登录社区云,与社区用户共同成长
邀请您加入社区
文本分类实践:从数据探索到方案对比 本文探讨了文本分类在实际场景中的应用及两种实现方案。文本分类广泛应用于内容平台分类、电商评论分析、风控合规等领域,核心价值在于自动化处理海量文本数据。实验基于CLUE/TNEWS数据集展开,分析显示数据存在类别不均衡(23倍差异)、文本短(平均22字)等特点。 方案一测试了调用DeepSeek-V4大模型API的效果,结果显示:DeepSeek-V4-Pro零样
2018-2019年是AI大模型发展的重要萌芽期。OpenAI和谷歌先后推出GPT-1和BERT两大标杆模型,分别代表生成式和理解式两大技术流派,奠定了大模型发展的基础格局。这一时期的核心突破在于预训练技术的成熟,使AI能够通过海量无标注数据自主学习语言规律,再通过少量微调适配具体任务。虽然初代模型在文本理解、简单对话等方面展现出智能,但仍存在逻辑薄弱、通用性差等局限。此时的大模型主要作为实验室技
Day07 | BERT 中文微调实战:Transformer 的另一半
双向理解:突破传统模型 “单向” 局限,真正像人一样结合上下文;迁移能力强:预训练一次,就能通过微调适配几十种语言任务,不用为每个任务从头训练;语义理解深:能处理一词多义、歧义句等复杂语言现象,比如区分 “打酱油” 是 “买酱油” 还是 “凑数”。Matthews 相关系数(Matthews Correlation Coefficient,简称 MCC)1 表示预测完全正确;0 表示预测结果与随机
当用户与语音助手交互时,自动语音识别(ASR)模型将语音转为文本。由于核心ASR模型训练数据有限,对罕见词句处理能力较弱,因此需通过语言模型对识别假设进行二次排序。传统方法使用长短期记忆(LSTM)语言模型,而本文提出基于BERT的RescoreBERT模型,显著提升准确性。该技术尤其擅长处理罕见词(如"fission"),通过结合初次分数与判别式训练,显著提升排序准确性。更多精彩内容 请关注我的
tokenizer 先分词,BERT 再编码,切片 [:,0,:] 拿句向量!全文代码 ≤ 30 行,复制即可跑通。
收藏干货:大模型是 "智慧大脑",AI Agent 才是 "实干手脚",普通人这样抓红利
移动语义虽然强大,但也需要谨慎使用。常见陷阱包括:移动后使用源对象(除非明确知道其状态)、过度使用std::move反而阻碍编译器优化、未能正确实现移动操作的异常安全保证。最佳实践包括:为资源管理类实现移动操作、理解编译器生成的默认操作、在适当场合使用std::move、并始终考虑异常安全性。通过深入理解移动语义和现代内存管理技术,C++程序员能够编写出既安全又高效的程序,充分利用语言特性提升性能
保证100%免费。
技术选型从来不是比参数的游戏。真正的高手,懂得根据团队能力、业务场景和发展阶段,做出平衡取舍。希望这篇文章能帮你少走弯路。如果觉得有用,欢迎转发给正在纠结的同事。也欢迎留言告诉我们:你们正在用哪个AI Agent框架?遇到了哪些挑战?一起交流,共同进步。💪。
