登录社区云,与社区用户共同成长
邀请您加入社区
浏览器插件:适配Edge、Chrome、360浏览器、火狐、Safari,安装后可直接抓取ChatGPT网页对话内容,一键导出;移动端小程序:无需下载安装,微信端直接打开使用,临时快速导出短篇幅文档;手机APP:安卓、苹果iOS、鸿蒙系统独立APP,支持本地文件存储、自定义模板保存;平板端:苹果iPad、华为平板、小米平板、联想平板专属适配布局,大屏排版预览更清晰;网页版:任意浏览器打开即可使用,
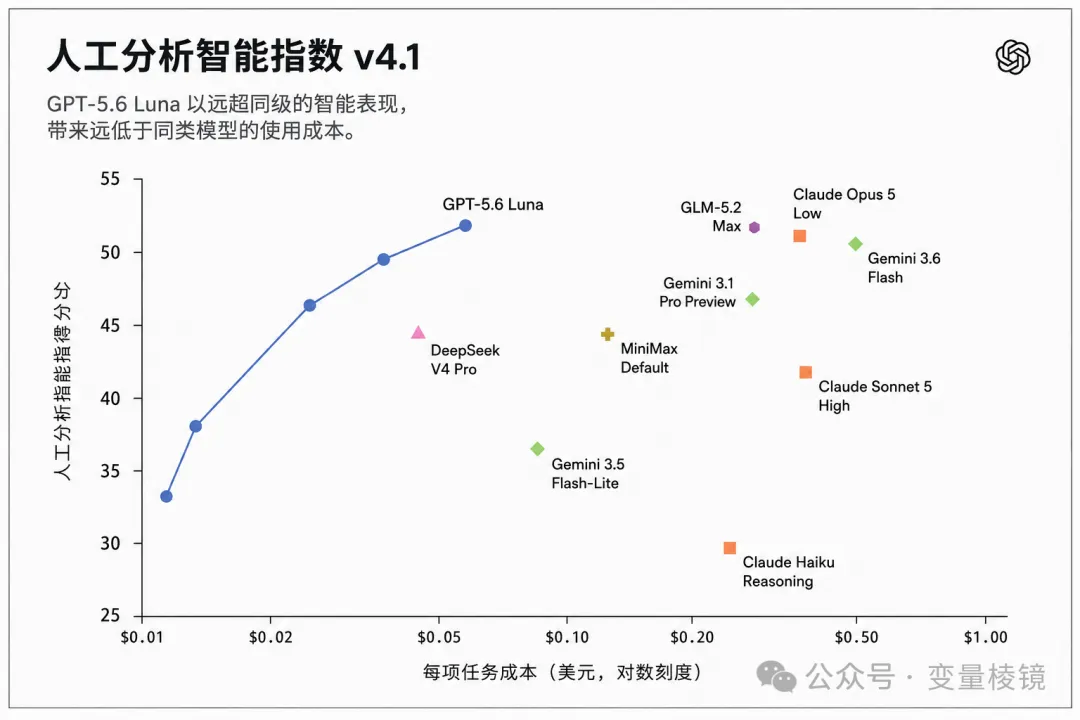
OpenAI 已经把 GPT-5.6 Luna 的 API 价格砍掉 80%,Terra 也降了 20%。所以,重复活交给 Luna,日常活先试 Terra,真正难的留给 Sol,急到值得多付2倍时再开 Fast。朋友跟我说 Codex 最让人心疼的时候,不是代码没改对,而是任务还没跑完,额度已经归零!但 ChatGPT 和 Codex 订阅费没降,只是同样的额度,但现在能多跑一些活。如果你需要读
本文作者分享了在高温周末研究AI Agent的经历。主要使用PiAgent工具,同时参考Codex资料,探索不同Agent的共通点。通过实践掌握了Skill概念和电子形象定制,最大的收获是理解了子Agent的概念,这为本地小模型的应用开辟了新思路。作者将日常文档化处理与Skill功能类比,并成功应用于代码分析和保险申请等实际场景。本地模型的运用节省了云端计算成本,使作者能够进行大量测试。这次探索标
本文是一篇AI核心术语扫盲指南(系列第一篇),旨在帮助读者掌握大语言模型(LLM)的基础概念。文章从AI技术发展脉络切入,重点解析了Transformer架构、注意力机制、Token/Embedding/Vector三大核心概念,并解释了Context Window、Prompt等关键术语。通过实际案例和对比表格,文章揭示了LLM的本质不是简单的聊天机器人,而是能够对语言本身建模的概率预测系统。掌
千问办公(QwenWork)是阿里巴巴推出的一站式 AI Agent 办公平台,产品哲学是「不止于对话,更注重交付」——它不满足于回答问题,而是拆解任务、调用工具、直接交付 PPT / Word / Excel / 网页 / 代码等可用产物,并深度打通钉钉生态。
这几个概念可以放在同一条线上看:AI 应用,尤其是 AI Agent,从能演示,到能放进真实项目里跑,中间经历了几次工程重心的变化。下面分阶段看。
当前,AI技术“落地难”仍是行业普遍痛点。后续公司将持续依托分层项目架构敏捷迭代完善中台体系,以常态化系统化内部培训持续夯实团队AI实战能力,对内实现全业务提质增效,对外输出标准化企业AI转型解决方案,深耕特色FDE职业教育赛道,以AI原生组织姿态,奔赴下一个十年高质量发展新征程。2026 年 6 月,科莱特 AI 数智中台(一期)已完成学员服务全链路打通,依托 OMO、飞书协同体系与自研“小科助
随着大模型技术加速商业化落地,AI Agent智能体开发已成为上海科技企业数字化升级的重要议题。本文从行业背景、技术路线、应用场景、参与方格局到选型难点进行系统梳理,为有意推进AI智能体项目的企业提供参考。
本文探讨了AI Agent时代对Linux系统工具的新需求。传统工具如df遵循Unix哲学,专注于单一功能,依赖工程师通过经验组合信息来理解系统状态。然而AI Agent需要更直接的上下文信息来减少推理步骤,降低操作风险。文章以x df为例,展示了如何整合文件系统类型、挂载属性等关键信息,使Agent能快速判断存储状态。作者指出,未来需要更多工具来显式表达系统隐藏关系,帮助机器可靠操作计算机,而非
