登录社区云,与社区用户共同成长
邀请您加入社区
摘要:本文提出一种基于九章编程法的矩阵化操作系统框架,将传统指令流范式重构为三层确定性状态机模型。功能矩阵对内核服务进行四色分类(刚体、流态、转换层、接口层),演化框架将状态外置为池塘、操作为无状态机床、流程声明为物流计划表,控制框架通过中断等级映射驱动计划表执行。该架构在1200行C代码中实现核心功能,形式化证明其确定性、无副作用隔离和可验证性,从根本上解决传统内核状态弥散、控制流复杂和代码膨胀
ChatGPT充值后,开发者使用Codex开发时易忽视边界条件,导致代码在真实场景中不稳定(如空数据报错、并发异常等)。解决方案是建立测试矩阵,覆盖正常、异常、边界和兼容场景,分四层测试(正常流程、边界输入、异常环境、兼容回归)。建议先让Codex生成测试矩阵再编码,将测试规则写入AGENTS.md,并区分高低风险模块优先级。对于轻量任务,Plus版本足够;高频多模块开发需评估Pro版本。核心在于
DeepSeek模型家族提供了从轻量级1.5B到全能型671B的完整产品线,满足不同场景需求。部署前需了解知识蒸馏、量化、裁剪等核心技术概念,以选择合适的模型版本。资源获取方式包括本地部署(高隐私)、云端部署(弹性算力)和API调用(快速验证),各有优劣。硬件需求方面,14B及以下模型适合个人用户,32B及以上需专业设备。通过API调用可直观对比不同模型的推理效果。建议开发者根据应用场景选择合适方
本文介绍了一种基于HarmonyOS的AI药品说明书翻译应用,针对传统人工翻译存在的效率低、术语不准确等痛点,提出完整的开发解决方案。文章系统阐述了从需求对齐、架构设计到评估的六个开发阶段,重点分析了药品说明书翻译场景的特殊需求,包括专业术语处理、剂量单位转换和安全警示等核心问题。技术实现上采用HarmonyOS ArkTS框架和MVVM架构,通过State驱动数据流实现响应式UI,并设计了独特的
本文介绍了四旋翼飞行器姿态控制中的坐标系定义与姿态表示方法。主要内容包括:导航坐标系(NED)与机体坐标系的定义及其转换关系;欧拉角表示法及其万向节锁问题;旋转矩阵的构建与应用;四元数的定义及其在姿态解算中的优势。文章还讨论了如何通过互补滤波融合传感器数据,解决陀螺仪积分漂移问题,实现高精度姿态解算。这些方法为飞行器的稳定控制提供了理论基础,其中四元数因其计算高效、无奇异性等特点成为现代飞控系统的
本文介绍了基于HarmonyOS ArkTS技术栈开发"AI猫咪行为解读"应用的全流程。采用六阶段方法论(对齐→架构→原子化→审批→自动化→评估),重点阐述了需求分析、架构设计和实现方案。应用采用MVVM架构,分为Model层(定义数据结构)、Service层(封装业务逻辑)和View层(UI展示)。通过ArkTS严格类型约束和模块化设计,实现了用户输入猫咪行为描述后,系统输出行为解读、情绪判断、
这个实现能够高效地处理题目要求,利用了 Go 的 container/heap 包和排序功能。· 时间复杂度:O(mn log(mn) + k log k)· 每个单元格入堆一次:O(mn log(mn))// 扩展所有值小于当前查询的单元格。1. 最小堆:存储 (值, 行, 列),按网格值排序。3. BFS扩展:只扩展值小于当前查询的单元格。· 查询排序:O(k log k)4. 访问标记:每个
文章摘要 本教程系统讲解NumPy矩阵乘法的核心知识,包含3种实现方式(np.dot()、@运算符、np.matmul())和维度匹配规则((m,n)×(n,p)=(m,p))。重点解析矩阵乘法的数学特性:不满足交换律但满足结合律,以及单位矩阵的特殊性质。特别演示了转置操作(.T)在解决维度不匹配问题中的实际应用,并通过向量旋转和线性方程组等案例展示矩阵乘法的典型应用场景。教程还包含手动计算验证、
知识蒸馏是一种通过大模型(Teacher)指导小模型(Student)训练的技术。其核心思想是利用Teacher输出的"软标签"(包含类间关系等丰富信息)而非硬标签来训练Student。蒸馏损失函数结合KL散度(软标签)和交叉熵(硬标签),通过温度参数T控制软标签平滑度:T值越大,分布越平滑。实验表明T=3-5适用于多数场景。昇腾平台实现中,Teacher模型冻结,Student通过优化总损失(α
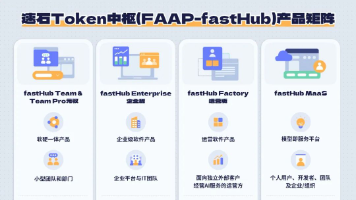
