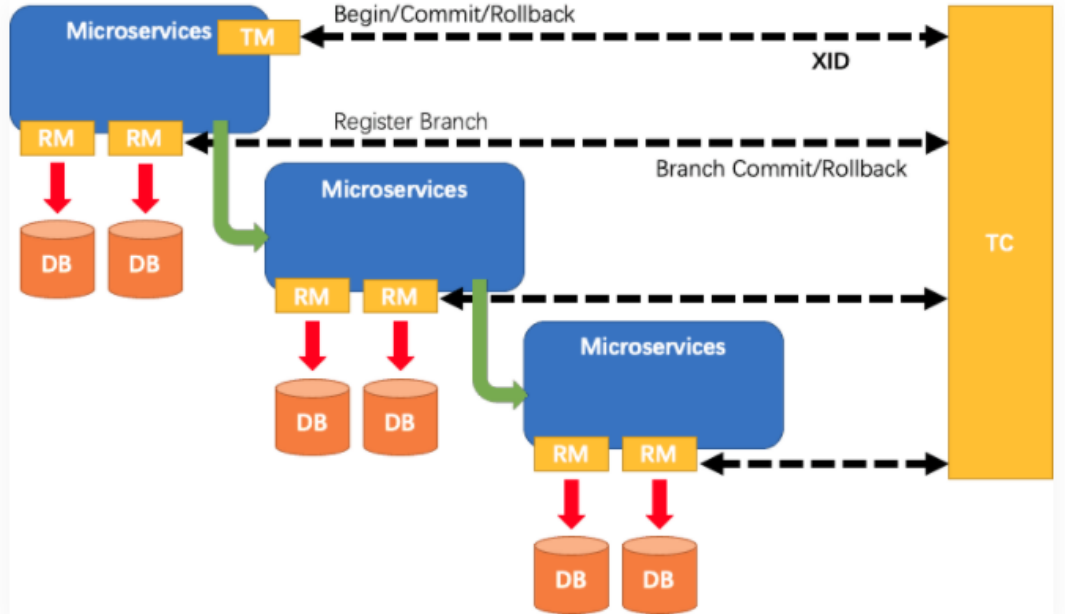
分布式事务Seata使用及其原理剖析Seata的三大角色Seata架构存在的问题SeataServer与Seata Client搭建
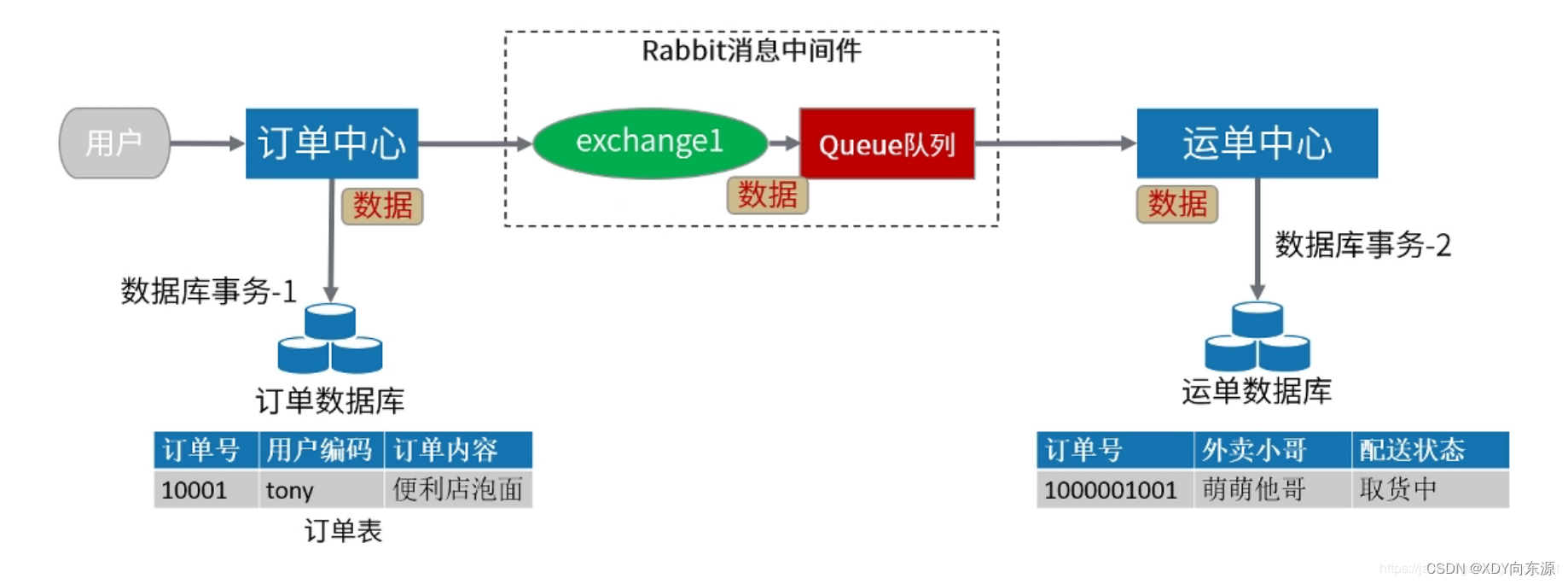
通用性强拓展性强方案成熟基于消息中间件,只适合异步场景消息处理会有延迟,需要业务上能够容忍尽量避免分布式事务;尽量将非核心事务做成异步;保证事务的ACID四大原则;实现分布式事务有很多种方式,看大家习惯用哪一种,使用消息中间件是一种很基本也很可靠的方式。
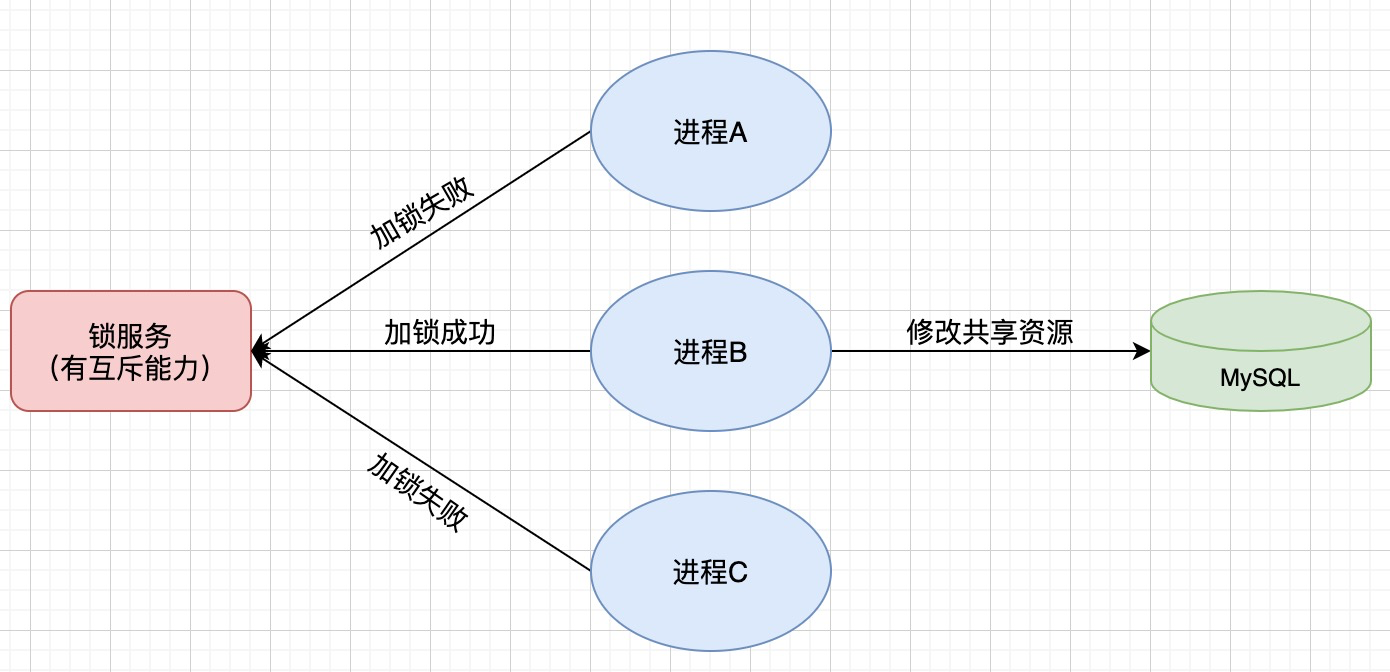
需要注意的是,分布式锁的实现需要考虑到并发性、可靠性和性能等方面的问题,选择合适的实现方式需要根据具体的需求和场景进行评估。的操作,并且这种操作是原子操作。设置失效时长,不能保证。
本文是Redis面试高频考点精华笔记,聚焦面试常问的主从复制、哨兵机制、集群分片、缓存三大问题(穿透/雪崩/击穿)、分布式锁五大核心模块,摒弃冗余内容,只保留面试必背的原理、流程、优缺点及解决方案,适配校招/社招Redis面试备考。
分布式锁是一种在分布式系统中协调多个节点访问共享资源的机制,意思就是说不管这些节点是部署的相同服务还是不同服务只要共用了某个数据就需要使用锁防止数据被多节点同时修改,那么防止共享数据被修改就必须用分布式锁吗?代码里用线程模仿进程来测试redis实现分布式锁。其中通过setIfAbsent方法来进行加锁设置,通过setIfPresent方法来给锁续期防止任务未执行完锁就失效了。这里需要注意的是:01
转载原文http://www.zte.com.cn/cndata/magazine/zte_technologies/2016/2016_6/magazine/201606/t20160620_458638.html 近年来,“去IOE”成为一个热门话题。这一方面是技术考量,IOE代表这...
