登录社区云,与社区用户共同成长
邀请您加入社区
这篇文章不是教程,也不是方法论。就是一个写了 8 年代码的普通程序员,跟你聊聊心里话。如果你也在想"35 岁以后怎么办",这篇文章可能跟你有关。副业方向很多:接外包、做自媒体、开淘宝店、做知识付费……它跟我 8 年的技术积累直接相关我写 Go、Java、Vue,这些技术在 AI Agent 开发中完全用得上。不是从零开始学一个新技能,而是在已有能力基础上往前走一步。它是真正的趋势不管你承认不承认,
本文详细介绍了互联网产品经理转AI行业的九大可行方向,包括电商、原生应用、金融、硬件、机器人、教育、医疗、制造等,并分析了各行业的优劣势、岗位需求和薪资水平。文章强调行业选择比技术学习更重要,建议小白优先考虑电商和AI原生应用,有背景的从业者则需结合自身经验和未来职业发展选择合适方向。同时,文章还揭示了AI产品经理薪资真相,指出公司规模、工作年限、学历和能力强弱都会影响薪资水平,并给出了一些实用的
libusb是一个使用C编写的库,它提供USB设备的通用的访问方法。APP通过它,可以方便地访问USB设备,无需编写USB设备驱动程序。可移植性:支持Linux、macOS、Windows、Android、OpenBSD等用户模式:APP不需要特权模式、也不需要提升自己的权限即可访问USB设备支持所有USB协议:从1.0到3.1都支持libusb支持所有的传输类型(控制/批量/中断/实时),有两类
2026年,掌握AI智能体开发成为大模型开发求职的核心加分项。本文提供了一套分层递进的AI Agent系统化学习路径,分为四大阶段:提示词与LLM调用、ReAct到LangChain框架学习、记忆与外部工具、多智能体协同开发。涵盖提示词工程、大模型API对接、ReAct推理模式、LangChain/LangGraph开发、记忆系统、工具开发及多智能体框架等核心内容,并配套4个实战项目,助新手稳步掌
2026年大模型学习的核心趋势是轻量化、实战化、工程化、场景化,不再是少数算法精英的专属领域,而是普通人可以快速入门、落地就业的通用技术。遵循「基础筑基→原理吃透→实战落地→高阶优化→就业深耕」的路线,稳步推进、持续实战,3-6个月即可从零基础成长为具备独立项目落地能力的大模型开发者,适配职场赋能、转行就业、技术进阶等各类需求。如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学A
这篇文章深入浅出地讲解了图像数字化处理的核心概念,重点剖析了模型如何"看到"图像数据。主要内容包括: 模型视角:模型看到的是排列好的数字而非视觉图像 图像处理链路:图片→像素→通道→张量→网络输入 关键概念解析:像素、通道、张量、shape、batch和归一化 张量格式转换:HWC、CHW、BCHW的区别与应用场景 工具差异:OpenCV、PIL、PyTorch处理图像的不同特点 预处理要点:归一
垂直大模型就是为了解决这三个痛点。但做不做、怎么做、做了值不值——这是一系列复杂的工程决策。
name(4个ASCII字符) || 应用自定义数据(可变长) || 多媒体会议应用 || || || 音频 RTP 会话 | | 视频 RTP 会话 || (独立 SSRC 空间) | | (独立 SSRC 空间) || RTP 数据包 | | RTP 数据包 || (偶数端口) | | (偶数端口) || RTCP 控制包 | | RTCP 控制包 || (奇数端口) | | (奇数端口) |
特性说明可靠传输通过序列号检测丢包,通过重传修复有序传输字节流保证顺序,不会乱字节流服务对应用透明,不关心消息边界面向连接通信前必须先建立连接(三次握手)全双工两个方向独立传输数据端口复用用端口号区分同一主机上的不同应用单播一对一通信(不支持广播/多播作为目标)
想象你正在专心看书,突然电话响了。你会:二、STC15 支持多少个中断源?STC15 系列最多支持 19 个中断源,不同型号支持数量不同:型号系列中断源数量STC15F101W8个STC15W10x8个STC15W201S10个STC15F408AD12个STC15W401AS13个STC15W404S12个STC15W1K16S12个STC15F2K60S214个STC15W4K32S419个(
STC15 系列单片机是由STC MCU Limited(宏晶科技)生产的一款基于8051 内核的增强型单片机。所谓"单片机"就是把 CPU(处理器)、内存、输入输出接口全部集成在一块芯片上的微型计算机。就像把一台完整的电脑缩小到一颗比指甲盖还小的芯片里。这是 STC15 家族中最常用、功能最齐全的型号之一。系列电压SRAMUART数ADC定时器特色4.2~5.5V2KB28ch/10bit3个大
