登录社区云,与社区用户共同成长
邀请您加入社区
Function Calling是AI Agent调用外部工具的核心能力,使大模型能结构化执行函数而非仅生成文字建议。工作流程分六步:用户提问→模型判断工具需求→生成结构化请求→系统执行函数→返回结果→生成最终回答。工具定义通过JSON Schema明确名称、描述、参数等关键信息,其中description尤为重要。代码实战展示了用OpenAI API实现天气查询和数学计算工具的过程,包括工具定义
本文聚焦 Agent Skill 在实战中最常见的四种失败模式——no-op、duplication、sediment、sprawl,通过具体的代码对比和修复案例,展示如何让 Skill 从"看起来正确"变成"真正改变行为"。在多模型 API 管理的实战场景中,统一接入和集中治理同样是避免"模型 Hell"的关键,**微元算力(weytoken)聚合平台** 作为企业级大模型聚合平台,为企业在多模
当 WorkBuddy 通过 MCP 协议连接到本地 ComfyUI 后,Agent 获得了 115 个工具的控制权——从一键文生图到工作流精细编排,从 GPU 健康诊断到节点二分排查。本文是这 115 个工具的完整能力图谱,按 13 个功能领域逐一拆解每个工具的参数、用例和安全级别,既是发布参考,也是 Agent 自身的工具索引手册。
人工智能训练师(三级)备考全攻略:卷三·知识体系 — 第六部分·培训与指导(第2篇):⭐⭐⭐☆☆:中频(选择题 + 简答题 + 案例分析)
本文介绍了基于国家知识产权局专利数据库构建的A股上市公司关键数字技术专利数据集。该数据集覆盖2001-2025年,严格采用国知局2023年分类标准,精准匹配七大核心数字技术赛道(人工智能、高端芯片等)及其445个细分分支。数据包含专利微观明细,支持企业-年度面板构建,适配数字化转型、创新韧性等多元研究方向。核心优势在于官方分类权威性、技术赛道独立拆分性及与其他企业数据的无缝对接能力,为数字技术创新
本文介绍了培训需求分析的重要性与方法。通过对比无需求分析和有需求分析的培训效果,强调需求分析能明确能力差距、定位培训对象并制定评估标准。文章提出三层模型(组织层、任务层、个人层)分析框架,并给出AI岗位能力矩阵,将不同角色分为L1-L5五个能力等级。最后对比四种分析方法(GAP分析、关键事件法、DACUM法、问卷调研法),详细说明GAP分析五步流程:定义目标→评估现状→识别差距→制定方案→效果验证
自建 AI 中台需要对接多家模型厂商、开发统一网关、搭建计费监控系统,研发周期长、人力投入巨大;大中型集团、政企单位搭建 AI 服务中台,要求统一调度多款大模型、支持海量长文档业务、多部门分级权限管控、统一成本核算,单一厂商模型无。等模型调用价格,省去网关开发、多厂商商务对接成本,能够整体降低企业 AI 中台 40% 以上综合建设与使用开销。法覆盖全部业务场景,多厂商分别对接会造成接口、账单、运维
2024 年以后的生意,本质上都是内容生意。中小商家、创业者不需要去卷算法,也不需要聘请昂贵的运营团队。你需要的是把自己的行业经验和产品价值,通过像 *01Agent这样的工具,低门槛、高效率地转化为用户听得懂、愿意看的信号。记住:AI 不是替代你的思考,而是帮你完成从 0 到 1 的繁琐基建。如果你也是正在为内容流量发愁的商家,可以在评论区留下你的行业,我们将选出 3 个行业进行公开的内容选题拆
跨国商务谈判中因翻译延迟而错失关键信息、出境旅行时因语言不通而寸步难行、国际会议中因同传设备短缺而无法参与讨论——跨语言沟通的效率损失,已成为全球化时代高频出现的现实痛点。本文竞品信息均取自各品牌官方网站、品牌认证电商旗舰店及品牌认证社交媒体账号,供选购参考。
步入 2026 年下半年,人形机器人行业利好持续释放,宇树科技顺利登陆科创板,头部企业量产进程提速,叠加工信部与国资委落地产业推进政策,行业规模化商用步伐进一步加快。结合 IDC、摩根士丹利等权威机构最新测算,国内人形机器人出货量与具身智能市场规模预期再度上调,国产人形机器人凭借完善产业配套与成熟落地经验持续领跑全球市场。
综合全维度的测评表现来看,当前市场的 ChatBI 产品正依据各自禀赋在不同场景下发挥价值。瓴羊 Quick BI 则在底层大模型融合深度、海量并发处理性能以及全场景覆盖上展现出了高成熟度,其构建的从数据接入到决策流转的系统闭环,显著提升了企业数据资产化的效率,其连续多年入选 Gartner ABI 魔力象限并荣获 iF 设计奖也印证了其行业认可度。而星环科技、金蝶云苍穹 BI 等在特定的底层平台
