登录社区云,与社区用户共同成长
邀请您加入社区
ubuntu18.04中pycharm报错environment location is not empty时遇到的一些列问题
利用 TensorFlow,通过构建 VGG-16 网络实现猫狗识别。数据集中有 dog 和 cat 2 类图片,每类图片数量各有 1700 张图片。
原文:towardsdatascience.com/tensorflow-transform-ensuring-seamless-data-preparation-in-production-99ffcf49f535?
利用 TensorFlow,通过构建 VGG-16 网络实现猫狗识别。数据集中有 dog 和 cat 2 类图片,每类图片数量各有 1700 张图片。与上一章文章不同的是,之前批次大小用的是 8 ,这次用的是 64。
本文旨在解决深度学习中因数据量不足导致的过拟合问题,将利用 TensorFlow,通过构建 CNN 网络实现猫狗识别。数据集中有 dog 和 cat 2 类图片,每类图片数量各有 300 张图片。Model 层嵌入:利用 GPU 加速,在 Model.fit 时自动生效。Dataset 层映射:在 CPU/数据流水线预处理阶段进行 map 操作。此外,还将说明如何编写 aug_img 并嵌入 pr
摘要: 深度学习项目中动态图与静态图的选择并非简单的二选一,而是研发效率与运行性能的平衡。动态图(如PyTorch)适合科研阶段的快速迭代和复杂模型调试,支持即时修改和灵活控制流;静态图(如TorchScript)则在生产部署中表现优异,通过算子融合、量化等技术提升推理性能。实际应用中,推荐采用混合架构——动态图训练结合静态图推理,并通过标准化接口(如ONNX)实现平滑迁移。不同行业需根据业务需求
迁移学习通过复用在大规模数据集(如ImageNet)上预训练的模型,将其特征提取能力迁移至特定任务,已成为工业界解决图像分类的标准范式。本文将基于预训练的ResNet/MobileNet模型,使用PyTorch与TensorFlow双框架,完整演示从数据预处理、模型微调到训练评估的迁移学习实战流程。迁移学习对预处理有严格要求,输入图像必须与预训练模型原有的归一化方式保持一致(如ImageNet的均
1、提前下载好Anaconda3的Linux版本2、找到下载conda文件的目录,进入该目录下输入以下安装命令,一路回车,直到它要求输入yes,继续回车当看到显示时安装完成3、测试conda是否安装成功,输入以下命令,如果返回版本号则安装成功4、设置环境变量(若上述测试命令显示conda命令可正常使用,忽略以下步骤)注意:这里的填的是conda安装目录所在的bin文件地址5、验证安装是否成功con
TensorLayer是一个基于TensorFlow的深度学习与强化学习库,旨在平衡易用性与灵活性。它提供高层API简化模型搭建,同时保持底层透明性,支持直接修改实现细节。TensorLayer在性能上与原生TensorFlow相当,并提供丰富的中英文文档和示例代码。目前项目已转向多后端框架TensorLayerX,支持TensorFlow、PyTorch等6种框架及多种硬件,建议新用户直接使用T
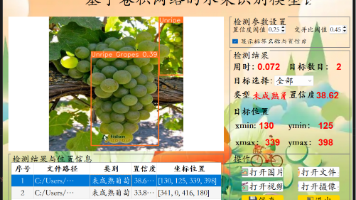
摘要: 针对农产品分拣与新零售商品识别中对水果自动化识别的需求,本研究设计了一款基于卷积神经网络(CNN)的轻量化水果识别模型。传统人工识别效率低、误差率高,而现有CNN模型存在覆盖不足、设备适配性差等问题。本研究通过构建多场景水果图像数据集,结合图像预处理与MobileNetV2迁移学习,优化模型训练流程,实现高精度识别。测试表明,模型在复杂光照与遮挡条件下对25类水果的平均识别准确率达90%以
TensorFlow 是一个,专门为机器学习任务而设计,让开发者能够轻松地构建从简单线性回归到复杂神经网络的各种模型。TensorFlow 是由 Google 开发的开源机器学习框架,用于构建和训练各种机器学习和深度学习模型。和,表示数据以张量的形式在计算图中流动。核心概念。