本文深入解析了Transformer架构及其在大模型时代的核心地位。文章首先回顾了RNN的局限性(无法并行、长程依赖丢失、状态压缩瓶颈),并指出2017年Transformer通过Self-Attention机制解决了这些问题,实现了完全并行计算和长序列直接关联。核心内容包括: 架构原理:详细拆解Self-Attention、多头注意力、位置编码(重点分析RoPE优势)和完整Transformer
FreeRTOS 是一个实时操作系统内核(RTOS),专为嵌入式系统设计。它把"多任务能力"以库的形式提供给原本只能跑单一程序的裸机(bare metal)应用。FreeRTOS 的发行包形式:一个 zip 压缩包,里面包含:FreeRTOS 支持约 20 种编译器 和超过 30 种处理器架构。每一种"编译器 + 处理器架构"的组合,称为一个端口(Port)。不同端口的移植代码存放在不同子目录中,
本文以阿里为例,探讨了AI大模型岗位的工作日常与职责划分。文章指出,真正参与大模型研发的工程师往往无暇分享经验,网络上的相关描述多来自实习生或离职人员。作者基于实习观察,将大模型岗位细分为五大方向:模型训练/预训练(解决训练稳定性问题、优化效率)、模型对齐/后训练(数据质量把控与评估)、推理优化/部署(降低延迟与成本)、应用开发/工程落地(业务场景适配)以及数据方向(基础设施建设)。其中,模型训练
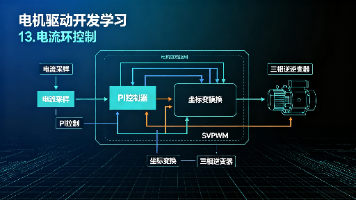
本文摘要: 本文介绍了电机驱动开发中的电流环控制方法。电流环以相电流为被控量,通过PID调节PWM占空比实现恒定转矩输出。与速度环、位置环相比,电流环响应更快,适用于力控场景。文中详细分析了电流环的反馈机制(三相ADC采样)、控制周期(25ms)、零偏校准策略(64次采样均值)及常见问题处理。实验基于野火F407开发板,保留了过流保护功能,通过串口命令可调节目标电流和PID参数。电流环作为后续串级
2026年技术圈的分化愈发明显:降薪裁员潮持续蔓延,传统开发、测试等岗位大批缩水,不少从业者陷入职业焦虑;与之形成鲜明对比的是,AI大模型相关岗位迎来疯狂扩招,薪资逆势飙升150%,大厂更是直接开出70-100W年薪,疯抢具备实战能力的大模型人才,甚至放宽年龄限制,只求能快速落地技术、创造价值!1、窗口期红利,入门门槛友好:不同于成熟赛道的“内卷式招聘”,2026年大模型人才缺口巨大,简历只要达标
本文介绍了基于野火无刷电机驱动板和F407骄阳开发板的直流无刷电机(BLDC)控制实现。主要内容包括:1) 速度控制原理,通过PWM调压和闭环控制实现调速;2) 硬件接线方案,包括开发板与驱动板的连接;3) 软件架构设计,采用模块化编程实现核心控制、PWM输出、按键扫描和串口通信等功能。重点分析了霍尔传感器测速方法和不同PWM控制策略的特点,野火开发板采用ON-PWM调制方式,通过定时器输入捕获霍
消息队列(Queue)信号量(Semaphore)消息队列主要用于任务与任务、任务与中断之间传递数据信号量主要用于任务同步以及资源管理消息队列的作用几乎是不可替代的。如果需要在任务与任务,或者任务与中断之间传递数据,那么消息队列通常都是首选机制。但在实际应用中,很多时候并不需要传递数据。中断通知任务一个任务唤醒另一个任务某个事件发生后通知任务继续执行这种情况,本质上只是 发送通知和接收通知。二值信
自信息、信息熵、条件熵、互信息、KL散度、JS散度、交叉熵、最大熵原理。期望、方差、矩、熵、交叉熵、KL散度(损失函数、分布距离)样本均值收敛、正态分布成因,深度学习采样理论基础。整数规划、动态规划、博弈论。
2026年大模型学习的核心逻辑是分层递进、实战落地、垂直深耕。从零基础编程与通识奠基,到Transformer核心原理,再到RAG、智能体、多模态实战,进阶模型微调优化,最后落地工程部署、细分职业方向,整套路线层层递进、无缝衔接,既适合个人系统自学,也适配求职就业、能力升级的核心需求。大模型行业仍处于高速增长期,技术迭代快但核心体系稳定,只要遵循科学的学习路线,坚持实战驱动,就能快速从入门小白成长
这一段定义了桌子上不同物品的初始放置区域basket_init_region:篮子应该放在桌子的哪个位置。alphabet_soup_init_region、tomato_sauce_init_region 等:每种物品的初始放置范围(x, y 坐标区间)。contain_region:篮子里面的“可容纳区域”。这些区域保证了任务的可重复性(每次初始化位置都在一定范围内)。lisp(:fixtur