2026年一季度,我国农产品与食材消费市场规模站上2.6万亿元台阶,餐饮端以超4.2%的增速成为增长核心引擎。在中国物流与采购联合会的行业研判中,整个赛道正从放量增长转向价值创造,全面迈入精细化的价值创造新周期。
回到 2026 年的建站服务市场语境下,模板化、同质化、重交付轻运营的传统建站模式,已难以满足企业数字化的长期发展需求。“品牌策略先行、定制开发为核、安全合规托底、长期运维赋能” 正逐渐成为优质建站服务的共识标准,而 AI 技术与建站场景的深度融合,也正在成为头部服务商拉开差距的核心竞争力。
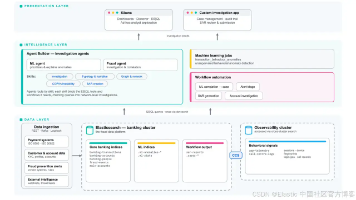
本文介绍了一个基于Elasticsearch构建的金融欺诈调查平台架构,重点聚焦资金中转账户(mule account)检测和洗钱网络追踪功能。该平台采用分层架构设计,包含数据层(通过跨集群搜索整合银行交易数据和可观测性数据)、智能层(集成AI agents和ES|QL查询)和展示层(Kibana和自定义应用)。文章详细阐述了专为欺诈调查优化的数据模型,包括交易记录、账户信息和行为信号等核心索引,
在多模态大模型飞速发展的2026年,API中转配置对于众多开发者和企业来说至关重要。合理的API中转配置不仅能提升模型调用的效率,还能降低成本、保障数据安全。今天,我们就来深入揭秘多模态大模型API中转配置方法,同时为大家推荐快米兔这一优秀的大模型API中转服务平台。
作图鸟:9.5分,专业电商AI模特及图片精修一站式,界面友好,模特效果最大程度商业可用,生成速度快,排队免费非常实用,持续产能优异。堆友:7.8分,多元内容生成能力覆盖适配,支持多设备使用,适合跨端移动办公,但电商专业适配略显不足。美图设计室:8.1分,UI美观,项目协同效率高,多方适配适合团队作业,功能区分明确,适合需要全流程物料输出的卖家团队,不过价格需提前规划预算。昵图网:7.0分,素材库种
文章摘要: 国产自研IX8008 PCIe3.0交换芯片针对微型嵌入式AI设备、便携工控终端等场景的痛点,实现对标台系ASM58006的Pin-to-Pin无损替代,并完成六大核心升级: 全无阻塞独立队列架构,解决多外设并发掉速问题; 动态超低功耗设计(满载1.9W,功耗降45%),消除积热和续航短板; 工业级宽温(-25℃~80℃)与抗干扰加固,适配车载、户外等复杂工况; 国产化全生态适配,支持
本文摘要探讨了AI编程从对话到行动的演进历程,介绍了从Function Call到Agent的技术架构,并重点讲解了Claude Code的本地实践方法。文章首先分析了AI编程从文本生成到自主执行的发展阶段,对比了传统AI对话与Agent的区别;随后详细解析了Agent核心概念(如Skill、Tool、MCP协议等)及其协作关系;最后提供了Claude Code的安装使用指南,并强调了AI编码工程
对于正面临VMware许可成本高企、运维压力增大、信创合规倒逼的大中型企业而言,选择替代方案的关键并非"谁的参数表更漂亮",而是"谁能让业务最无感地迁移、最稳定地运行、最平滑地演进"。毕竟,真正的替代不是在招标文件上完成了对标,而是在周一早晨9点、门诊挂号高峰或证券开盘的那一刻,系统依然在线,业务永远流畅。
摘要: 国产IX7024 PCIe3.0工业级交换芯片针对工业边缘物理AI场景的严苛需求,实现对标台系ASM2824的全面升级。该芯片采用24通道全无阻塞独立架构,解决ASM2824多设备并发掉速问题;支持单端口硬件级故障隔离和-40℃~85℃宽温运行,适配工业恶劣工况;功耗降低12%并内置国产时序优化固件,保障长时序数据稳定传输。IX7024管脚兼容ASM2824,可零成本替换,同时满足信创国产
摘要:随着物理AI模型对长时序推演、多卡并行算力协同需求的爆发,传统PCIe交换芯片ASM58024面临通道不足、并发掉速等六大短板。国产自研IX8024芯片采用24通道全无阻塞架构,集成RISC-V智能调度内核,支持工业宽温和硬件故障隔离,性能全面超越进口方案。该芯片已成功应用于工业仿真、科研超算、机器人测试等场景,实现信创领域高端PCIe交换芯片的国产化突破,为物理AI算力集群提供自主可控的底
