登录社区云,与社区用户共同成长
邀请您加入社区
Codex 不是简单的代码补全工具,而是 OpenAI 面向软件工程打造的「全链路自主研发智能体」。它的核心优势不在于单文件代码生成,而在于**项目级理解、长任务自治、多工具联动、工程规范约束、上下文压缩自愈**,是企业级 AI 编程、自动化工程、Agent 落地的核心底座。
摘要(149字): NSK W0601MA-2Y-C3T1滚珠丝杠为MA型精密标准品,采用内循环设计,轴径6mm、导程1mm,提供70mm有效行程(最大80mm)。C3级超高精度,T型微间隙(轴向间隙<0.005mm),动载680N,静载920N,转速3000rpm,摩擦力矩<0.3N·cm。特点包括极低摩擦、内循环紧凑结构、轴端预加工即装即用,适配微型仪器。典型应用于光学对焦、生化微量泵、半导体
NSK RNFTL2005A2.5S滚珠丝杠是R系列搬送专用产品,采用单法兰盘管循环结构,带防尘密封圈(S规格)。核心参数:20mm轴径、5mm导程、无预紧设计(间隙≤0.10mm),动/静载荷分别为7500N和14200N。螺母重0.37kg,配套丝杠轴重2.17kg/m。技术特点包括低摩擦顺滑运行、薄密封防尘、分体式供货支持轴端定制,适用于中等负载自动化设备。典型应用涵盖搬运机器人、包装机械、
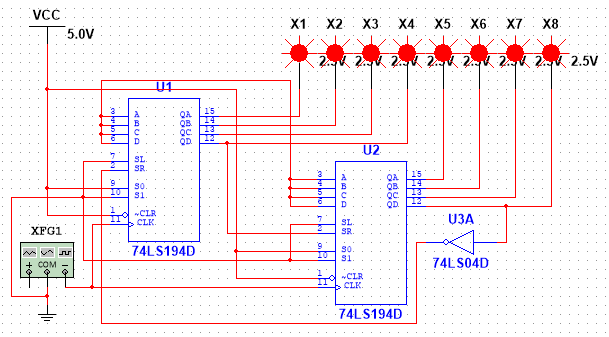
摘要:该彩灯控制器设计采用两片级联芯片实现8灯循环点亮/熄灭功能。通过右移(Sr=1,Sl=0,S1=0,S0=1)和左移(Sr=0,Sl=1,S1=1,S0=0)模式控制灯光流动方向,并利用74LS160计数器实现功能切换。系统包含三种工作模式:右移、左移和闪烁(S1=1,S0=1),通过组合逻辑电路实现循环控制。设计中考虑了开机复位(电阻提供瞬时低电平)和芯片优化(复用多余逻辑门),但组合逻辑
CentOS-8.2.2004-x86_64-dvd1在VMware 15.5.0上安装_________________________________________________________第一步:CentOS-8.2下载地址:http://isoredirect.centos.org/centos/8/isos/x86_64/除了标红框的其他的都可以下载,只是下载速度不同下载好的文件
由浅入深带你了解getchar()的用法!!