面向外部客户的开户、套餐、定价、计量和运营能力此前已经存在。fastHub Factory运营版这时需要处理客户开户、套餐、价格、额度、计量、结算和持续运营,还要把不同来源的模型包装成客户能够购买和调用的服务。用户可以继续使用已经采购的公有模型、其他MaaS、私有模型和自建推理服务,再根据团队共享、组织治理或对外经营的需要,接入相应的速石Token中枢产品。两者解决的问题不同。TA通过管理面沉淀视
今天这篇文章,我们只做一件事:搞懂**「线性代数在大模型中扮演什么角色」
电商榜单数据采集是电商数据分析、运营复盘、竞品调研的基础工作,手动采集效率低下,专业爬虫脚本门槛过高,并不适合普通从业者。火车采集器凭借零代码可视化操作、高适配电商动态页面、稳定批量采集、自带数据清洗的特性,完美适配中小开发者、运营人员的日常采集需求。无需复杂技术储备,十分钟即可完成全套榜单采集流程,大幅提升数据获取效率,让电商数据分析工作更高效、更轻量化。
摘要: 东莞制造企业在选择GEO服务商时,技术架构差异显著影响AI搜索排名效果。主流架构分为三类: 通用Embedding+人工关键词锚定:长尾词匹配差,31%查询无结果,语义偏移严重; 大模型API实时生成:延迟高、成本不可控,可见度仅为向量检索的23%; 乘风GEO的行业微调Embedding架构:通过预计算向量+重排序,长尾词Top3命中率达78%,零结果率仅8%。 制造业73%搜索流量来自
镜像视界自研时空矩阵演算模型,国产化架构融合全域多模态感知数据。
此外,推出天琴车载语音助手和海外版天琴语音助手Orphi,支持40余种语言的全链路语音交互,覆盖东南亚、欧洲、拉美、中东、俄罗斯等重点市场,目前,累计“上车”超2500万辆,合作客户涵盖梅赛德斯-奔驰、奥迪、捷豹路虎、比亚迪等全球60多家知名汽车品牌。在智慧物联领域,思必驰已与美的、海信、海尔、智元机器人、银河通用、魔法原子、科沃斯、追觅、小米、联想、OPPO等头部客户合作,覆盖黑白电、厨卫、中控
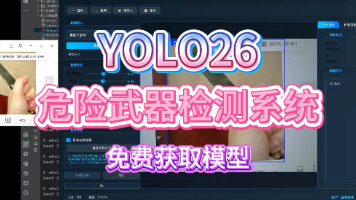
针对公共安全领域中危险武器(如刀具)的实时检测需求,本文基于YOLO26目标检测算法构建了一套高精度、高速度的刀具识别系统。系统采用单类别检测头(nc:1),在包含 6675 张训练图像与 2514 张验证图像的自建数据集上进行训练。实验结果表明,模型在验证集上取得了 95.7% 的 mAP50 和 70.7% 的 mAP50-95,精确率达 95.3%,召回率达 92.1%。在 NVIDIA G
本文基于YOLO26目标检测算法构建了一套蜜蜂识别检测系统,用于自动识别图像中的蜜蜂目标。数据集共包含8,080张标注图像(训练集5,640张、验证集1,604张、测试集836张),类别仅为bees。实验结果表明,模型在验证集上的mAP50达到0.91,最佳F1值为0.85,精确率最高可达1.00,召回率接近1.00。然而,模型存在一定的假阳性问题(背景误检为蜜蜂)以及定位精度不足的现象,并表现出
本项目旨在从零搭建一个基于 GPT-2 Medium 衍生架构的 LLaVA 多模态大模型,使其至少支持文本、图像两种模态输入,同时尽可能减少对Pytorch封装库的直接调用,在此中熟练掌握基础的知识、模型的预训练微调等等处理技术和对多模态技术的了解。
《AI搜索时代的企业获客革命:智搜GEO开辟流量新蓝海》摘要: 在AI大模型成为用户首要咨询入口的背景下,江苏好客搜推出的智搜GEO系统开创了生成式引擎优化新赛道。区别于传统SEO的链接跳转模式,智搜GEO直接将企业信息嵌入AI原生回答,实现"提问即推荐"的精准转化。该系统搭载三大自研引擎:96.7%准确率的语义理解引擎、符合E-E-A-T标准的内容工厂、全域实时监测引擎,形成
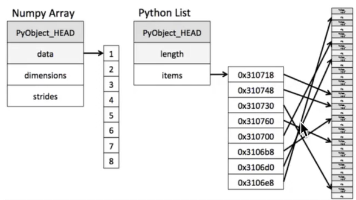
本文系统介绍了Numpy和Pandas两个Python科学计算核心库。Numpy部分重点讲解了ndarray数组的特性及优势(内存连续、并行运算、高效C实现),详细说明了数组生成、索引切片、形状修改、逻辑运算和统计运算等核心操作,并介绍了矩阵运算规则。Pandas部分以DataFrame为核心,阐述了其数据结构特点、索引设置方法、基本数据操作技巧,以及文件读取功能。两个库相互配合,Numpy提供高
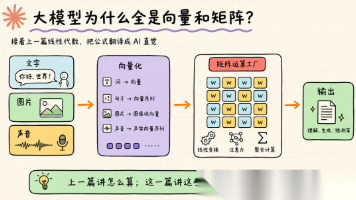