利用C++协程(`std::coroutine`)或用户级线程框架(如boost::fiber)实现无中断的流水线任务执行。- 无锁架构:原子操作(`std::atomic`)与内存屏障(`memory_order`)减少锁竞争;- 细粒度控制:通过`std::thread`和`std::future`实现线程生命周期管理;- 基于`std::atomic_flag`或`Compare-And-S
pers looking to harness the power of modern JavaScript developme
字节跳动 DeepSeek R1 语言模型的对话交互能力、Bert 模型的文本理解优势,结合 Django3 与 Vue2 的前后端开发架构,能够实现就业数据的多维度分析、可视化呈现与精准推荐,构建高效、智能的就业服务生态,因此开发基于深度学习的大学生就业数据分析可视化推荐系统。
Python+Sentence-BERT|Ollama 稠密检索
特别要提的是手眼标定模块,我们用Halcon实现了一套九点标定法,这个环节直接关系到抓取的成败。不过要提醒的是,千万别在未隔离的车间用WiFi传输图像——我们吃过电磁干扰导致坐标跳变的亏。四轴抓取视觉旋转标定源代码,基于VS2015 C++ 实现,仿雅马哈四轴机械手抓取程序,实现把两个任意摆放的物料通过视觉算法和运动控制指令定位摆放到指定的位置并拼接起来。使用研华控制卡搭配工业相机实现,图像算法使
我们先从一个。
通过在 RHEL 8 上构建 NLP + BERT 驱动的智能客服系统,A5数据显著提升了系统对自然语言的理解能力与整体响应性能。GPU 部署使得每次推理响应时间从传统 CPU 的数百毫秒降至数十毫秒级别,满足在线高并发场景需求。结合 TorchScript 和并发服务框架,整体架构具备良好的扩展性与稳定性。未来还可引入更轻量级的 BERT 变种(如 DistilBERT、TinyBERT)进行边
✔ 构建工业级分类系统✔ 对比多种模型路线✔ 解决层级标签一致性问题✔ 实现轻量化部署方案理解系统结构才是关键在电商文本分类中,决定上限的从来不是模型,而是“如何拆解标签空间”。
这就像使用一台先进的 CT 机(语义级 BERT)配合精通解剖的影像医生(序列建模 BiLSTM),再由质控科(CRF)确保报告标签的全局合法性——三个组件各司其职,共同输出精准的实体边界标记。A: 传统 CRF 在转移矩阵初始化不当时容易梯度爆炸/消失,FixedCRF 通过约束转移分数、注入医疗实体转移先验(如 B 后只能接 I 或 E,不能直接 O)稳定了训练过程,并在对数空间优化前向计算,
本文对比了三大预训练模型:BERT(Encoder-only)擅长语义理解,GPT(Decoder-only)专精文本生成,T5(Encoder-Decoder)统一处理各类任务。结合代码实战与避坑指南,助开发者按任务精准选型。
本文系统对比 BERT 和 GPT 两条大模型技术路线,覆盖 Transformer 架构差异、训练目标差异(MLM vs NTP)、看文本方式差异(双向 vs 单向)、任务适配差异(理解 vs 生成)以及工程选型差异。BERT(Bidirectional Encoder Representations from Transformers)由 Google 于 2018 年发布,主打判别式语义理解
