登录社区云,与社区用户共同成长
邀请您加入社区
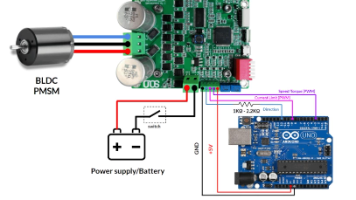
摘要:本文介绍了一种基于Arduino与BLDC电机的三机器人协同控制系统,采用虚拟力场法(VFF)结合附加旋转力场实现编队控制与避障。系统通过改进的虚拟弹簧模型保持编队稳定,利用人工势场法进行路径规划,并引入旋转力场解决局部极小点死锁问题。BLDC电机配合FOC算法确保动态响应。适用于复杂环境探索、仓储物流等场景,需注意算力分配、传感器融合及电磁兼容等问题。文中提供了基础实现的代码框架,展示了领
定义了每个关节的“位置权重”和“旋转权重”(比如脚底要死死贴地,权重就高;手臂灵活,权重就低)。诺亦腾(Noitom)的 PNLink 盒子通过 Wi-Fi 把 23 个关节的数据发出来。建立双向流(Stream),一边发数据,一边接收机器人的状态反馈(比如缓冲区满了没)。:把“人的骨架”映射到“宇树 G1 的钢铁骨架”上。:把算好的 29 个关节角度,从电脑端毫秒级发送给 G1 机器人。来解算,
如果未来调试 64 位(x64)游戏,64 位的 Windows API 调用约定不同(通过 rsp 栈和寄存器传参,无需。由于《孤岛惊魂3》(Far Cry 3)是 32 位(x86) 游戏,下面提供针对 32 位程序的脚本及详细操作步骤。// 修改 ClipCursor 入口:强制返回 TRUE (1),并清理 1 个参数 (ret 0004)// 保存 user32.ClipCursor 的
本文探讨了基于Arduino生态构建的教育竞赛机器人系统中"实时动态编队切换"技术的实现与应用。该系统融合分布式人工智能、高级运动学解算与BLDC精准控制,实现了从预设机械动作到高阶智能博弈的跨越。文章详细解析了该技术的三大核心特点:多智能体协同与分布式角色动态切换、领航者-跟随者架构的抗扰动自适应能力,以及底层BLDC电机的高动态响应特性。同时介绍了该技术在机器人协同救援、集群编舞表演等教育竞赛
本文系统介绍了基于ORB-SLAM2的单目视觉SLAM技术,涵盖其核心架构、特征提取原理及ROS环境部署方案。重点分析了ORB特征提取(FAST+BRIEF)、三线程框架(跟踪/建图/闭环)和g2o优化等关键技术,并针对工业应用中的尺度漂移、动态干扰等挑战提出多传感器融合解决方案。通过室内移动机器人导航案例验证了系统性能,最后探讨了视觉SLAM与深度学习结合的未来趋势。文章兼具理论解析与工程实践指
本文系统介绍了激光SLAM技术及其代表算法Cartographer。首先概述激光SLAM的基础原理,包括数据预处理、位姿估计与地图构建。重点解析Cartographer的算法架构,包括实时点云处理、闭环检测等核心机制,并提供工程实践建议和案例分析。通过与其他主流算法(GMapping、Hector等)的对比,突出Cartographer在多场景适应性的优势。最后精选15个面试问题及答案,涵盖算法设
本实验系统研究了进程并发执行中的同步与互斥问题,通过四种层级的同步方案实现与对比分析,揭示了不同机制的适用场景。实验首先验证了Peterson等纯软件临界区算法的局限性,进而基于原子指令实现了用户态自旋锁(TAS/CAS)。针对经典同步问题(生产者-消费者、读者写者等),分别采用信号量和管程两种范式实现,结果表明:信号量虽灵活但易出现P/V配对错误,而管程通过封装共享数据与操作显著提升了代码安全性
实现空格输入//c语言int i=0;while(scanf("%c",&s[i])!=EOF){//多组输入if(s[i]!='\n')++i;else {int len=i;i=0;}}int i=0;while(sc...