深度学习为什么依赖矩阵计算?核心在于向量化与 Batch 并行处理 深度学习模型通过矩阵运算(如 Z=WX+b)同时处理大量样本(Batch)和神经元,避免低效的显式循环。例如,W(3×4) 与 X(4×5) 相乘得到 Z(3×5),每列对应一个样本输出。向量化利用高效库和 GPU 并行计算,显著提升速度。关键概念包括: 向量/矩阵/张量:一维/二维/高维数组 Batch:并排计算多个样本(如 X
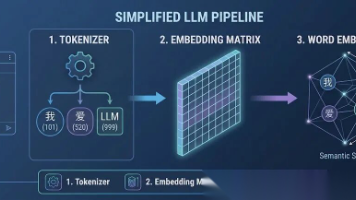
当你向大模型提问时,文字经历了一场精密的变身:切碎、编号、翻译成向量、注入位置信息,才被模型真正"看见"。本文拆解这条从文本到语义的完整链路。
分。Abstract本项目旨在从零搭建一个基于 GPT-2 Medium 衍生架构的 LLaVA 多模态大模型,使其至少支持文本、图像两种模态输入,同时尽可能减少对 Pytorch 封装库的直接调用,在此中熟练掌握基础 Transformer 的知识、模型的预训练微调等等处理技术和对多模态技术的了解。
本文介绍了基于HarmonyOS平台开发的"AI旅行规划师"应用的技术实践全流程。该应用通过AI技术解决传统旅行规划存在的信息碎片化、个性化不足等问题,提供从行程安排到应急信息的全链路规划服务。文章详细阐述了对齐阶段的需求分析、架构设计的三层模型(Model-Service-Page)、ArkTS语言特性运用、声明式UI开发实践以及状态管理方案,展示了如何在HarmonyOS生态中构建高效AI应用
层级分布:初级工程师 ~30题 / 架构专家 ~45题 / CTO管理层 ~25题。
如果说前面是泼冷水,Karpathy的结尾,又给台下点了一把火。
这是《大模型量化从0到1》系列的第 2 篇。上一篇我们建立了"三角权衡"的直觉,知道了量化能省显存、代价是精度。但要真正理解 GPTQ、AWQ、GGUF 为什么效果不同,你必须先看懂。这一篇我们不放过任何一个公式,从最基础的映射一路手撕到 per-group 量化,每个公式都配可运行的 NumPy/PyTorch 代码,让你亲眼看到每一个数字是怎么算出来的。看完这篇,后面所有格式的原理你都能秒懂。
erate bitsandbytes ### 5.2 加载原始 FP16 模型 ```python from transformers import AutoModelForCausalLM model_name = "facebook/opt-6.7b" # 6.7B 参数 model_fp16 = AutoModelForCausalLM.from_pretrained(model_name,
如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学AI大模型,就是冲刺高薪的最优解!零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风口的程序
#!/usr/bin/env python3 # -*- coding: utf-8 -*- """ ╔══════════════════════════════════════════════════════════════════════════╗ ║ 干支时辰 DNA 引擎 · Ganzhi-Shichen DNA Engine v∞.1.0 ║ ║ ║
这部分是预训练,目的是让 AI 简单学会基础语法,能够续写语料。1.0 开始的开始这个项目的起源在于斯坦福的 AI 神课 CS336。个人认为这门课的作业部分教育指导意义远大于讲课视频,Transformer、优化器等等等等都是要亲手实现才能理解,看视频、看blog、单纯调用 torch.nn.functional 库中的函数与类永远无法弥补此点。
矩阵
——矩阵
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 openEuler 社区
openEuler 社区
 AtomGit AI 社区
AtomGit AI 社区


 智能体开发者社区
智能体开发者社区

 HarmonyOS开发者社区
HarmonyOS开发者社区



 AI编程社区
AI编程社区






 科技大视野开发者社区
科技大视野开发者社区

 EazyDevelop社区
EazyDevelop社区