设计和使用对象池容易出错,设计上需要注意状态同步,这是个难点,使用上可能存在忘记归还(就像 C 语言编程忘记 free 一样),重复归还(可能需要做个循环判断一下是否池中存在此对象,这也是个开销),归还后仍旧使用对象(可能造成多个线程并发使用一个对象的情况)等问题。这样,对象就可以再次被借出使用。在一些特定场景下,如受限的、不需要可伸缩性的环境(比如移动设备),CPU 性能不够强劲,内存比较紧张,
ShardingSphere是一套开源的分布式数据库中间件,旨在为分布式数据库架构提供一系列服务。作为一套完整的解决方案,ShardingSphere包含JDBC和Proxy两大核心组件,它们均提供标准化的数据分片、分布式事务处理以及数据库治理功能。无论是在Java同构环境中还是在多语言、云原生等异构环境中,ShardingSphere都能够有效地工作。
clickhouse本地表与分布式表的数据写入
分布式事务
1 HBase 浅析1.1 HBase 是啥HBase是一款面向列存储,用于存储处理海量数据的NoSQL数据库。它的理论原型是Google的BigTable论文。你可以认为HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统。HBase的存储是基于HDFS的,HDFS有着高容错性的特点,被设计用来部署在低廉的硬件上,基于Hadoop意味着HBase与生俱来的超强的扩展性和吞吐量。HBa
定义:基于 Hadoop 的分布式、面向列的开源数据库,支持大数据随机定位和实时读写。原型:源自 Google Bigtable,对应关系:HDFS→GFS、MapReduce→MapReduce、Zookeeper→Chubby。特点:实时性强、存储空间大、可伸缩、高可靠、面向列、数据类型单一(字符串)。