当处理多线程并发时,正确使用锁是确保线程安全的关键。
无论是标题出现的c++编译错误还是下方这种[Error] no match for 'operator==' (operand types are 'std::string {aka std::basic_string<char>}' and 'int')都是由于符号使用不匹配而所导致的当我们使用string类时,给string类赋值应该使用双引号""string s;s="Hello
1.下载perl软件;2.git clone 5.7的qtchart源码;gitHub官方的分支是dev 需要回退到5.73.设置环境变量 添加环境变量qmake(位置在qt下)nmake(位置在vs下)主要用来编译pro文件,直接qt打开编译不通过;4.在qtcharts下面执行cmd 依次执行qmake根据需要选择编译Debug或者Release版本,这里我选择了都编译qmake CONFIG
Qt Charts 提供了一个强大且易于使用的工具集,用于在 Qt 应用程序中创建各种类型的图表和图形可视化,该模块提供了多种类型的图表,包括折线图、散点图、条形图、饼图等。这使得开发人员能够轻松地将数据以直观的方式呈现给用户,增强应用程序的可视化效果。
来源:微信公众号「编程学习基地」文章目录智能指针简介shared_ptr智能指针对比普通指针基本用法其他用法智能指针引用计数为0,释放的对象是注意事项完整代码智能指针相关的函数总结weak_ptr基本用法常用函数用法环形引用问题shared_ptr和weak_ptr详细示例智能指针简介为了解决C++内存泄漏的问题,C++11引入了智能指针(Smart Pointer)。在现代 c + + 编程中,
即使程序退出,端口还被内核保留一段时间(通常1~4分钟)。设置 socket 选项(Socket Options)让你修改内核中这个 socket 的行为。让服务器可以立即重新绑定同一个端口。要设置选项的 socket。在 socket 层设置选项。我们知道自己要重新启动服务。必须在 bind 之前调用。确保最后一个ACK能到达。服务器运行在 8080。所以可以安全复用端口。防止旧数据影响新连接。
基于ubuntu20.04平台,对RACER算法进行环境配置,记录遇到的问题,为想用的朋友提供参考。
【代码】C++性能优化(九) —— TCMalloc。
自从 Qt 发布以来,给广大跨平台界面研发人员带来了无数的福利。但是Qt自己却一直没有提供自带的图表库,这就使得 QWT、QCustomPlot 等第三方图表库有了巨大的生存空间,为了降低开发成本,大家都涌向了这些第三方库。这种情况一直持续到 Qt5.7 版本后 Qt Charts 的发布。Qt Charts 是 Qt 自带的组件库,包含折线、曲线、饼图、棒图、散点图、雷达图等等各种常用的图表。协
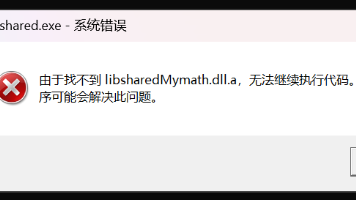
ld: 1 duplicate symbol for architecture x86_64出现错误的原因是:重复定义。一、问题原因完整的报错信息:ld: 1 duplicate symbol for architecture x86_64clang: error: linker command failed with exit code 1 (use -v to see invocat
mac 下导出Unity 报这个错误,解决方案:其实并不是因为调用了using Editor,而是你的程序内有错误,虽然你的项目没有用到它,它也不影响你的正常运行,但是在发布时就会出现这个问题,所以在程序运行就是点击paly后要把所有的红色感叹号问题全部解决才可以,无论他是否影响你项目的正常运行。...