机器人实验室里,这样的画面总是反复出现:屏幕上模拟的机械臂正以完美轨迹移动,但真实世界的一边,玻璃杯还待在桌面上,甚至已被夹爪打翻。今天的机器人世界模型都面临着这样的挑战:夹爪抓不起物体,机械臂无法与环境交互,经过了遮挡之后,预测的画面就完全错了。AI 生成的未来视频每一帧都清晰自然,但内容根本不靠谱。这种现象背后,是具身智能领域的一大悖论:人人在卷的世界模型,物理逻辑却怎么也跟不上。一家成立不到
AI 产出的上限,完全取决于使用者给出的边界、假设与上下文。从 Prompt 工程向 Context Engineering 演进,写出 5 行精准的系统约束与上下文定义,往往比让 AI 盲目试错 100 次更具决定性。定义问题本身,就是在划定 AI 算力的工作靶心。
微分智飞则在飞行具身领域深入探索,将 Seedance 融入飞行机器人应用,打造出一套标准化、高难度的数据集生成流程,能够精准模拟障碍物闪避、室内自主寻路、智能目标锁定乃至复杂镜头运动等真实难题,产出高质量训练数据。增加了视频局部编辑能力,支持在维持整体画面节奏的前提下,对背景、商品、人物等局部元素进行精准修改;此次升级将视频生成从“能生成”推向“可修改、可迭代、可交付”的新阶段,其应用边界也正从
Agentic RAG不是什么新概念炒作,而是RAG发展到一定阶段的必然演进方向。当基础检索能力做到极致后,再往上提升效果,就必须从架构层面升级,给大模型加上决策和行动的能力。对于企业来说,它的真正价值不是“更智能的聊天机器人”,而是真正能替代人工处理大量重复性的咨询、查询、整理类工作,把沉淀在文档和系统里的知识真正释放出来。落地的时候不用追求一步到位,从最痛的场景切入,先做好基础RAG的优化,再
摘要: AI 导出鸭是一款专为解决ChatGPT复制文本附带星号、格式错乱等问题的工具,提供一键清理和多格式导出功能。核心优势包括:智能清洗星号标记、保留原生排版、支持Word/PDF/Markdown等格式转换,以及跨终端同步(浏览器插件、APP、网页端等)。相比传统工具(如WPS、Pandoc),AI 导出鸭通过双层处理架构(文本清洗+多格式适配)显著提升效率,用户实测处理3000字文本仅需1
随着人工智能技术在办公场景中的深度渗透,大量用户通过ChatGPT等生成式AI工具获取文本内容后,面临着如何将这些内容有效保存与分发的现实问题。根据《中国AIGC文创产业指数2024》报告,AIGC参与的文创营收在2025年有望突破1000亿元[[1]],这意味着海量AI生成内容的存储需求正在快速增长。用户在使用ChatGPT进行内容创作时,常遇到以下核心痛点:首先,生成的长篇幅对话内容难以直接保
文章摘要: 《AI导出鸭:一站式解决AI生成Excel表格的导出痛点》聚焦数字化办公场景下AI制表的导出难题,揭示纯复制粘贴格式丢失、工具碎片化、跨设备不兼容、批量效率低等核心痛点。AI导出鸭通过多模态解析引擎、原生格式渲染和跨终端适配技术,实现98.7%的表格还原率,支持复杂函数、图表无损导出及50+文件批量处理。对比五大方案(手动复制、WPS、提示词调试、Pandoc等),其零代码操作、全平台
这不是在做一个"更好看的 Mermaid 主题",而是对 AI 辅助画图工作流做了一次范式重构。当前大多数 AI 画图工具(包括让 GPT/Claude 生成 Mermaid 代码)的痛点在于:自动布局引擎(dagre、ELK)把布局决策权拿走,输出结果千篇一律——8 个组件和 40 个组件的图在视觉逻辑上毫无区别,颜色语义在每次对话里都可能不一致。
摘要: 针对豆包平台缺乏代码一键转图片功能的痛点,AI导出鸭通过AI语义解析+格式编译技术,实现豆包代码/Mermaid图表无损转高清图片及标准化文档。其核心优势包括智能识别内容类型、保留代码高亮排版、支持批量导出及全终端适配。实测数据显示,其代码转图完好率达98.6%,远超手动截图或传统工具。覆盖浏览器插件、小程序、APP等多端场景,显著提升用户效率,填补AI生成内容导出领域的市场缺口。(148
