- @m0_74942241
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
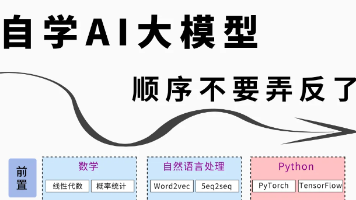
通过以上七个阶段的学习,您将能够建立起对大规模预训练模型的深刻理解,并掌握其在实际应用中的技巧。记得在学习过程中保持好奇心和探索精神,积极尝试新技术并参与社区讨论。希望这份学习路线图能帮助您成功踏上大规模模型的学习之旅!如果您对某个特定阶段或主题有更详细的问题,欢迎随时提问!对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力
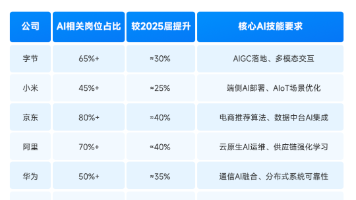
**摘要:**如何高效获取AI领域Offer?**本文提供实操策略: 岗位全景:算法类(LLM/NLP工程师)、工程类(AI应用/Agent开发工程师)、产品类岗位需求与薪资对比,推荐转行友好的AI应用/Agent开发岗。 核心技能:重点掌握Prompt、RAG、Function Calling等四件套,强调动手实践>理论学习。 简历与面试:STAR法则量化项目成果(如RAG系统提升解决率73%)
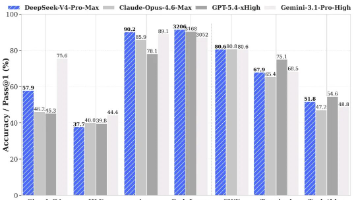
本文以DeepSeek V4为例,系统阐述了AI模型评测的四大维度:认知与推理(SimpleQA、HLE等指标)、长文本处理(MRCR 1M)、智能体能力(SWE Verified)及成本效益(吞吐量、延迟)。通过对比不同模型在各项指标的表现,指出应根据应用场景选择匹配的模型类型(如法律咨询侧重事实准确性,编程需关注工程能力)。文章强调大模型正从文本生成向逻辑决策演进,并附赠大模型学习资源包,助力
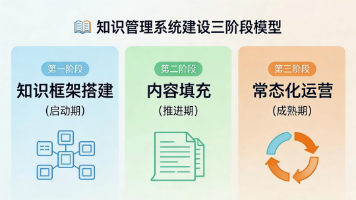
知识管理系统建设三阶段模型:启动期搭建框架(全员参与)、推进期填充内容(激励引导)、成熟期常态化运营(文化沉淀)。关键要素包括一把手推动、AB角机制、激励政策等。常见问题应对策略强调从强制到引导的渐进方式。文末重点推荐AI大模型方向,提供系统学习资源包(含路线图、视频教程、行业报告等),由清华-加州理工双料博士团队研发,助力职业转型。注:后2/3内容为AI课程推广,与知识管理主题关联较弱。
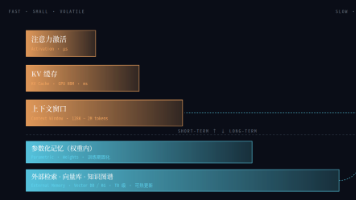
大语言模型的记忆系统可分为短期记忆和长期记忆,两者协同工作。短期记忆受限于算力和显存,核心挑战是降低O(n²)计算复杂度和KV Cache占用,解决方案包括高效注意力机制、KV压缩、位置编码外推等。长期记忆则依赖外部存储和检索系统,如RAG、知识图谱和Agent记忆系统,权衡更新成本与可追溯性。实际应用中需混合使用两种记忆,短期处理即时推理,长期管理持久知识。AI领域尤其是大模型方向职业前景广阔,
我在一线科技企业深耕十二载,见证过太多因技术更迭而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。✅AI大模型学习路线图✅Agent行业报告✅100集大模型视频教程✅大模型书籍PDF✅DeepSeek教程✅AI产品经理入门资料完整的大模型学习和面试资料已经上传带到CSDN的

我在一线科技企业深耕十二载,见证过太多因技术更迭而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。✅AI大模型学习路线图✅Agent行业报告✅100集大模型视频教程✅大模型书籍PDF✅DeepSeek教程✅AI产品经理入门资料完整的大模型学习和面试资料已经上传带到CSDN的

本文提出了一套系统化的大模型开发学习路线,分为四个递进阶段:基础筑基(Python与FastAPI)、核心进阶(LangChain与RAG)、高级应用(Agent开发)和专业提升(微调与面试)。该路线强调从理论到实战的完整闭环,包括Python编程、FastAPI开发、Prompt工程、RAG系统搭建、多Agent协作等核心技能,并配有企业级项目实战。文章指出AI应用开发人才缺口巨大,掌握RAG、
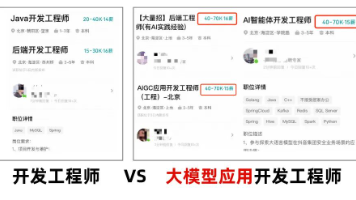
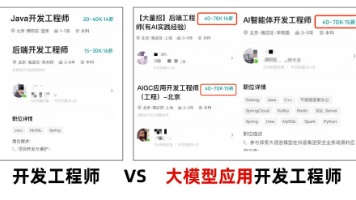
文章详细阐述了AI技术如何重塑2025年前端开发领域,指出传统前端开发面临的挑战,以及AI如何提升代码生成效率、测试覆盖率和故障排查速度。文章进一步探讨了前端工程师在AI时代的新定位,强调了不可动摇的技术基础(HTML、CSS、JavaScript),AI工具链的重要性(代码生成、设计到代码、测试自动化、调试排障),以及Prompt工程的核心能力。此外,文章还介绍了如何将AI集成到产品中,构建智能
本文系统梳理了大模型产品经理的学习路径,涵盖计算机科学基础、AI/机器学习知识、大模型核心技术、产品管理技能及实战经验四大模块。随着AI行业爆发式增长,国内AI人才缺口超500万,相关岗位薪资涨幅达40%+,算法类岗位平均年薪36.9万。为帮助从业者抓住机遇,文章提供从零基础到精通的完整学习框架,包括数据结构、Python编程、分布式训练、产品设计等核心内容,并强调持续学习行业新动态和软技能提升的