本文深入解析了大模型参数量的工程意义及其实际影响。文章指出,参数量并非简单的数字,其背后涉及架构类型(Dense/MoE)、激活参数、数据精度等关键维度。通过拆解Transformer参数构成,推导出参数估算公式(以Llama-3-8B/70B为例验证),并对比了Dense与MoE模型的差异:MoE通过专家机制实现"大容量知识库+小计算量"的特性,但面临显存占用高、部署复杂等挑
网口 eth1和串口 /dev/ttyPS1 相互透传。有很多好用的串口助手,但很难找到一个好用的以太网调试助手。网口数据太多了, 用1 对 1 的 方式接线。向zynq板的串口发送1个字节流(超时封包),zynq板从网口接收一个字节流,从它的串口输出。zynq板通过网口发出( )为了方便学习以太网的帧格式。所以有必要做这个工具。可过滤非ecat的帧。
原始多边形数据(可能来自任何来源)v[曲面细分/三角剖分]- 耳朵裁剪- Delaunay 三角剖分- 处理 T-顶点v[整合]- 顶点合并(去重)- 朝向一致性- 法线平滑(角度加权)v[优化]- 三角扇/条带- 索引缓冲区- 缓存友好排序(Forsyth / Tipsify)v[简化]- 边坍缩 + QEM- 生成多级 LOD- 顶点聚类(快速简化)v[压缩]- 量化(uint16 位置/纹理
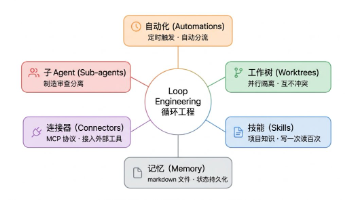
先看Addy原文给的定义。循环工程是指,不再由你亲自去 prompt Agent,而是设计一个系统来替你 prompt。可以把循环理解为一个递归目标:你定义目的,AI 反复迭代直到完成。它大致由五个构建块组成——Claude Code 和 Codex 现在都有了这五块。Loop Engineering 的核心思想是:不要再亲自去 prompt Agent。设计一个系统,让系统替你去 prompt
大模型学习没有捷径,但有科学的路径。2026年的行业竞争,早已不是“会不会大模型”的竞争,而是能不能落地、能不能解决行业问题、能不能持续迭代的竞争。从基础认知到原理吃透,从工程实战到高阶深耕,分层递进、实战优先,既能快速入门变现,也能长期深耕成长,适配零基础入门、职场进阶、技术深耕等所有需求,助力每个人抓住AI产业落地的核心红利。如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学
多维性:支持0维度,1维度(向量,一维数组),2维度(矩阵),以及更高维度的数组同质性:所有元素类型必须一致(即使你定义时不一致,最后也会类型上升统一到一致,这样是为了快速计算),可以通过dtype制定高效性:基于连续的内存块进行存储,支持向量化计算作用:根据传入的形状生成全0数组,快速初始化全0数组调用:np.zeros(传入形状) 例:np.zeros((2,3))zeros_arr = np
到这里为止,三种常见的信号量机制:二值信号量、计数信号量、互斥信号量,我们已经全部学完了。我们可以对 信号量相关的操作 API 做一个简单的总结。三种信号量的创建函数各不相同,但本质上都是创建消息队列,返回消息队列句柄。释放信号量都使用xSemaphoreGive()函数:对于二值信号量而言,释放信号量表示信号状态从无到有,从0到1。对于计数信号量和互斥信号量而言,释放信号量表示资源被释放,可用资
本文详细介绍了在大模型应用中,向量检索的重要性及其工作原理。从基础概念到主流算法(如HNSW、IVF、PQ等),文章全面解析了不同算法的优缺点和适用场景,并通过Faiss和Qdrant的实例演示了如何实现精确和近似的向量检索。此外,还探讨了混合搜索策略、参数调优技巧以及评估检索效果的方法。对于想要提升RAG系统性能的程序员来说,本文提供了宝贵的实践指导和选型建议。
学习
——学习
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 智能体开发者社区
智能体开发者社区

 DAMO开发者矩阵
DAMO开发者矩阵

 AMD开发者中国社区
AMD开发者中国社区















 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区



 DeepSeek技术社区
DeepSeek技术社区