不是一个安全工具,而是一个。它试图解决的核心问题是:当 Claude Code、Cursor 这类代码 AI 客户端面对一个安全分析任务时,它并不知道该用jadx还是apktool,该走 APK 逆向路径还是 ELF 二进制路径。这个项目通过预定义的路由规则、标准化的工作流 Playbook 和自动化的工具索引,让 AI Agent 不再靠猜,而是按结构化流程执行。这处于这一演进阶段的典型产物——
上周末逛GitHub Trending,前十里面有五个跟AI Agent有关,其中有个项目我点进去之后愣是看了半小时——egolite。 它不是那种"又一个浏览器自动化框架"的套娃项目。它解决了一个特别具体但特别烦人的问题。 用Claude Code或者Codex做过浏览器自动化的人应该都懂那种痛。你让Agent帮你填个表单,它就在你浏览器里一顿乱跳,标签页飞来飞去,你啥也干不了。然后你想,那我给
文章摘要 jcode是一个用Rust开发的开源AI编程助手运行框架,专为多会话、多Agent协作设计。它通过Rust的高效性实现了显著性能提升:内存占用仅为Claude Code的1/20,启动速度快245倍。其核心创新包括:语义向量记忆系统实现被动联想式记忆、Swarm模式支持多Agent实时代码协作、Self-Dev模式允许Agent修改自身源代码。这些设计使其成为AI编程领域的新型"操作系统
AI Agent智能体正从概念走向企业真实部署,上海已成为国内相关开发力量最为集中的城市之一。本文系统梳理AI Agent的技术架构、主流落地路径、行业应用成熟度差异及选型难点,帮助企业在选择上海AI智能体开发公司时建立清晰判断框架。文中亦涉及。
*PowerShell** | 逆向/授权渗透/安全研究的 AI 技能路由包:AI 自动路由 + 按需自举工具链 + 自进化知识库,支持 Claude Code、Kiro、Cursor、Cline 等客户端。**Python** | AI Agent 技能包,可跨 Reddit、X、YouTube、HN、Polymarket 及全网研究任意主题,并综合成有据可查的摘要。**Jupyter Note
8月1日,The Information爆出OpenAI正在测试一个全新模型家族——暂定名"Astra"。据报道,CEO奥尔特曼本周已带着它飞赴华盛顿,在美国国会山向参议员闭门演示。Astra的核心卖点不是参数更大或价格更低,而是让一群AI智能体"拉个群一起干活":面对一个复杂项目,Astra可以把任务拆开,交给不同Agent分头推进——有人查资料,有人写代码,有人验证结果,还有一个Agent负责
本文介绍了如何通过微信ClawBot插件接入OpenClaw服务,实现在微信中直接与AI对话。主要内容包括:需在微信设置中启用官方ClawBot插件;通过终端命令安装插件并扫码授权;支持文字、语音等多种消息类型(部分功能取决于模型能力);当前仅支持私聊,需OpenClaw 2026.3.22及以上版本。还提供了安装问题排查方法和使用场景建议。
本文系统梳理了AI领域Agent、Function Calling、Skill和MCP等核心概念的关系与差异。Agent通过自主规划、工具调用和记忆能力实现任务自动化,区别于传统对话模式;Function Calling让AI掌握工具使用方法;Skill以自然语言指导AI处理特定任务;MCP协议则标准化AI与工具的交互方式。这些技术共同构建了AI自主工作的能力框架,使AI从简单对话转向实际执行,但
摘要: AI导出鸭是一款智能化表格导出工具,针对Gemini制作Excel表格后存在的格式错乱、导出耗时等问题,提供智能解析、格式自适应转换、跨端同步等核心功能。相比传统导出方式,AI导出鸭显著降低出错率(2.1% vs 32%),提升导出效率(0.3分钟/份)。支持全终端覆盖与AI自定义提示词生成,适配各类办公场景,成为补齐智能办公闭环的关键工具,尤其适合需要高效处理复杂表格的职场用户。