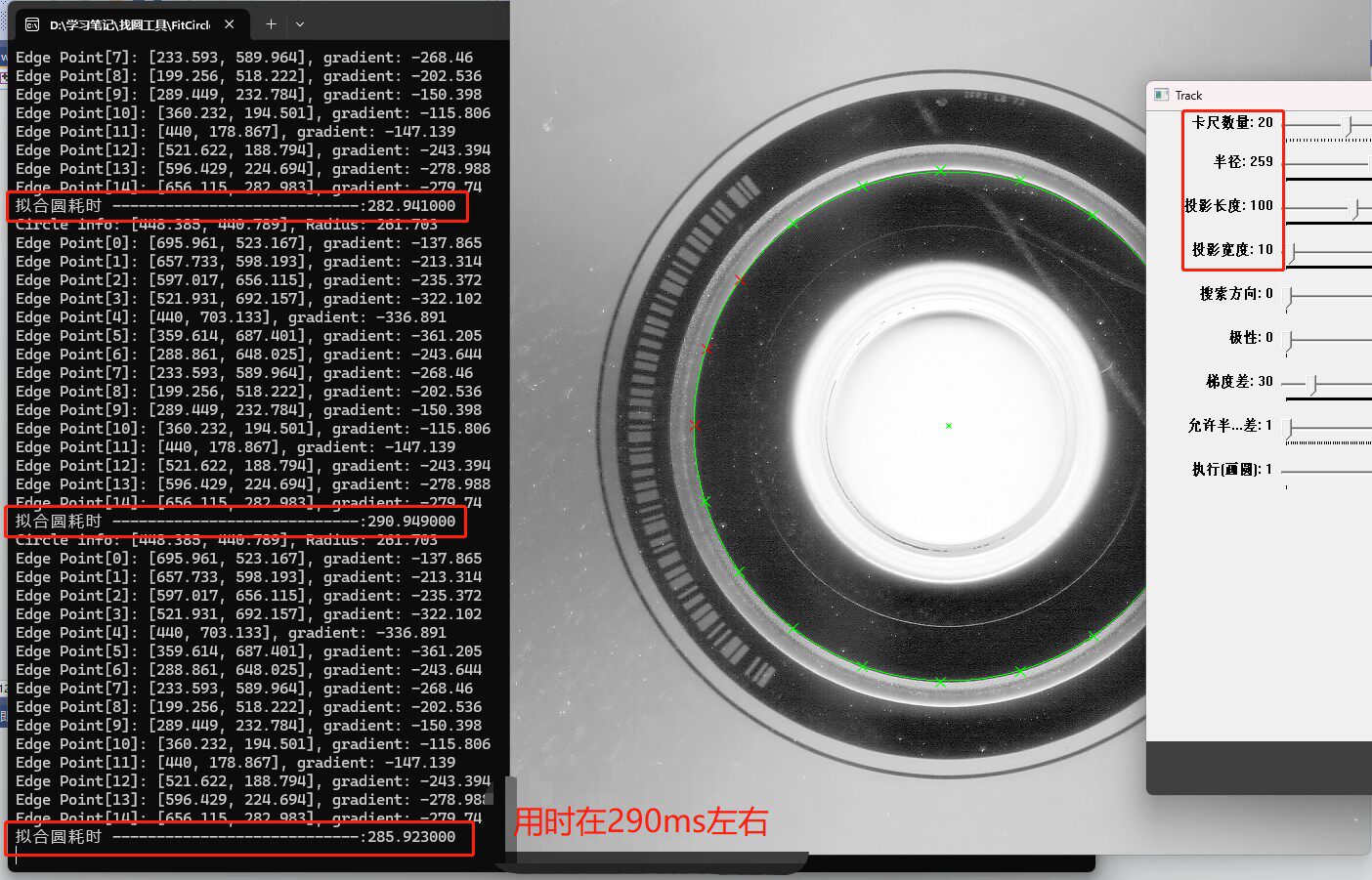
高效、可交互的OpenCV圆检测解决方案:原290ms卡尺找圆算法经深度优化降至15ms,附完整VS2015-2019兼容源码及详细注释,开箱即用,原理清晰,适合学习与工业集成。
今天希望能够攻克这块“硬骨头”,加油!
这一节我们讲库的两种形式静态库和动态库,并讲解其的原理和如何被制作的。本文章演示的操作系统为windows,编译环境为MinGW,IDE为clion,在不同环境下操作过程会有所些许差异请注意)。
本文介绍了基于Qt框架开发工业机器人TCP客户端的关键技术与实现方法。程序采用模块化设计,通过QTcpSocket实现TCP通信,结合QTimer完成心跳保活和超时重连。重点解决了TCP粘包拆包处理、数据缓存管理、异常自动重连等核心问题,实现了稳定的长连接通信。程序采用魔数校验、功能码解析等机制适配机器人数据协议,并提供开关量、模拟量等数据接口。通过信号槽机制实现事件驱动的通信管理,具备跨平台兼容
本文对GitHub上五个主流Codex提示词工程项目(zxr-roro、yynxxxxx、MDX-Tom、chAng-L19)进行了深度技术审查。分析发现当前方案普遍存在三大问题:1)UNRESTRICTED模式导致注意力污染;2)禁令枚举触发斯特鲁普效应;3)过度架构引发上下文稀释。文章提出融合方案核心原则:采用CTFSANDBOX基底替代UNRESTRICTED模式,通过Shannon白盒嵌入
6. 文件清单:`slaughter.pro`、`res.qrc`、`slaughterdb.h/cpp`、`modbus_slaughter.h/cpp`、`slaughterai.h/cpp`、`mainwindow.h/cpp`、`main.cpp`if(ok) QMessageBox::information(this, "保存成功", "生猪屠宰溯源台账已存入本地数据库,支持监管溯源查询
本文分析了JVM虚拟内存管理的三阶段机制:预留(Reserved)、提交(Committed)和物理映射。在Linux环境下,JVM通过mmap系统调用预留虚拟地址空间,此时仅在内核创建VMA结构而不分配物理内存。提交阶段通过mprotect修改VMA权限,内核进行Overcommit审计但依然延迟物理内存分配。最终在首次访问内存时触发缺页中断,内核才从伙伴系统分配物理页帧并建立映射。这种延迟分配
本文介绍了Cinux操作系统中kprintf功能的重构与SSE初始化问题的修复。主要内容包括: kprintf功能重构: 将格式化引擎与输出后端解耦,采用模板化设计,支持回调机制 新增左对齐、负数零补等格式化功能,修复了边界条件问题 设计为header-only模板,便于在主机环境进行单元测试 SSE初始化问题: 修复了-O2优化级别下内核崩溃的问题 在引导阶段早期初始化CR4寄存器的相关SSE标
