登录社区云,与社区用户共同成长
邀请您加入社区
在数据库物理层直接通过近似最近邻(ANN)和标量算术得出组合分数,然后只返回最终的 Top-K。
在打造企业级的高级 AI Agent 时,面试官往往会深入挖掘你对“记忆系统”的理解。很多初学者只知道“把聊天记录存进向量数据库”,但这在真实的复杂业务中是远远不够的。在人类的认知心理学(Cognitive Psychology)中,。目前顶级的 Agent 框架(如 Mem0、AutoGen 等)都已经引入了这种双轨记忆架构。这篇博客将用大白话带你搞懂这两种记忆的底层逻辑、工程落地差异,并附带能
云原生:应用生来就是为云设计的核心:容器化 + 微服务 + 自动化目标:快速交付、弹性伸缩、高可用云原生不是"把应用搬到云上",而是"让应用按照云的方式设计"。下篇文章,我们聊聊Serverless:无服务器计算的革命。
本文介绍了机器人开发中常用的三种文件格式(CSV、JSON、YAML)的Python处理方法。针对CSV文件,推荐使用csv模块的DictReader处理大数据;JSON格式建议使用json模块并注意中文编码;YAML文件需使用PyYAML库的safe_load避免安全问题。文章还比较了os.path和pathlib两种路径处理方法,推荐使用更现代的pathlib。最后提供了大文件处理技巧和正则表
本文深入探讨了Python中四种核心数据结构(list、dict、tuple、set)的选择策略及其应用场景。文章通过面试案例说明错误选择数据结构会导致性能问题,并详细分析了各数据结构的特性:list适合顺序存储和索引访问,dict用于快速键值查找,tuple适用于不可变数据,set擅长去重和集合运算。文中特别强调了在机器人开发中的实际应用场景,如用deque处理滑动窗口数据,用dict管理传感器
本文系统阐述了现代机器人开发中C++与Python的分工协作。文章指出,C++适合性能敏感模块(传感器驱动、实时控制等),Python则擅长快速开发(数据分析、测试脚本、深度学习等)。通过实际案例展示了pybind11实现跨语言调用的方法,并分析了Python在GIL限制下的解决方案。作者强调,面试中应展示对不同工具适用场景的理解,建议开发者掌握conda环境管理和Docker部署等工程实践。最后
本文主要探讨机器人开发中的性能优化策略。作者通过一个视觉伺服系统的案例,强调性能优化的核心原则:基于profiling数据而非猜测进行优化。介绍了Linux下的perf和FlameGraph等性能分析工具,并详细列举了从算法、数据结构到编译器优化的多层次优化手段(包括算法复杂度改进、缓存友好性处理、SIMD指令使用等)。文章特别指出,优化后必须进行量化对比验证,并提供了Google Benchma
上篇聊了CMake,把项目的编译构建搞明白了。今天说编译之后的事——调试。先讲个面试场景。面试官问:"你的机器人程序跑着跑着突然segfault了,你怎么排查?我当时脱口而出:"加printf看哪里挂了。面试官没说话,就看着我。我接着补充:"也可以用日志……"场面一度很尴尬。后来才知道,面试官想听的不是这个。他想听的是系统性的排查思路——core dump分析、GDB定位崩溃点、ASAN检测内存问
通俗概念长期记忆是 Agent 用来存储海量、非结构化历史信息的仓库。当你告诉 Agent “我叫张三,我对海鲜过敏”时,Agent 不会把这句话永远放在每次聊天的 Prompt 里(那太贵了),而是把它翻译成一串数字(向量),存进它的大脑深处(向量数据库)。过了几个月,当你问它“今晚去吃海鲜大排档怎么样?”时,Agent 会瞬间在茫茫记忆海中,把“张三对海鲜过敏”这条记忆捞出来,并拒绝你的提议。
文章摘要: AI Agent 长期对话面临记忆管理的核心挑战:全量记忆成本过高,滑动窗口又会导致关键信息丢失。本文解析了会话摘要与压缩(Memory Compression)这一折中方案,通过将长对话提炼为精华摘要来平衡成本与记忆保留。重点介绍两种主流压缩机制:1)滚动摘要(Rolling Summary)实时提炼对话核心;2)实体抽取(Entity Extraction)结构化存储关键信息。文章