浏览器插件端:Edge、Chrome、360、火狐、Safari五大主流浏览器插件,可一键抓取ChatGPT网页内表格,免复制快速导出;小程序端:微信小程序,无需下载安装,手机临时制表导出首选;手机APP端:安卓、苹果iOS、鸿蒙系统专属独立APP,支持离线缓存表格文本、批量打包导出;平板端:适配苹果iPad、华为平板、小米平板、联想平板全型号,大屏优化排版,适合长时间处理大型数据表;网页端:独立
浏览器插件:适配Edge、Chrome、360浏览器、火狐、Safari五大主流浏览器,电脑端打开ChatGPT网页即可一键调用导出功能;小程序:微信小程序轻量化使用,无需下载安装,手机临时导出表格快速便捷;APP客户端:覆盖安卓、苹果iOS、鸿蒙系统手机,独立客户端支持批量导出、本地文件管理;平板端:适配苹果iPad、华为平板、小米平板、联想平板,大屏适配表格预览功能;网页版:独立在线网页工具,
文章浏览阅读468次。Python作为一种高级编程语言,凭借其解释器和标准库实现了强大的跨平台能力,能在多种操作系统和设备上运行。尽管面临版本兼容性和性能挑战
按"合规AXB+ASR≥95%多轮+人机转人工+CRM闭环+180天录音"五模块评判,中小企重轻量闭环、大厂重全渠道。千创云呼"AI初筛→CRM打标→坐席弹屏+摘要"闭环,接企微/校管家/钉钉,老生续费自动带"剩余课时",不用销售重复问——这是中小教培最实用的"收口能力"。千创云呼教培/家装/本地生活预置多轮话术,能采"面积/年级/到店时间"等槽位自动打标,比规则机器人多收30%有效信息,是中小电
找电销机器人"厂家直销",核心是避开"贴牌二道贩子",锁定"自研系统+持牌线路"的源头厂商——前者加价30-50%、无底层定制、出事层层甩锅;千创云呼(四川千创云呼信息科技,成都双流,全网B24+等保三级+ISO27001、自研大模型ASR 98.2%)是西南自研源头厂,官网/企微直客、无多级代理加价,教培/家装/本地生活话术可零代码改,不转售第三方系统。事实:西南K12/生鲜用千创云呼"AI初筛
通付盾在2026苏州人工智能应用博览会上展示企业级AI智能体工厂LegionSpace,推出三级智能体运行模式及六大核心技术组件,覆盖金融、能源等行业场景。该系统以数字身份为根基,强调安全可控,解决企业AI部署中的数据安全、业务适配等痛点,助力数字化转型。通付盾立足长三角,推动可信AI产业发展,实现AI从技术到业务的高效转化。
摘要 技术史上常出现"预见未来却错失未来"的案例:CoreOS(容器化操作系统)、Xerox(图形界面)、Netscape(浏览器)均率先提出颠覆性理念,但最终被巨头吸收或替代。它们的失败揭示了关键规律——技术正确仅是起点,真正的胜者需掌控分发权、生态位和平台化能力。如今AI Agent领域正重演这一剧本:尽管方向已成共识,但核心竞争将围绕生产化部署、安全治理和入口控制展开。历史表明,最早看见未来
OpenAI 表示,这次实验希望提醒开发者,基准测试很少只测量模型本身。它们同时也受到 API 设置、测试框架设计以及提示词方式的影响。对于希望最大化模型性能的 API 开发者,OpenAI 建议采用与自身产品一致的配置;对于模型之间的比较,OpenAI 也建议参考采用这些设置的评测结果,因为它们更接近 ChatGPT 和 Codex 中的真实使用环境。
AI
——AI
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 人工智能6S服务平台
人工智能6S服务平台

 AtomGit AI 社区
AtomGit AI 社区

 AI Agent技术社区
AI Agent技术社区

 DAMO开发者矩阵
DAMO开发者矩阵


 智能体开发者社区
智能体开发者社区
 2048 AI社区
2048 AI社区





 openEuler 社区
openEuler 社区





 EazyDevelop社区
EazyDevelop社区