登录社区云,与社区用户共同成长
邀请您加入社区
本研究基于LSTM深度学习模型构建了新型病毒传播风险预测系统。通过优化网络结构和超参数,整合公共卫生数据(包括确诊、死亡、康复等指标),采用数据预处理和交叉验证技术,模型展现出优异的时序预测性能。研究验证了LSTM在捕捉病毒传播动态模式方面的优势,其预测结果可为疫情防控决策提供支持。系统还包含用户管理、数据可视化等功能模块,具备良好的实用性和扩展性。尽管对突发事件的敏感性有待提升,但该研究为公共卫
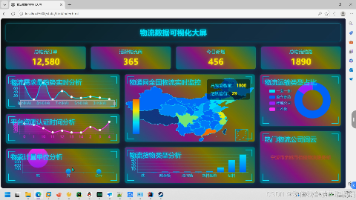
摘要:本文系统研究了基于Hadoop+Spark+Hive的物流货运量预测系统。通过分析国内外研究现状,指出传统物流预测方法存在数据治理混乱、特征挖掘不足等问题。研究提出整合Hadoop分布式存储、Hive分层数据治理和Spark机器学习建模的技术方案,构建从数据采集到可视化展示的全流程预测系统。重点探讨了大数据生态技术在物流时序预测中的应用优势,包括海量数据处理能力、分布式建模效率和预测精度提升
本文设计并实现了一种基于深度学习的电力数据预测系统,采用LSTM模型处理非线性的电力负荷数据,通过数据预处理和参数优化显著提高了预测精度。系统集成了电力信息管理模块,支持数据录入、查询、修改和可视化功能,为电力企业提供决策支持。实验证明该系统能有效预测负荷趋势,优化电力调度,降低运营成本。系统功能模块图清晰展示了数据分析、处理、可视化及管理的完整架构,具有重要的实用价值和推广前景。
摘要:本研究设计并实现了一个基于大数据的年轻女性服装个性化推荐系统。系统通过爬取淘宝服装数据,利用Hadoop、Spark等技术进行存储分析,构建用户画像和推荐模型,采用协同过滤和深度学习算法实现精准匹配。系统包含数据采集、处理、分析和后台管理四大模块,提供销量统计、价格分布等可视化分析功能,为商家决策提供支持。前端使用Vue.js+Echarts实现交互式数据展示,后端采用Django框架,显著
本文提出基于大数据的房价预测系统,整合多源异构数据,采用Hadoop和Spark技术处理数据,运用机器学习算法构建预测模型。系统通过B/S架构实现数据采集、存储、分析和可视化功能,实验验证其预测准确性和实用性。研究表明,该系统为房地产市场参与者提供了可靠的决策支持,促进了行业健康发展。
本研究开发了一种基于机器学习的智能交通流量预测系统,通过整合北京多源交通数据(道路监控、交通卡口等),利用大数据处理和机器学习算法实现实时分析与短期精准预测。系统采用数据挖掘和模式识别技术,揭示交通流量的时空特征,并配备数据可视化功能(热力图、折线图等)和友好交互界面。实验证明该系统能有效提升交通管理效率、缓解拥堵,具有实用性和可扩展性,可为智慧城市建设提供决策支持,应用前景广阔。系统架构包含数据
7月30日,记者获悉,腾讯云正式发布智能数据湖计算平台AI DLC,面向自动驾驶、具身智能、Agent等AI场景,提供覆盖数据处理、训练、推理到 Agent 应用的一体化能力。在自动驾驶场景中,博世测试车辆每天产生大量视频和传感器数据,抽帧和清洗主要消耗 CPU,数据脱敏,模型训练与推理则依赖 GPU。两套框架共享数据、算力和权限体系,数据处理完成后即可直接进入训练和推理,无需跨平台搬运。接入 A
脚本自动收集服务器型号、BIOS版本、操作系统、内核等基础信息,盘点CPU核心、NUMA架构、内存分布等硬件资源,检查Swap、透明大页、磁盘调度、防火墙、SELinux等关键配置,并根据服务器总算力动态计算最优参数,自动完成实例配置调优,大幅降低部署门槛与运维成本。此外,新版本内置智能路由机制,当向量化引擎遇到不支持的功能时,可自动回退至express引擎,确保业务稳定运行不中断,为用户提供可靠
摘要:本文设计并实现了一个基于深度学习的京东男士冬季外衣推荐系统。系统采用Python+Django开发框架,通过爬虫技术采集京东平台的商品数据,利用Hadoop和Spark进行大数据存储与分析。系统功能包括用户管理、服装信息管理、价格预测、订单管理和可视化数据分析看板(集成店铺排名、价格趋势、评论统计等Echarts图表)。测试表明,该系统能有效解决信息过载问题,通过个性化推荐提升用户购物体验,