论文全名叫AI编程助手会编造不存在的包名和仓库名(这就是大模型的"幻觉")同一个问题反复问,AI编出来的假名字惊人地一致——58% 的概率编出同一个名字攻击者提前注册这些假名字,埋入恶意代码和 Prompt 注入——坐等开发者通过AI上钩你可能听过(域名/包名抢注),攻击者注册和知名包相似的名字,比如loadash冒充lodash。它不需要猜你会打错什么字,它直接预测AI会编什么名字。而且预测准确
【150字摘要】应届生求职常因简历信息差受阻,海投无果。推荐专业求职工具网站zhichacha.codexaiplus.com,提供各行业真实上岸简历范文(含零经验案例),帮助快速掌握岗位关键词与HR偏好的话术逻辑。支持保密一对一服务,2小时速出优化方案,无效不收费。解决简历石沉大海难题,缩短求职摸索期,登录即可免费评估,高效备战校招季。
十五五规划(2026-2030年)为网络安全行业指明六大核心发展机遇: 数据安全:围绕数据要素市场化,重点布局分类分级、隐私计算、跨境流动等方向; AI安全:应对大模型泄露、生成内容风险等新挑战,发展全生命周期治理技术; 算力安全:伴随全国算力网络建设,云原生、边缘计算等新型基础设施安全需求激增; 关基保护:能源、交通等关键行业数字化升级将推动工控安全、工业互联网安全发展; 政务安全:数字政府建设
文章摘要: "十五五"规划(2026-2030年)为网络安全行业指明六大核心发展赛道:1)数据安全(要素市场化催生分类分级、隐私计算等需求);2)AI安全(大模型防护、内容检测等新挑战);3)算力基建安全(云原生、边缘计算防护);4)关键基础设施安全(能源/交通等工控安全);5)数字政府安全(政务云、城市SOC建设);6)供应链安全(开源治理、信创适配)。规划显示网络安全正从合规驱动转向与数字经济
摘要:银河通用机器人招聘人形强化学习算法工程师(面向2026届毕业生)。岗位职责包括研发足式机器人运动控制算法、步态规划、实时控制及路径导航算法,并在仿真平台测试优化。要求硕士及以上学历,机器人学/人工智能相关专业,熟悉强化学习算法、C++/Python编程及运动控制算法,具备足式机器人项目经验。需扎实的数学基础、团队协作能力和动手实践能力。有相关论文发表或复杂地形运动控制经验者优先。工作地点北京
本文作者分享了自己过度依赖AI编程助手的反思。在试用多个AI插件后,作者发现AI虽然提高效率,但也带来了思考能力退化、代码质量下降和知识空心化等问题。通过具体案例,作者指出AI生成的代码可能隐藏深层缺陷,且会削弱程序员解决问题的能力。作者提出"三用三不用"原则:用AI做脚手架、代码审查和知识查询,但核心逻辑、代码生成和问题解决仍需亲力亲为。最后推荐了注重验证和思维分析的AiPy
核心答案:KV Cache 与 Prompt Caching 是同一套缓存机制在两个时间尺度上的延伸——前者是"单次推理内"的优化,后者是"跨请求"的优化。自回归生成每步都要对所有历史 token 算 attention,若每次从零重算,N 个 token 总复杂度约 O(N³) 不可接受;KV Cache 把前面所有 token 的 K、V 矩阵缓存在显存,每步新 token 只算自己的 Q/K
本文介绍了机器人开发中常用的坐标变换工具——四元数和变换矩阵。四元数用4个数字描述三维旋转,比旋转矩阵更紧凑且无万向锁问题;变换矩阵则统一表示旋转和平移。文章通过代码示例展示了Eigen库中四元数、旋转矩阵和变换矩阵的相互转换及实际应用场景(如激光雷达坐标转换、IMU积分等),并总结了面试常见考点,包括四元数与旋转矩阵转换原理、SLAM优化选择四元数的原因等,建议读者通过实践加深理解这些机器人开发
PO(PageObject)设计模式将某个页面的所有元素对象定位和对元素对象的操作封装成一个 Page 类,并以页面为单位来写测试用例,实现页面对象和测试用例的分离。数据驱动测试(DDT)是一种方法,其中在数据源的帮助下重复执行相同顺序的测试步骤,以便在验证步骤进行时驱动那些步骤的输入值和/或期望值。无论是 PO 设计模式还是数据驱动测试,其实都是目前测试工程师在编写自动化测试框架中的常用技巧与设
今天是技术面。Alex 翻了翻简历,在"AI Agent 开发"那一行停了一下。