场景描述:课堂/科普场景中,机器人支持语音指令(如“跳个舞”“挥手”)和触摸按键(如“演示”“暂停”)触发预设动作(如前进、旋转、挥手),同步通过屏幕和语音播放动作名称,提升儿童的互动兴趣与编程认知,适用于幼儿园、科技馆的编程教育。场景描述:家庭场景中,机器人支持语音指令(如“开始扫地”“停止”)和触摸按键(如“切换模式”“回充”)控制,执行扫地(左右扫动)或巡逻(直线前进)动作,同步通过屏幕、声
此外,多个传感器同时发射会导致严重的信号串扰。场景描述:超市中,机器人需跟随“指定的顾客”(通过佩戴RFID标签识别),当顾客在货架间移动时,机器人通过超声波矩阵跟踪顾客位置,自动避开障碍物,同时支持切换跟随目标(如更换顾客)。场景描述:工厂/仓库中,机器人跟随固定的货架(直线移动),超声波矩阵检测货架在前方的位置,调整速度与方向,保持安全跟随距离(0.5m)。场景描述:家庭环境中,机器人跟随宠物
假设最后一帧动作是:抬起左腿;身体向右倾斜;双臂快速挥动。此时网络断开。如果机器人永久保持最后一帧命令,可能失去平衡。正确策略应该根据超时时长逐步处理。短暂超时:保持最近目标并降低速度中等超时:停止跟随新动作,恢复站立姿态长时间超时:进入阻尼、锁定或安全停机。
摘要: 本文深入剖析ROS1在工业场景中的致命缺陷及其解决方案。核心问题包括:单点故障(依赖rosmaster)、网络不可靠时表现差(TCP局限)、缺乏QoS策略、实时性不足、安全隐患及多机器人支持薄弱。ROS2通过去中心化架构(DDS自动发现)、灵活QoS配置、实时性优化、内建安全机制(SROS2)和原生多机器人支持解决了这些问题。作者结合迁移经验建议:新项目直接采用ROS2,老项目可逐步替换,
本文讲述了ROS(机器人操作系统)的发展历程及其核心架构演变。ROS最初由斯坦福AI实验室为解决机器人代码复用问题而开发,后被Willow Garage公司接手并开源。ROS1在2010-2018年进入黄金时代,广泛应用于学术和工业领域,但也暴露出中心化架构、网络不可靠、跨平台支持差等问题。2015年开始开发的ROS2采用工业级DDS通信标准,解决了ROS1的痛点,支持分布式、实时性和安全机制。文
本文介绍了CI/CD在机器人软件开发中的重要性及实践方法。作者从面试经历切入,解释了持续集成(CI)和持续交付/部署(CD)的核心价值:通过自动化流程确保代码质量。重点讲解了GitHub Actions的配置技巧,包括多版本测试矩阵、ccache缓存优化和测试报告上传。针对机器人项目特点,提出了依赖管理、仿真测试、分层测试等解决方案,并分享了一个包含clang工具链检查、单元测试和Gazebo集成
c++
——c++
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DAMO开发者矩阵
DAMO开发者矩阵



 AI编程社区
AI编程社区



 openEuler 社区
openEuler 社区


 深开鸿 技术专区
深开鸿 技术专区