本人大三下学期,学校开设了这门大数据分布式存储选修课,主要学习了HBase,hadoop等分布式存储技术。。。。1.2HBase的安装和配置本节将讲述如何安装、部署、启动和停止HBase集群,以及如何通过命令行的方式对HBase进行基本操作,例如:插入、查询、删除数据。在安装HBase之前强烈建议各位读者仔细阅读1.2.1节,确定这些基本需求都已经满足,否则可能遇到各种棘手的问题,比如查询不到数据
通过这样的架构设计,企业能够灵活应对市场变化,快速迭代产品与服务,不断提升用户体验,加速业务增长,从而在激烈的竞争中保持领先地位,推动数字化转型迈向新的高度。这一架构规划旨在将企业的战略愿景转化为具体的数字化实施方案,确保数字化转型与企业发展目标紧密契合,通过持续优化和升级,不断提升企业的竞争力和市场响应速度。这一架构的核心在于深入理解并持续优化业务运营,确保企业策略的有效执行,同时作为数字化转型
版本说明:seata-server:1.1.0SpringCloud:Greenwich.SR5spring-cloud-starter-alibaba-seata:2.2.0.RELEASEseata-spring-boot-starter:1.2.0理论知识:何为2PC:flink专栏有篇文章介绍过,因为flink端到端的Exactly Once就是依赖2PC实现的seata的设计思想Seat
Oracle数据库的性能优化是一个复杂且多维度的过程,涉及SQL语句优化、索引策略、数据库设计、内存管理、配置调整等多个方面。以下将详细阐述这些优化方法,并给出具体示例。
Linux性能优化-磁盘I/O优化
在分布式系统设计中,全局唯一ID是一个基础而关键的组件。随着业务规模扩大和系统架构向微服务演进,传统的单机自增ID已无法满足需求。高并发、高可用的分布式ID生成方案成为构建可靠分布式系统的必要条件。Redis具备高性能、原子操作及简单易用的特性,因此我们可以基于Redis实现全局唯一ID的生成。