把原来只有少数人能做的事,变成多数人都能做的事。电脑让打字从专业打字员的技能,变成人人都会的操作。互联网让信息检索从图书管理员的专业,变成搜索引擎的一键搜索。智能手机让拍照、导航、支付从专业设备的功能,变成口袋里随时可用的能力。AI正在让“创造内容”“分析数据”“编写代码”从少数专业人士的专利,变成人人可用的工具。历史的韵脚告诉我们:每一次技术浪潮,最终都走向了能力的下放与普及。AI不是例外。当A
DeepSeek在脉脉上招聘岗位涵盖大模型算法研究员(50万-150万年薪)、AI基础设施工程师等,普遍要求硕士以上学历及专项技术能力。高薪背后反映三大趋势:1)供需失衡,顶尖AI人才稀缺;2)人才直接影响商业价值;3)创业公司以高薪争夺核心团队。岗位分化显示行业新需求,如Agent开发、推理优化等新兴职位涌现。未来竞争力将取决于AI能力与产业结合的深度,而非单纯编码能力。当前5500元/日的实习
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选很简单,这些岗位缺人且高薪智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。AI产业的快速扩张,也让人才供需矛盾愈发突出。
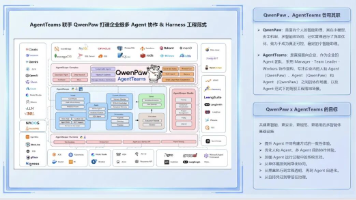
摘要: 阿里云AgentTeams(原HiClaw)定位为企业级多智能体协作统一底座,提供QwenPaw(轻量单Agent)与OpenClaw(多Agent协同)双引擎,支持三层架构(Manager-Team Leader-Worker)的复杂任务调度。核心能力包括多Agent纳管、零信任安全、全链路可观测及MCP网关(无缝集成存量微服务)。覆盖SRE运维、B2B2C SaaS、C端消费等场景,通
这篇文章总结了AI Agent开发的10个核心概念,强调明确Agent职责范围比写代码更重要。Agent就像厨师,模型是大脑,工具是厨具,知识库是食材。核心概念包括Agent、模型、指令、记忆、工具、知识库、MCP协议、Skill技能、编排流程和可观测性。文章指出40%的Agent项目会在3年内失败,建议开发者先明确Agent要解决的问题,再动手编码。最后提供了AI大模型学习资料包,包含教程、路线
本文聚焦AI应用开发中工具调用的工程实践,重点解析三大核心问题: LLM网关的核心价值:区别于传统API网关,LLM网关专为解决多模型统一接入、密钥集中管理、token配额控制、语义缓存等大模型特有需求,实现成本管控与安全治理。 Function Calling机制:详解"模型决策-代码执行"的运行时流程,强调模型仅输出结构化调用指令,实际执行由宿主程序完成,并说明schema设计、参数校验等工程
本文是AI Agent面试专题第二章,聚焦多智能体协作与记忆机制。核心内容包括: Multi-Agent设计:通过多个专业化Agent分工协作解决单体Agent的Context窗口限制和能力过载问题,强调"能单不双"的选型原则。 多智能体拓扑:对比中心化编排(生产首选,可控性强)与去中心化P2P(学术探索为主)的优劣,指出Orchestrator的"项目经理"角色价值。 协作机制:分析消息传递与共
第一,证书和岗位不匹配。面试官真正关心的不是“你考了多少”,而是“你准备解决什么问题”。一份简历列了8项证书——英语四六级、计算机二级、教师资格证、营养师证——面试产品经理岗位,面试官问“这些和岗位有什么关系”,候选人答不上来,初试都没过。第二,不同证书对应不同能力路径。项目管理、人工智能应用、AI产品和云计算分别对应不同的职业方向,几张证书看似覆盖全面,实际却让简历失去重点。证书之间没有形成能力
职场和发展
——职场和发展
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 智能体开发者社区
智能体开发者社区



 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 DAMO开发者矩阵
DAMO开发者矩阵








 AI编程社区
AI编程社区






 深开鸿 技术专区
深开鸿 技术专区




 AtomGit AI 社区
AtomGit AI 社区


 DeepSeek技术社区
DeepSeek技术社区