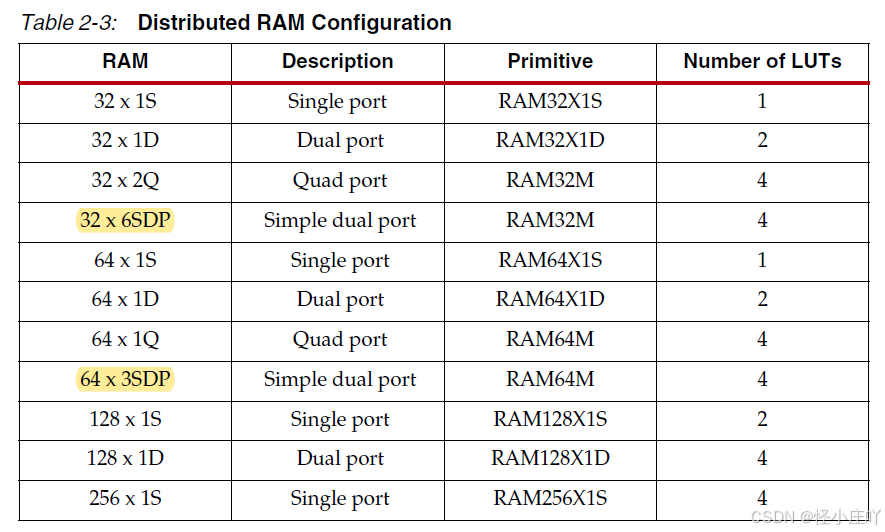
在通过文档《ug474_7Series_CLB.pdf》学习7系列CLB过程中,对7系列CLB中的分布式RAM(Distributed RAM,DRAM)进行展开学习,遂就有了此文。
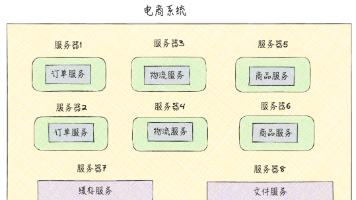
本文系统介绍了分布式系统的概念、特点及其与单机系统、集群的关系。分布式系统通过将计算和存储分散到不同网络节点,解决了单机系统在性能、扩展性和可用性方面的瓶颈。文章对比了单机、集群和分布式架构的差异,指出分布式系统具有分散性、并发性、异构性等特点,同时分析了分布式与微服务的联系。虽然分布式架构能提高吞吐量和可扩展性,但也存在响应延迟增加、设计复杂度高等问题。最后强调应根据实际业务需求选择合适的系统架
多参数超声波风速风向传感器采用超声波脉冲技术,通过测量声波传播时间差或多普勒频移计算风速和风向。该设备可同步输出风速、风向实时数据,支持RS485、4G无线传输,并兼容温湿度、大气压力等环境参数集成监测。外壳为ABS工程塑料,无机械部件,免维护且无需现场校
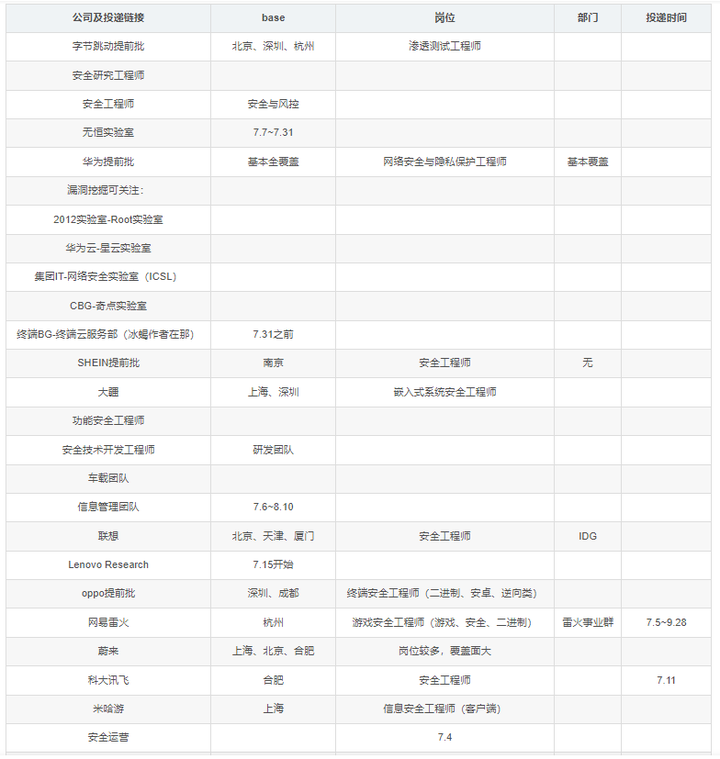
作为一名网络安全工程师,我曾经在大三的秋招中斩获🔟+个offer🌼,现在任职于国内某知名互联网公司。转眼2024年秋招又快到金九银🔟的关键阶段了,我这里整理了最新的校招安全岗位介绍和大厂面试题,分享给准备参加秋招的同学们。想趁这届社招跳槽转行的也可以看看~
产业数字化就是指在新一代数字科技支撑和引领下,以数据为关键要素,以价值释放为核心,以数据赋能为主线,对产业链上下游的全要素数字化升级、转型和再造的过程。产业数字化能够助力传统企业蝶变,再造企业质量效率新优势,能够促进产业提质增效,重塑产业分工协作新格局,孕育新业态新模式,加速新旧动能转换新引擎。
中小企业做自动化,最怕的就是项目上线后算不清账。一个流程如果每月只跑几次、规则经常变、还要大量人工判断,即便接入AI Agent,也很难形成稳定ROI。财政部、工信部在2025年中小企业数字化转型城市试点通知中提出,要面向企业真实需求,开发一批行业属性强、赋能效果优的“小快轻准”解决方案,并通过产业真实场景验证人工智能、数据要素等新技术赋能中小企业提质增效的可行路径。政策口径已经很明确,中小企业自
欢迎了解 Hi AI 全球 AI 创作季
真实场景的项目开发是检验能力的核心。华为开发者联盟官网的“HarmonyOS”专区提供了完整的知识图谱,其中技术概览模块能快速建立对分布式能力、原子化服务等核心特性的认知,而ArkTS语言指南则详细解析了这一TypeScript超集的声明式UI语法与状态管理逻辑,对有JS/TS基础的开发者极为友好。一是示例代码与Codelabs,从简单的页面跳转demo到包含网络请求、数据持久化的完整案例,
对比维度赤友NTFS助手格式化为exFAT强制原生写入是否格式化❌ 否✅是(数据全清)❌ 否数据安全风险🟢 极低🟡 中等(无日志)🔴极高操作难度🟢 极简(GUI)🟡 中等🔴 复杂(终端)稳定性🟢 高(商业驱动)🟢 高🔴极差读写性能🟢 良好🟢 良好🟡 不稳定macOS新版兼容✅ 支持✅ 支持❌已封禁推荐指数⭐⭐⭐⭐⭐⭐⭐❌ 不推荐当Mac无法保存文件到NTFS移动硬盘时,本质
