




- @weixin_52908342
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了一个包含3000张图像的18类户外生活垃圾检测数据集,专为YOLO等目标检测模型训练设计。该数据集覆盖塑料袋、塑料瓶、易拉罐等18类高频垃圾,包含真实户外场景下的复杂环境图像,如城市街道、社区公共区域等,并考虑光照变化、背景干扰等因素。数据集采用高质量人工标注,标准化结构兼容主流框架,适用于智慧环卫、无人机巡检、环卫机器人等应用场景,具有场景真实性强、类别设计合理等优势,能有效提升模型在

本项目分享了一个基于STM32和ADXL345三轴加速度传感器的完整开源方案,包含硬件接线、IIC/SPI双驱动、姿态解算算法和上位机可视化代码。ADXL345是一款±2g~±16g量程的数字加速度计,广泛应用于姿态检测、倾角测量等领域。项目提供了详细的流程图、硬件连接说明(IIC模式)和核心代码实现,包括传感器初始化、数据读取以及Roll/Pitch姿态解算。关键技术点涵盖量程选择、滤波处理和动

北京积水潭医院贵州医院作为贵州省首个国家区域医疗中心,通过全栈国产化改造实现双院区业务协同与数据互通。项目以金仓数据库为核心搭建医疗级数据底座,解决多院区数据同步、业务高可用、信创合规等难题,历时4个月完成40余个核心系统批量上线。改造采用主备集群架构,支持跨院区实时数据同步与一致性校验,并针对医疗高并发场景优化数据库性能。文中提供SpringBoot+金仓数据库的适配代码,涵盖数据源配置、诊疗查

随着生成式AI技术的快速发展,如何快速构建和部署大模型应用成为开发者关注的焦点。华为云推出的**Dify-LLM应用开发平台**,结合**Flexus X实例**的卓越性能,为用户提供了一站式解决方案。本文将从单机部署、高可用架构搭建到AI Agent开发,全面解析华为云Dify平台的部署与开发流程,并重点展示Flexus X实例在算力、成本、可靠性等方面的核心优势。
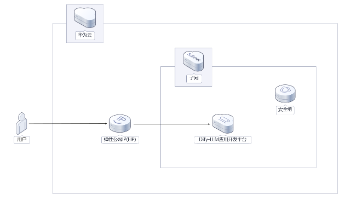
在后端开发领域,知识体系庞大且更新迅速,从语言特性到分布式架构,每一层都存在大量细节与隐性难点。传统学习方式依赖零散搜索和被动查阅,难以形成系统认知,也不利于快速解决实际问题。随着 AI Agent 的出现,这一模式正在改变——开发者可以通过对话直接获取结构化、工程化的知识支持,并在真实场景中即时应用。结合 Rokid AI Glasses,这种能力进一步从“屏幕内”延伸到“现实中”,使 AI 不

用 vLLM 的 Anthropic API 兼容层(把 GLM-5.2 当 Claude 来服务)时,如果后端模型推理失败返回了这不是 GLM-5.2 推理问题,而是。下面给出定位与修复(先判状态、再转换、错误透传)。
第一层加了默认,但要保证字段定义不依赖任何新版 pydantic 独有语法。# 兼容 pydantic v1 与 v2 的保守写法清单:# 1) 不用 v2-only 的 `Field(validation_alias=...)` 复杂用法(除非 v1 也支持)# 2) 可选字段一律 Optional[T] = Field(default=...)# 3) default_factory 用无参
本文记录了将7-Zip压缩功能适配为HarmonyOS PC可复用三方库的完整过程。通过裁剪7-Zip 26.01源码,使用CMake交叉编译为Native库,并通过Node-API暴露给ArkTS调用,最终打包成HAR/OHPM可复用库。项目实现了.7z格式的压缩、解压和测试功能,在鸿蒙PC设备上验证通过。文章详细介绍了工程结构、环境配置和适配过程中的关键点,包括Native编译、NAPI异步任
在国内旅游逐渐普及、移动出行服务日益丰富的背景下,旅游类应用成为开发者关注的重点。传统的旅游应用通常依赖复杂的移动端开发框架,如 Android 或 iOS 原生开发,而跨平台框架在性能和原生体验上常存在一定差距。开源鸿蒙(OpenHarmony)的出现,为开发者提供了一套统一的多端原生开发方案,使得同一套代码可以覆盖手机、平板、PC 乃至 IoT 设备。

本文详细介绍了在CentOS 8环境下交叉编译OpenSSL 3.5 LTS版本并适配鸿蒙PC(aarch64-linux-ohos架构)的全过程。主要内容包括:搭建OHOS SDK工具链环境,配置交叉编译参数,生成鸿蒙PC可用的libssl.so.3、libcrypto.so.3和openssl可执行工具。通过完整的编译部署流程,实现了OpenSSL在鸿蒙系统上的版本可控和安全策略统一,为网络通