随着信息技术的迅猛发展,教育领域正经历着前所未有的变革。个性化学习、智能推荐等概念逐渐成为教育创新的重要方向。在这种背景下,基于Spark的初中生个性化学习推荐系统应运而生。传统的课程选择方式往往依赖于学生的主观判断或用户的统一安排,缺乏针对性和个性化。 本研究旨在构建一个基于Spark的初中生个性化学习推荐系统,通过分析学生的在线学习行为、课程选择历史、参与人数等数据,运用数据挖掘和机器学习技术
Nvidia在Computex 2026发布革命性PC芯片RTX Spark,首次以完整SoC形态进军消费级处理器市场。这款Arm架构超级芯片整合Grace CPU与Blackwell GPU,采用统一内存设计(最高128GB),可本地运行1200亿参数大模型。联发科参与CPU设计,Adobe等软件厂商已深度优化,华硕等OEM厂商将推出搭载设备,预计2026年秋季上市。黄仁勋同时公布三代产品路线图
本文设计并实现了一个基于深度学习的男士冬季外衣推荐系统,针对京东电商平台的海量商品数据,采用Python+Django技术栈开发。系统通过爬虫采集数据,运用Hadoop、Spark等大数据技术处理分析,实现个性化推荐功能。主要包含数据抓取、预处理、可视化及管理四大模块,支持用户管理、商品管理、价格预测、订单管理等功能。创新性地构建了多维数据看板,通过Echarts展示店铺排名、价格趋势、用户评价等
本文设计了一个基于Spark的中外游客景点数据分析系统,该系统采用模块化架构,包含数据采集、处理、分析和后台管理四大功能模块。通过Spark框架高效处理景点名称、城市、评论数等多元数据,并应用机器学习算法进行热度预测。系统运用Pandas进行数据清洗(包括缺失值处理、格式统一等),确保数据质量,最终实现旅游信息的自动化管理与智能分析,为游客提供个性化服务,为行业决策提供数据支持。未来将拓展实时处理
本研究设计了一个基于Python的交通运输统计数据分析系统,采用模块化架构实现数据采集、预处理、分析、可视化及报告生成功能。系统利用Python强大的数据处理能力和第三方库支持大规模交通数据分析,集成机器学习算法进行速度预测评估,为决策提供支持。实际应用表明系统性能稳定,操作界面友好,显著提升了交通数据处理效率和分析精度。未来可扩展实时大数据处理和深度学习功能,推动智慧交通发展。系统通过Pytho
本研究设计了一个基于推荐系统的新闻阅读平台,整合爬虫、大数据和Spark技术实现新闻分类、个性化推荐及实时更新。平台包含首页导航、新闻资讯(网易/今日新闻)和个人中心等功能模块,通过数据可视化提升用户体验。系统采用API实时抓取数据,确保新闻时效性,并运用推荐算法优化内容匹配。未来计划引入多模态融合和跨语言推荐等新技术,持续完善平台功能。该研究为新闻传播创新提供了技术解决方案,具有良好应用前景。
**摘要:**房价数据分析系统整合多源房地产数据,通过数据收集、预处理、分析(时间序列、回归分析、机器学习等)及可视化功能,提供实时房价趋势与预测。系统支持自定义查询,帮助开发商、投资者及购房者洞察市场动态,辅助决策。功能模块包括数据处理、深度分析及结果展示,界面直观呈现走势图、区域对比等关键指标,提升房地产市场的分析与决策效率。
本文研究基于随机森林算法的心血管疾病预测系统,针对老年人群健康监测需求,结合大数据技术构建预测模型。系统采用Spark、Hadoop处理海量高维数据,通过Django+Vue框架实现数据可视化和预测功能,包含数据采集、预处理、特征选择和模型训练等模块。实验证明该系统能有效分析血压等健康指标,生成可视化报告,为心血管疾病预防提供决策支持,具有临床应用价值。
本文介绍了一个基于大数据技术的社交媒体内容情感极性分类系统,该系统通过机器学习(Hadoop、Spark等)实现高效数据处理,具备情感分析、趋势识别、舆情监控等功能。系统采用Vue+Django架构,包含数据爬取、存储(MySQL)、可视化展示模块,可分析评论内容、点赞量等数据,帮助用户洞察舆论动态并优化决策。该系统为企业和组织提供了社交媒体数据分析的完整解决方案。
摘要:起点小说数据分析系统通过月票数据可视化,以柱状图展示各类小说的受欢迎程度。X轴为小说类型(都市、仙侠、玄幻等),Y轴为月票数量。系统从数据库提取数据后,经清洗聚合处理生成直观图表,帮助用户快速识别当前市场热门小说类型。该分析为读者提供阅读参考,为作者创作和市场策略提供数据支持。