https://blog.csdn.net/eidolon_foot/article/details/152307955?sharetype=blogdetail&shareId=152307955&sharerefer=APP&sharesource=2401_85812043&sharefrom=link
从上述成绩分布来看,大家最后总评都还挺高的;听闻,这次期末改卷相对松,倒是平时分上有些差异(头歌平台上的实验占比25%、作业占比20%,小班讨论占比10%):24级的人工智能课程有些调整,下述内容本次期末考试整体。(含 2015–2020 年以及部分年份的计科、智能和计拔的期中、期末试卷):文件中的参考答案仅供对照参考,可能存在个别错误。例如,,使用时请注意识别。:本次考试时长为,虽然概念题较多,
综合今日工信部关于人工智能 + 软件的政策吹风、WAIC 行业分论坛的技术风向、MCP/A2A 智能体互联通用标准、私有化数据安全刚需、服务商优劣分层判定、开源组件安全防控等全行业趋势,叠加低代码国标、数据安全相关法规的硬性要求,本节一方面梳理企业数字化选型的全维度避坑方法,同时结合 CSDN、掘金等主流技术博客平台统一公示的 5 类 AI 审核营销违规判定标准,同步科普行业技术内容创作的合规红线
经过调试每一个环境发现问题处在通过路径访问图片的问题上,鸿蒙不能直接通过uri来读取相册里面的数据,接口返回的uri是一个虚拟的地址。
很多企业第一次采购AI智能体时,都会遇到一个很现实的问题:看起来功能都差不多,报价为什么能差好几倍?有的厂商几十万元就能做,有的方案直接报到上百万元,甚至还要根据系统数量、业务复杂度单独估价。企业老板看到这种报价,第一反应通常都是:AI智能体是不是水分太大了?但真正做过项目后会发现,价格差距并不完全来自模型。大模型只是智能体的一部分,真正花钱的地方,是系统怎么接、流程怎么跑、数据怎么管,以及项目上
【摘要】工业机器人选型应基于工序需求而非外形偏好。复合机器人(如富唯ICR系列)凭借±0.05mm精度和快速部署优势,已在储能、汽车等标准化场景验证ROI,单工序回本周期约2年;人形机器人(如富智系列)则更适合复杂长序列任务,但需匹配高人工成本场景。医疗领域已实现99.9%抓取成功率等精密操作,而汽车巨头计划2027年量产人形机器人用于装配。建议企业先拆解工序,通过小范围验证节拍和良率,避免为技术
云厂商把模型、知识库和工作流装进一套开发平台;行业软件公司让智能体进入财务、金融和企业管理系统;一些垂直应用厂商直接瞄准营销、客服、风控等具体业务;还有一批从RPA和流程自动化走出来的公司,试图解决智能体最后一步的问题——让AI真正进入系统执行任务。这也是观察垂直智能体市场最容易踩中的误区:如果只比较模型参数、知识库数量和插件数量,很难看清一家厂商真正擅长什么。决定垂直智能体能否落地的,往往不是它
