




- @a503244552
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
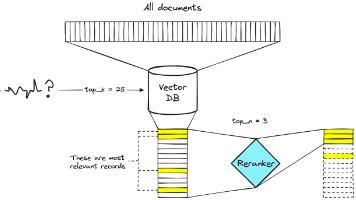
摘要:本文探讨了RAG系统中召回结果排序的重要性,指出单纯依赖相似度检索容易导致回答偏差。作者重点介绍了LangChain4j中的两项关键技术:RRF(倒数排名融合)和Rerank(重排)。RRF通过多路召回结果融合提升稳定性,而Rerank则基于语义相关性进行精排。文章详细分析了两种技术的适用场景、实现原理和工程实践,建议采用"多路召回→RRF融合→Rerank精排"的优化路
本文介绍了从微软商店外下载Codex的解决方案。首先通过特定网站获取Codex的产品ID,搜索并下载安装包;然后将.msix文件重命名为.zip并解压app目录内容;若浏览器下载失败,则需使用PowerShell的curl命令获取文件。最后通过解压后的文件夹运行Codex.exe即可完成安装。该方法解决了官方渠道下载困难的问题,为开发者提供了便利的替代方案。
摘要:Adam优化器是PyTorch中结合动量和自适应学习率的优化算法,包含四个核心部分:参数(模型权重)、梯度(损失函数偏导)、一阶动量(梯度指数平均,平滑更新方向)和二阶动量(梯度平方指数平均,自适应调整学习率)。它通过m_t考虑历史梯度趋势,v_t衡量梯度变化幅度,实现稳定高效的参数更新。公式θ_{t+1}=θ_t-η·(m_t/(√v_t+ε))展示了这些组件的协同作用,使Adam兼具Mo
摘要:pgvector通过将文本、图像等转为向量嵌入PostgreSQL,支持基于向量相似度的检索。查询时计算query向量与库中向量的距离(如Cosine、L2等),返回最相似的Top-K结果。核心索引方案包括: HNSW:构建向量近邻图,查询时沿图快速跳转,适合高召回场景,但构建慢、内存占用高; IVFFlat:先聚类再搜索相关簇,构建快且省内存,但性能依赖参数调优。 推荐:RAG场景优先选H

学习 DeepSeek 蒸馏模型,最适合从“离线 SFT 蒸馏”入手,而不是一上来复现完整 RL/GRPO。DeepSeek-R1-Distill 系列的核心不是“把 671B 模型压缩成 7B”,而是:这本质上是 sequence-level distillation / response distillation,不是传统意义上拿 teacher logits 做 KL 蒸馏。DeepSee

摘要:vLLM本地部署后,可通过指令启动API服务并访问http://localhost:8000进行交互。支持两种调用方式:1)命令行方式,使用curl发送GET/POST请求获取模型信息或生成对话;2)Python脚本方式,通过requests库调用ChatCompletions接口,兼容OpenAI风格。两种方法均需指定模型名称、消息格式和生成参数,支持调整temperature等参数控制输

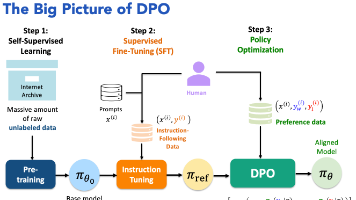
本文介绍了DPO(Direct Preference Optimization)及其相关技术,用于替代复杂的RLHF(强化学习人类反馈)方法。DPO将人类偏好数据转化为可直接反向传播的损失函数,简化了训练过程。文章对比了多种DPO变体,包括DPO、IPO、KTO、ORPO、SimPO等,分析了各自的适用场景和优缺点。DPO通过隐式奖励模型(即语言模型本身)替代显式奖励模型,降低了训练复杂度。工程实
学习 DeepSeek 蒸馏模型,最适合从“离线 SFT 蒸馏”入手,而不是一上来复现完整 RL/GRPO。DeepSeek-R1-Distill 系列的核心不是“把 671B 模型压缩成 7B”,而是:这本质上是 sequence-level distillation / response distillation,不是传统意义上拿 teacher logits 做 KL 蒸馏。DeepSee
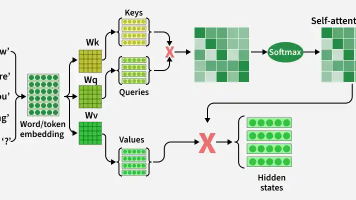
本文解析了注意力机制中Q、K、V的本质关系。三者并非独立语义,而是同一token特征的不同投影:Q表示查询意图,K负责索引匹配,V提供实际内容。注意力输出是Q/K计算权重后对V的加权融合,形成包含上下文的新表征。在医学影像中,这种机制能自动学习病灶-器官的空间关系和语义关联,但其具体语义取决于监督信号的设计。相比传统卷积,注意力能建模全局token关系,多头机制可捕获不同类型关联。最终输出是上下文
深度学习优化器选择指南:AdamW已成为现代AI任务(如大语言模型、多模态)的标准配置,因其自适应学习率和开箱即用的优势显著提升训练效率。传统SGD+动量仅建议用于对泛化性能要求极高的CV任务或竞赛场景。实际工程中优先推荐AdamW+CosineWarmup组合,在保证稳定性的同时大幅降低调参成本。优化器的核心差异在于:SGD使用全局固定学习率,依赖精细调度;Adam则自动调整各参数学习率,更适合