摘要:本研究基于2000-2024年沪深A股上市公司年报数据,采用文本挖掘技术构建数字化转型信息披露数据库,涵盖42项数字技术特征词频。数据包含63,055条有效记录,支持数字化转型时序趋势、行业差异、资本市场影响等实证研究。重点探索企业转型强度(kw_sum)与资本市场表现的关系,识别"言-行"匹配度差异,为监管和企业决策提供数据支撑。研究选题涵盖数字金融调节效应、行业异质性
本文全面解析MySQL性能优化的8大核心维度,涵盖硬件系统层配置、关键参数调优、InnoDB引擎优化、查询性能提升、高并发架构设计等。重点包括:NVMe SSD选型与内存分配原则(如innodb_buffer_pool_size占物理内存70%)、索引设计黄金法则、慢查询分析与EXPLAIN解读、读写分离与分库分表策略、MySQL 8.0新特性应用等。文中提供200+优化参数建议、一键检查脚本和监
redis做分布式锁的实战文章
开发环境:System:WindowsJavaEE Server:tomcat5.0.2.8、tomcat6JavaSDK: jdk6+IDE:eclipse、MyEclipse 6.6 开发依赖库:JDK6、 JavaEE5、ehcache-core-2.5.2.jarEmail:hoojo_@126.comBlog:hoojo的博客_CSDN博客-JavaEE,OpenSource 框架,Ja
在存储过程中使用事务,并且使用链接服务器时,报类似下面的错误链接服务器"****"的 OLE DB 访问接口 "SQLNCLI10" 返回了消息 "没有活动事务。"。消息 7391,级别 16,状态 2,过程 proc_SyncDiliveryData,第 20 行无法执行该操作,因为链接服务器 "*****r" 的 OLE DB 访问接口 "SQLNCLI10" 无法启动分布式事务...