鸿蒙提供的新闻客户端代码,默认是先加载所有数据的,不过现在新闻分类中,一般是没有‘所有/All’这个分类标签选项,都是具体的分类标签选项,而且初始化的时候就会显示默认分类标签选项是显示选中状态的(一般默认是第一个分类标签),笔者在鸿蒙代码的基础上进行了修改。目标:默认加载显示第一个新闻分类标签的列表数据,并且第一个新闻分类标签显示被选中状态,点击其他分类标签后,加载显示对应数据,被点击的分类标签显
使用CSDN已经好几年了,但是从来没有写过过博客。CSDN对我来说主要是查找解决代码报错,安装开发软件过程中碰到的各种千奇百怪问题。反观我周围同学搭建开发环境很少向我一样碰到稀奇古怪的问题,有时候我都怀疑自己为什么这么点儿背。日积月累,亲手解决的问题逐渐增多,我从一个小白逐渐入门了,由衷的感谢csdn上的各位大佬的间接经验,无数次救我于水火之中。现在研究生在读,研究方向是计算机视觉。主要使用的语言
不多bb直接进入正题首先呢,我们需要去鸿蒙官网下载HUAWEI DevEco Studio链接:https://hmxt.org/deveco-studio当然了 这些东西在华为的文档里面都有,下面主要是我出现的几个问题,以及解决办法。首先打开这个软件并且创建一个项目,就跟Android新建项目一样即可,需要下载JDK和SDK,自动下载这里我们选择java语言然后就是较为熟悉的界面了在这里我也不改
为了获得最佳的天线性能,通常需要使用合适的传输线和天线匹配网络,以确保驻波比尽可能接近于1,从而最大程度地减少信号的反射和损失。较高的辐射效率意味着较少的功率被损耗在天线内部,更多的功率被辐射出去,天线性能更好。较高的方向系数意味着天线在特定方向上具有更集中的辐射或接收能力,可以实现更远的传输距离或更强的信号接收。较高的辐射电阻意味着较少的功率被转化为热能,天线的效率更高。(Directivity
上篇文章我们只是简单的使用ngrok映射22端口用于远程连接,后续我们想更多的利用这一点多做几个端口映射。比如我们日常用的数据库mysql(默认端口3306),下面就开整吧1、首先我们进入官网这边有个菜单 Tutorials,这里我们可以看到他是有一个配置文件的2、下面我们就看看这个配置文件怎么配置,这边进去看看3、进去之后这里有详细的讲解4、我们就直接来实操一下吧,先找到配置文件,官网有介绍配置
记载一次Ngrok 使用 ,内网穿透 ,开发微信公众号调试1.首先附上官网地址:https://dashboard.ngrok.com/下载2.授权码./ngrok authtoken 你的授权码自动存储你的授权码信息在本地根据需要,运行命令开发端口ngrok http 8080#端口可根据自己项目端口更改如果有需要固定外网地址可以去官网获取(付费~~~~~~)这样就可以完成内网穿透了~~~~~~
一些Chatgpt润色文章常用的命令。
前言: 有时想要通过外网地址访问到自己的项目,但是市面上的第三方内外穿透软件有很多,但是大多都是要收费的,而 ngrok 小米球是国内一个免费内网穿透软件。通过它也可以实现内网穿透映射到外网访问项目。一,注册小米球账号1. 注册一个小米球账号,获取免费的Token2. 在后台首页下载对应版本客户端(我这里下载的是window版)3. 将下载的压缩文件解压后放到需要启动的服务器上二、修改ngrok.