当输入为单个文本时,BERT输入序列是特殊类别词元“<cls>”、文本序列的标记、以及特殊分隔词元“<sep>”的连结。当输入为文本对时,BERT输入序列是“<cls>”、第一个文本序列的标记、“<sep>”、第二个文本序列标记、以及“<sep>”的连结。因此,多层感知机分类器的输出层(的前向推断给出了输入文本的每个词元和插入的特殊标记“<cls>”及“<seq>”的BERT表示。将一个句子或两个
2021年4月,《自然·机器智能》发表研究,展示了一款仿生耳朵装置,其声源定位精度超过蝙蝠耳朵。该装置通过马达驱动人工耳廓摆动,模拟蝙蝠耳廓的多普勒效应,利用麦克风接收声波信号。神经网络经过训练后,能解析耳廓振动产生的频率偏移,从而精确定位声源方向。这项研究为高精度声源定位提供了新思路。
提供开箱即用的BERT-BiLSTM-CRF医学命名实体识别完整方案:含已验证可运行代码、天池医学文本数据集(支持自定义替换)、配套讲解视频、预训练模型及人工注释版源码,助力快速上手与二次开发。
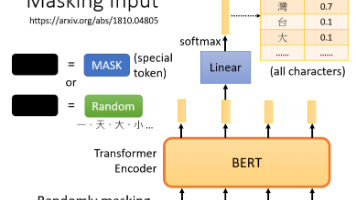
自监督学习无需人工标注,利用无标签的数据本身构造“输入-输出”对,实现类似有监督的训练。BERT 的预训练过程便是一种自监督学习:随机遮盖(mask)部分文本,然后让模型去预测被遮盖的内容,从而“自我监督”地学习语言知识。BERT 是 Transformer 结构的 Encoder,它接收一个序列输入并输出相同长度的序列向量。在训练过程中。我们知道被mask的字符是什么,而BERT不知道,我们可以
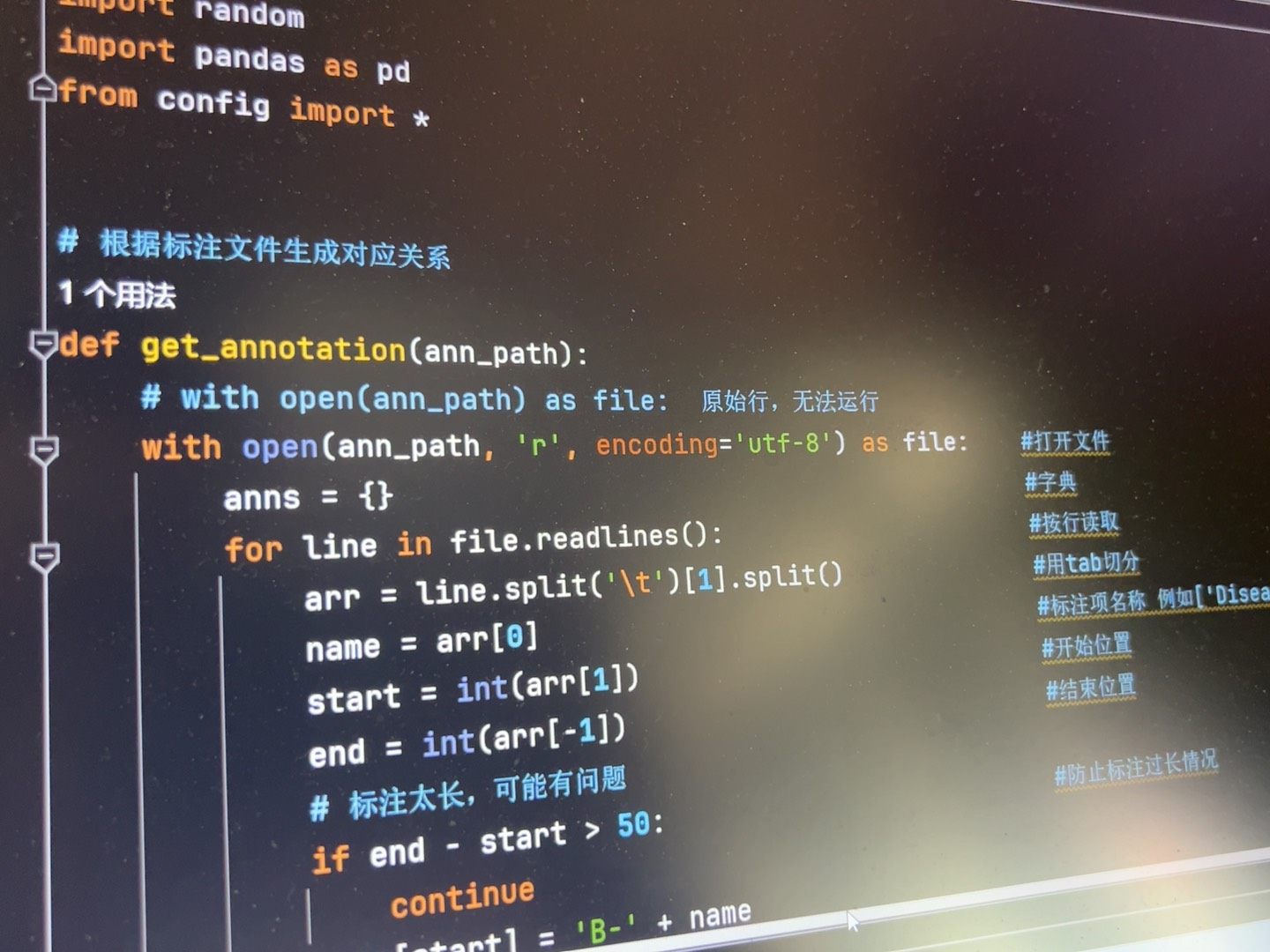
这里数据提取器中要进行训练集和验证集的划分,取20%作为验证集# 数据集self.X = xreturn self.X[item], self.Y[item] # 数据集一般不让返回str, 要写在字典中,或者转为矩阵。# 数据生成器x, label = read_txt_data(path) # 读取数据集# 数据集没有划分,所以要分割训练集和验证集,valSize为验证集的比例20%文本要先进
一文梳理 2025 年全球 AI 大模型排名,涵盖 DeepSeek、通义千问、GPT‑4o……
bert
——bert
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DeepSeek技术社区
DeepSeek技术社区


 AI Agent技术社区
AI Agent技术社区


 AMD开发者中国社区
AMD开发者中国社区




 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区



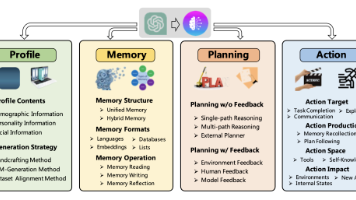

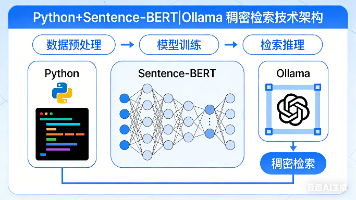


 快递鸟社区
快递鸟社区





 DAMO开发者矩阵
DAMO开发者矩阵