大模型幻觉并不是简单的"模型犯错",而是概率生成机制、训练数据和应用方式共同导致的问题。本文分析幻觉产生原因,并介绍降低幻觉的实际方法。
本文探讨了深度学习中的分布式训练技术,重点分析了其基本原理、并行策略及主流框架实现。随着模型参数量和数据规模急剧增长,分布式训练已成为解决单卡显存不足和训练耗时的关键技术。文章详细介绍了数据并行、模型并行和流水线并行三种策略,并对比了PyTorch的DistributedDataParallel、TensorFlow的MultiWorkerMirroredStrategy以及Horovod三种实现
TensorFlow Lite Micro(TFLM)是一个开源的机器学习推理框架,专门设计用于在资源极度受限的嵌入式系统上运行深度学习模型。面对嵌入式系统严苛的资源约束(通常仅有几十KB的内存)和高度碎片化的硬件生态,TFLM通过基于解释器的独特架构、静态内存分配策略和模块化算子设计,在保持跨平台灵活性的同时实现了极低的运行时开销。本文系统阐述TFLM的设计动机、核心架构、内存管理机制、性能优化
摘要: AI领域框架格局正被大模型重塑,PyTorch与TensorFlow的定位发生显著变化。PyTorch凭借Transformer生态(如FlashAttention)主导大模型研究(占论文60%),而TensorFlow仍在大规模稀疏推荐场景(如TB级Embedding)保持优势。两者差异体现在:TensorFlow擅长分布式稀疏计算,PyTorch专注动态图与稠密模型优化。生成式推荐等新
引言:一场关于“更好”的辩论在深度学习的开发者社区里,有一个经久不衰的话题:PyTorch和TensorFlow,到底哪个更好?这个问题的答案往往取决于提问者的背景——如果你问一位高校的研究员,他大概率会回答“PyTorch”;如果你问一位负责大规模模型部署的工程师,答案则可能是“TensorFlow”。这场争论本身隐含着一种误解:将两个框架置于非此即彼的对立位置。事实上,这并非一道“孰优孰劣”的
【代码】TensorFlow Object Detection API。
111111
使用下载训练集和测试集,包含大量手写数字图片及其真实标签;将图片数据按批次打包(如每批 64 张);在 GPU 中构建神经网络模型;将打包好的训练数据传入 GPU 进行模型训练;使用测试集数据验证模型效果,并与真实值对比,计算准确率。
查看tensorflow对应版本的网址。
# 总结通过本文,我们从原理上理解了 Codex 皮肤系统如何通过 CSS 注入实现深度定制,并用 Python 生成了 Dario 风格的背景图,最后构建了一个完整的 Codex 扩展。记住,好的皮肤设计不仅要好看,还要考虑代码可读性和性能平衡,这才是技术美学的精髓。而“换皮肤”不仅是外观美化的过程,更涉及到 Codex 的主题系统、CSS 注入机制以及扩展的生命周期管理。## 构建 Codex
Deepseek本地部署,LM部署deepseek详细极简步骤教程!!手把手带部署!!不再被服务器繁忙所困扰,速度取决于自己的电脑!!超简单deepseek本地部署教学!
"No Module"错误意味着Python无法找到所需的模块或包。该模块或包未安装该模块或包未包含在Python环境中模块或包的名称不正确例如,如果您尝试导入一个名为"numpy"的模块,但您的Python环境中并没有安装这个模块,那么Python就会引发"No Module"错误。本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角
是的,可以使用 Anaconda 安装 chatgpt。你可以在 Anaconda 的命令行中输入 conda install chatgpt 来安装 chatgpt。不过,在安装之前,你需要确保你已经安装了 Anaconda 并且你的电脑已经连接到了互联网。...