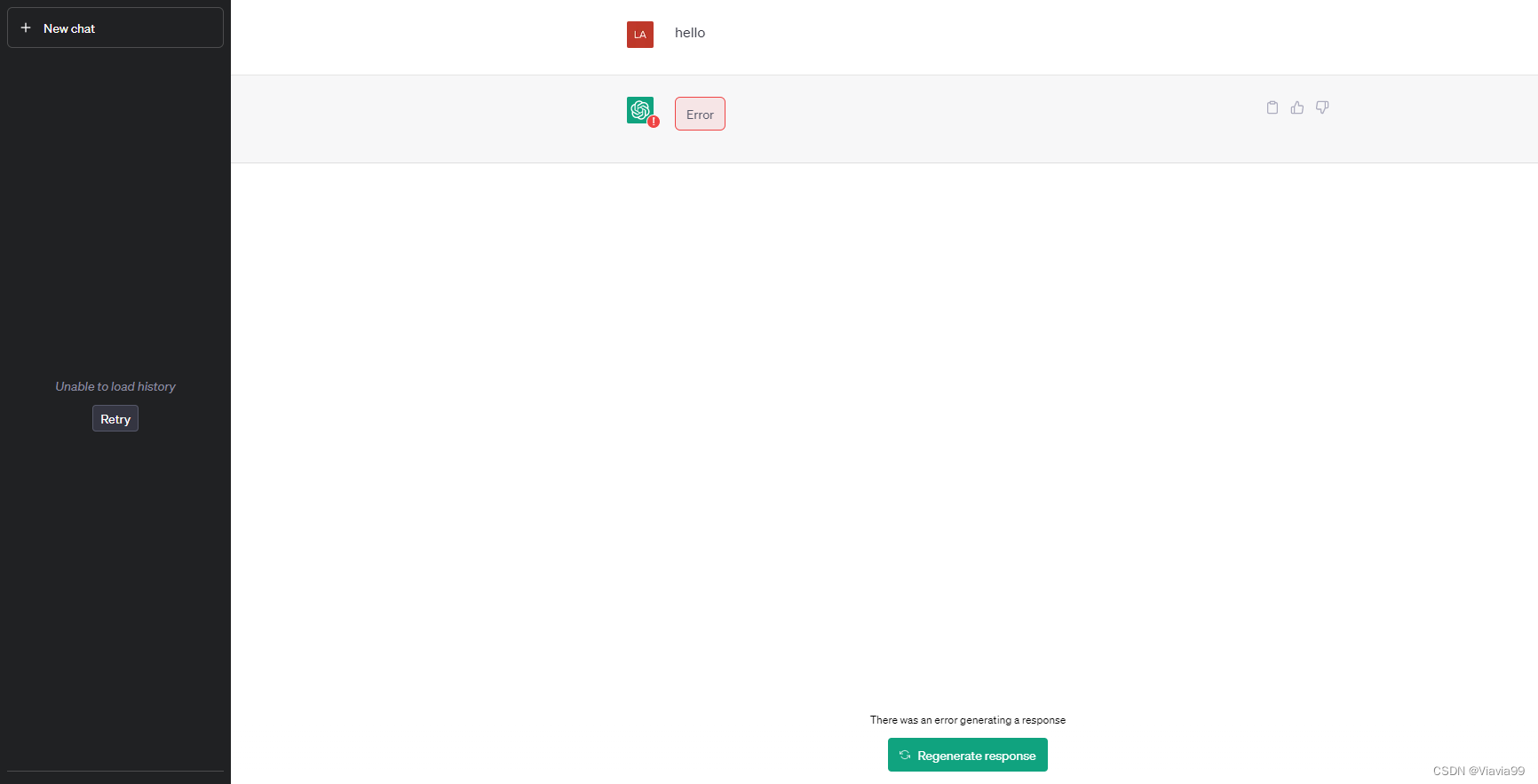
左栏是unable to load history,右栏会回答Error并带有红色感叹号,换了很多节点还是这样,请问应该怎么解决呀?在使用chatgpt时出现如下页面。
经验分享
——经验分享
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区

 DAMO开发者矩阵
DAMO开发者矩阵



 2048 AI社区
2048 AI社区

 深开鸿 技术专区
深开鸿 技术专区








 智能体开发者社区
智能体开发者社区




 HarmonyOS开发者社区
HarmonyOS开发者社区
 openEuler 社区
openEuler 社区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区