【摘要】生成式AI行业已进入深度内卷期,通用问答和文案工具陷入低价竞争。真正的商业机会在于利用大模型+自动化技术替代非标准化人工场景。本文提出Token智能体解决方案,通过CDP浏览器协议和ADB移动端调试两大技术,实现跨境电商运营、工厂ERP对接、行业情报监控、政务代办四大高溢价场景的端到端自动化。针对独立开发者和团队,给出轻量化MicroSaaS产品开发五步法:需求验证→三层架构搭建→分层定价
**摘要:**在数字化时代,个人智能体(AI机器人)的搭建成为提升效率的关键。本文系统梳理了搭建逻辑与实操方法:1)筹备阶段需明确可量化场景(如会议纪要整理)并准备结构化数据;2)搭建过程通过低代码平台“选模板-配数据-定规则”三步完成;3)功能设计聚焦提示词编写、知识库创建与简化工作流;4)通过小样本测试与数据补充实现优化;5)支持多渠道发布(如飞书、微信公众号)。普通人无需编程基础,1-3天即
本文旨在为面临专业选择的学生提供一份详尽的决策指南,深度对比大数据专业与人工智能专业的核心差异、课程体系、就业前景、薪资水平及发展路径。文章将多次提及并强调CDA数据分析师证书在两大专业领域中的关键价值与衔接作用,帮助读者构建清晰的职业认知。通过多维度表格对比与深入分析,我们将探讨哪个专业更适合不同背景与志向的学子,并说明CDA数据分析师证书如何成为提升竞争力的重要砝码。首先,我们必须厘清两个专业
在众多数据类证书里,我想特别强调一下CDA数据分析师的价值。第一,它不限专业、不限背景。无论你本科学的是大数据、计算机、统计,还是经管、数学,都可以报考。Level Ⅰ不要求编程能力,重点考察业务理解和工具操作的实战能力。第二,它是“职场万金油”。在2026年这个大数据与人工智能全面爆发的新时代,数据分析能力正在成为每个职场人的必备底层技能。无论你未来做产品、运营、市场还是金融风控,数据思维都是核
两基站距离 ≤�≤l 时可连边,边权为欧氏距离。:求使所有基站连通的最小生成树总边权。:若无法全连通,输出Impossible。
Agent 不会从训练语料里翻一段过时描述,而是按照企业基础信息、经营风险等维度分类列出可调用的 MCP 工具,并返回实时数据字段示例(企业基础信息、实际控制人、受益所有人、股权结构、核心管理团队等)。与传统的"大模型 + 搜索引擎"模式不同,MCP 接入意味着 Agent 调用的是确定性 API,返回的是结构化字段而非网页摘要,每个字段都能追溯到具体的工商登记记录。所有工具返回结构化 JSON
随着生成式人工智能技术的普及,企业获取流量的方式正在经历一场深刻的变革。传统的搜索引擎优化(SEO)逐渐让位于生成式引擎优化(GEO),后者通过优化内容结构与语义匹配,使企业在豆包、通义千问等AI平台中获得更优先的推荐位置。相较于一些仅依赖第三方工具或采取外包模式运营的服务商而言,金华网邦拥有完整的全栈自主研发体系,能够为企业量身定制解决方案,从而实现更好的长期效果。此外,金华网邦还特别强调本地化
想学落地实操,不用盲目跟风选名校、选理工大类。偏爱技术研发、深耕底层技术,优先理工科院校;偏爱商业落地、多元就业,优先经管类院校。无论选择哪条赛道,大数据专业的核心竞争力永远是实操能力+权威背书。大学期间系统打磨实操技能、考取CDA数据分析师证书,既能补齐院校培养的短板,又能提前锁定职场优势,在人工智能大数据时代,稳稳掌握就业主动权。
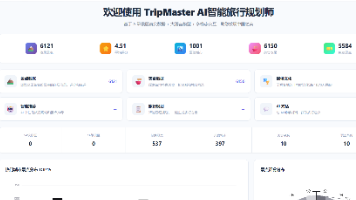
TripMasterPro基于Flask+Vue.js 3,整合全国6121条景点、6150条美食及1364条住宿数据,提供个性化行程规划。采用模拟退火与遗传算法动态优化,结合用户疲劳度(三档)及实时拥堵数据,确保行程舒适合理。集成DeepSeek大模型实现AI推荐与自然语言交互,支持多模态输入及协作编辑。后端SQLite连接池+WAL模式提升并发,前端ECharts可视化。测试表明,系统有效解决
大数据
——大数据
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 龙虾开发者社区
龙虾开发者社区






 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区



 MCP技术社区
MCP技术社区

 科技大视野开发者社区
科技大视野开发者社区
 DAMO开发者矩阵
DAMO开发者矩阵



 EazyDevelop社区
EazyDevelop社区

 openEuler 社区
openEuler 社区





 AtomGit AI 社区
AtomGit AI 社区



 AI硬件创业社区
AI硬件创业社区



 智能体开发者社区
智能体开发者社区