选择阿里云的源进行下载。
CSS伪类是用来添加一些选择器的特殊效果。
摘要:tf.keras.losses.SparseCategoricalCrossentropy是用于单标签多分类任务的损失函数,其特点是直接使用整数标签(如0/1/2)而无需转为one-hot编码,节省内存且操作简便。该函数通过评估正确类别的预测置信度来打分:置信度越高损失值越低。关键参数from_logits建议设为True以处理原始模型输出。与CategoricalCrossentropy的
做 AI 智能体总卡壳?要么写代码写到头秃,要么用现成工具改不了逻辑,要么搭出来的智能体响应慢、报错多、根本没法落地用?作为 0 代码入门的新手,你是不是也想:1、 不用啃 Python/Java,快速搭出能实际用的智能体2、 兼顾高可用(稳定不崩)+ 自定义(贴合自己的业务)3、7天就能看到成品,不是学半年还摸不着门?别慌!我亲测用 Dify+Coze 组合拳,纯可视化操作,7 天从 0 到 1
本文介绍了一个基于Python+Django的智能音乐推荐系统。系统采用前后端分离架构,后端使用Django框架,前端通过HTML+Echarts实现数据可视化。核心功能包括音乐播放、智能推荐、歌单管理、评论评分等12个模块,并集成了Requests爬虫定时更新曲库。推荐算法采用TensorFlow深度学习框架结合协同过滤技术,根据用户行为生成个性化推荐。系统还提供丰富的数据分析功能,如音乐类型分
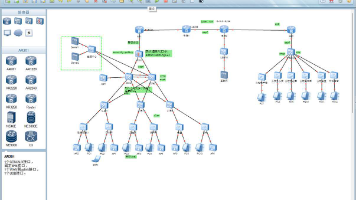
本课题聚焦该大学南北校区校园网建设的实际需求,明确跨校区安全互联、网络区域分段、内网与DMZ区隔离、总校区无线全覆盖等核心需求,完成双校区校园网的整体规划与详细设计。在架构上采用核心层、汇聚层、接入层三层网络架构,南北校区通过互联网搭建IPSecVPN加密隧道实现互联,总校区部署主备核心交换机构建双机热备架构,利用防火墙划分Trust、DMZ、Untrust安全区域;在设备配置上基于华为eNSP模
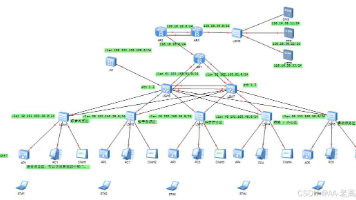