本文概述文章目标、核心观点和实践价值。> 摘要:这两年面试数据分析转大模型的候选人,最常遇到的问题不是技术不会,而是项目讲不清楚。本文从面试官的视角,拆解如何把“从报表到智能分析Agent”的转型故事讲得既有技术深度,又能突出业务价值,附带完整的代码案例和实战建议。---回到主题:数据分析转大模型,新人上手的关键步骤不在于学会多少新技术,而在于**把你的项目讲成一个有逻辑、有取舍、有验证的故事**
通过这些功能模块的协同工作,系统实现了高效、准确的血细胞检测与计数,为医学实验室和临床应用提供了强有力的支持。此外,还引入了数据增强技术,如随机旋转、缩放和裁剪等,以增强模型的鲁棒性。基于深度学习的血细胞智能检测与计数系统,通过先进的图像识别和深度学习算法,实现了对血细胞图像的自动分析和计数。从图中可以看出,随着时间的推移,红细胞和白细胞的平均大小都保持相对稳定,没有出现明显的波动。这个模块通过一
对于机器学习从业者而言,技能跃迁的本质,是用系统性学习倒逼自己补齐“数据仓库”与“算法工程”之间的断层——这正是自学者最易忽视的盲区。与其在碎片化的网课与调参练习中消耗时间,不如沿着结构化的进阶路径,将精力聚焦于分布式工程、深度学习建模与跨领域实战这三块真正的能力高地。你的“段位”目前到哪一级了?在分布式工程、算法落地、跨领域建模这三个维度中,你最想突破的是哪一个?欢迎在评论区聊聊你的经历和困惑。
本文提出了一种基于Python和大数据的宠物用品推荐系统,旨在应对宠物经济快速发展带来的市场需求变化。系统整合了数据采集、存储、分析和可视化功能,运用机器学习算法预测付款人数,为营销和库存管理提供决策支持。系统包含三大核心模块:员工管理模块负责人员信息维护,宠物用品管理模块处理产品分类和促销活动,购买订单管理模块则专注于订单处理和支付流程。该解决方案通过智能化手段实现了销售全流程的数字化管理,有效
本文探讨了如何利用大数据技术栈(Spark+Hive)构建大模型时代的高效向量数据管道。文章提出了一种从Hive数仓到向量数据库的完整技术路径,包括数据清洗、文本预处理和Embedding生成等关键环节。核心思路是将大数据工程师的ETL能力迁移到大模型知识库构建场景,重点解决了海量文本数据的高效向量化问题。文中提供了两种分布式生成Embedding的方案,并详细讲解了文本清洗策略和Spark优化配
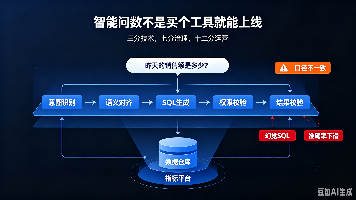
《智能问数落地指南:从技术路线到企业实践》 摘要:智能问数技术虽发展六年,但实际落地效果两极分化。文章系统梳理四代技术演进(规则模板、深度学习NL2SQL、大模型+语义层、Agent化协同),指出当前主流方案是统一语义层+指标平台路线。企业落地需遵循"三步走":需求诊断(聚焦高频场景)、POC验证(业务准确率≥85%)、规模化运营(持续迭代)。关键避坑建议包括:优先单场景做透、
Mac Studio M3 Ultra明显占优。它拥有四倍内存容量和三倍理论内存带宽,特别适合单机加载超大模型、处理大型媒体工程和承担综合性专业工作。DGX Spark仍然有自己的护城河。CUDA、TensorRT-LLM、vLLM、NGC和NVIDIA服务器生态,使它更适合真正围绕NVIDIA平台进行模型开发、微调、验证和部署。Mac Studio是一座容量巨大、传送带很宽的全能仓库;DGX S
注册用户功能模块:前台首页:注册用户注册登录系统后,可以在首页查看并使用轮播图、音乐资讯、音乐推荐快捷导航按钮。音乐资讯:用户能够通过搜索、筛选和排序的方式查找相关的音乐资讯,然后点击查看详情,并可进行点赞、收藏和评论。通知公告:用户可以查看管理员发布的所有公告通知,并可对其进行收藏和评论。音乐推荐:用户可以查看音乐推荐列表,用户可以通过搜索、筛选和排序功能查找感兴趣的推荐内容,点击查看详情,并进
spark
——spark
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区




 DAMO开发者矩阵
DAMO开发者矩阵
 openEuler 社区
openEuler 社区


 AI编程社区
AI编程社区


 AI Agent技术社区
AI Agent技术社区
 智能体开发者社区
智能体开发者社区