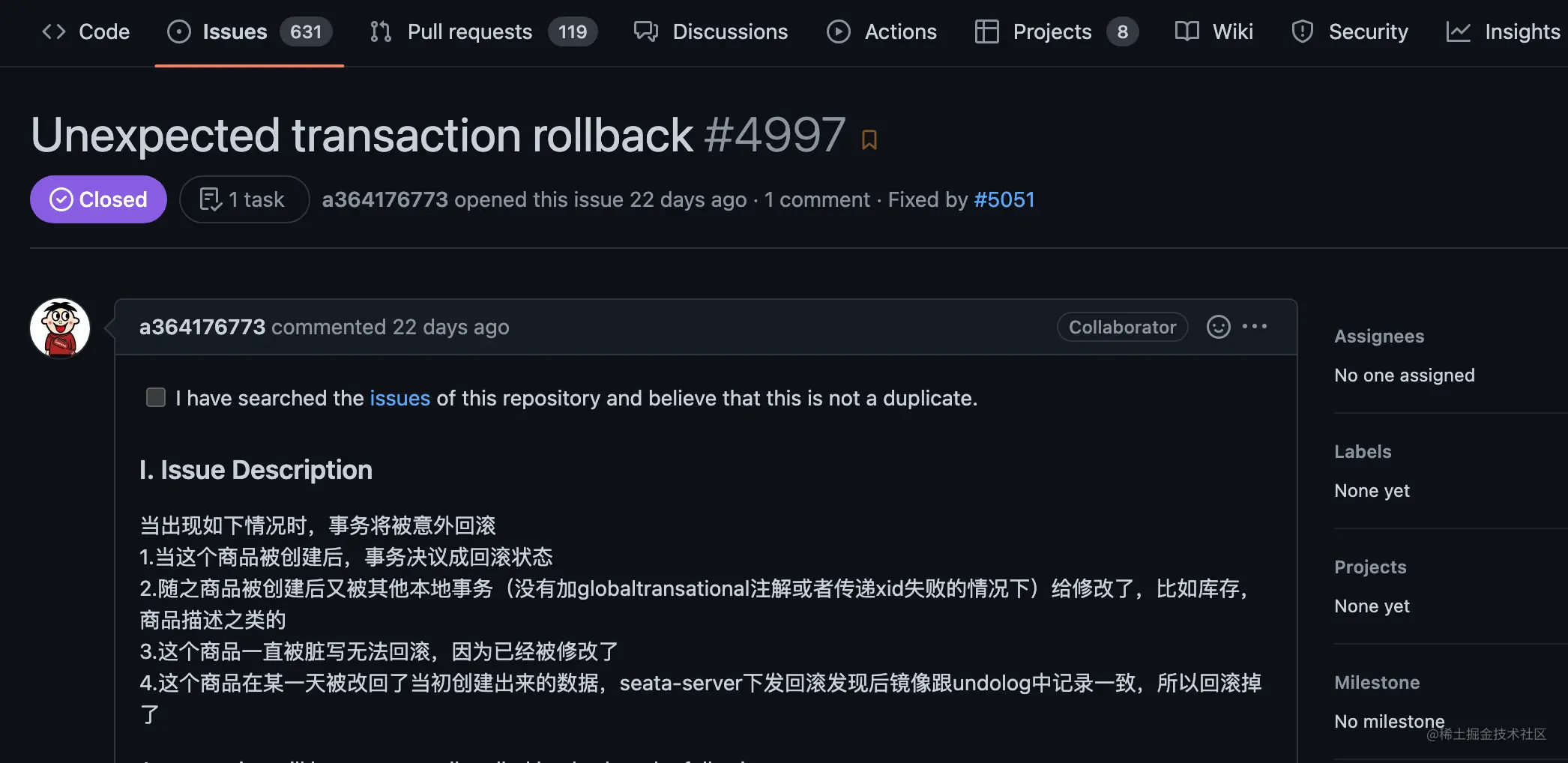
兄弟们,最近处理了一个seata的issue,关于seata分布式事务长期回滚失败后,突然回滚成功了:在执行分布式事务期间,有本地事务与分布式事务操作同一张表中的数据导致脏写产生;在回滚时,seata对比afterImage与当前数据不一致,导致回滚失败,此时会一直重试;当手工校准数据后,某一时刻afterImage与当前数据一致,此时回滚重试成功,ABA问题产生;
数据库
——数据库
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 openEuler 社区
openEuler 社区

 龙虾开发者社区
龙虾开发者社区

 MCP技术社区
MCP技术社区

 DAMO开发者矩阵
DAMO开发者矩阵

 AI编程社区
AI编程社区

 深开鸿 技术专区
深开鸿 技术专区