在高校数字化与智慧图书馆建设背景下,本研究针对传统图书馆WLAN存在的覆盖盲区、带宽分配不均、安全管控不足等问题,提出基于华为eNSP仿真的WLAN网络优化方案。通过分析图书馆各功能区(综合阅览区、数字资源区等)的网络需求,采用核心层-接入层二级架构,部署VLAN隔离、VRRP冗余、ACL访问控制及WPA2-PSK加密等技术,实现全馆无线覆盖、校内/访客网络隔离及带宽差异化保障。仿真测试验证了跨部
TensorFlow Lite Model Maker由于依赖库与新版本的Python不兼容的问题,我们将方案转为用 TensorFlow/Keras 训练一个花卉图片分类模型,并把训练好的模型转换为 TensorFlow Lite 的.tflite文件。它不依赖,因此可以避开scann、旧版 TensorFlow、旧版 Python 之间常见的安装冲突。整体流程是:下载/读取图片数据集 -> 构
本文探讨了4个AI Agent协作系统中责任链断裂的问题。当用户反馈头像点击无反应时,发现开发、测试、运维各环节都报告"已完成",但实际代码未改动。分析表明,每个Agent只验证自己关心的部分(如页面能否打开),而忽略核心功能验证(如点击事件)。根源在于缺乏"交棒验证"机制和明确的源码级验收标准。解决方案包括:强制下一环节验证上一环节的实际产出、在验收标准中添加grep验证命令、区分功能性和样式变
本文系统介绍了Python在量化投资领域的三大核心技术:1)使用Pandas处理金融时间序列数据,包括跨时区转换和缺失值填充;2)利用Dask实现千万级高频数据的并行计算和分布式机器学习;3)构建标准化的机器学习工作流,集成金融专用评估指标和风险控制层。文章强调通过Pandas、Dask和TensorFlow的深度集成,结合MLOps流程,可构建高效稳定的量化系统。实践建议从A股分钟数据入手,逐步
本文探讨了量化交易中的三大进阶技术应用:1)挖掘TA-Lib隐藏的小波变换功能实现精准趋势转折点检测,测试显示对沪深300关键转折点识别准确率达82%;2)利用TensorFlow Probability构建贝叶斯神经网络模型,通过概率化输出提升策略稳健性,夏普比率达1.9;3)采用Cython加速高频信号计算,使RSI指标处理速度提升14倍至0.9秒/百万数据。文章强调工具链整合与合规风险控制,
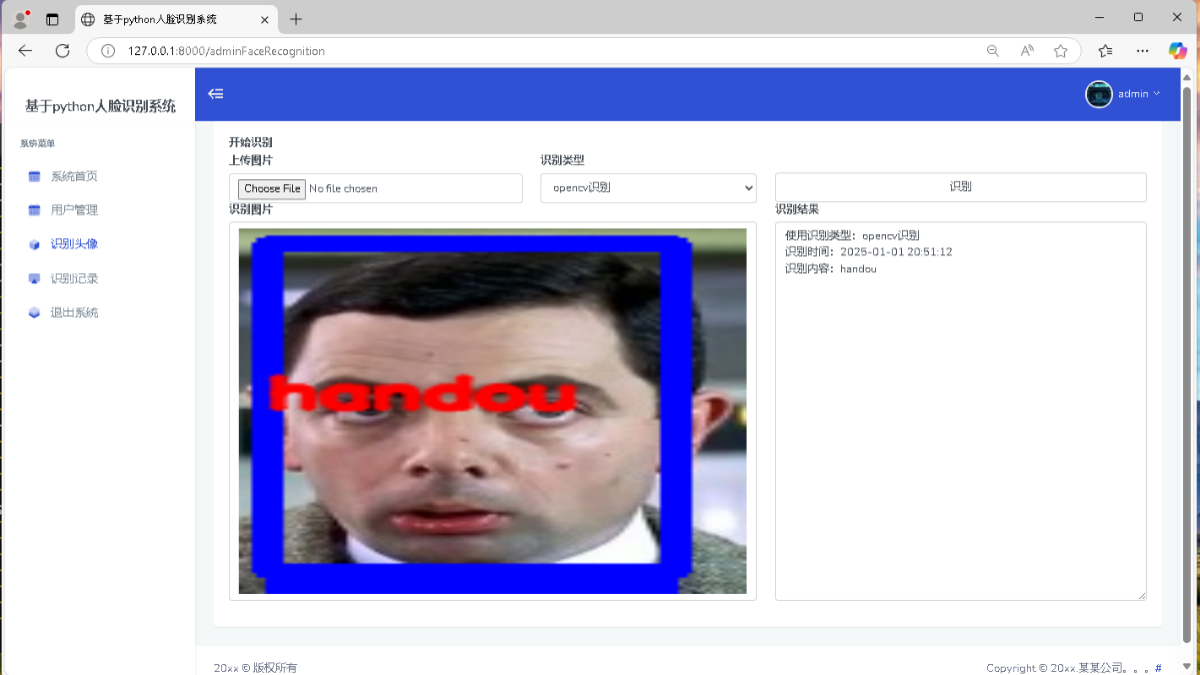
人脸识别的项目很常见了,有调用第三方接口的,还有可以自行收集人脸图片然后构造模型进行训练。这个项目demo客户来找我帮忙修改一下,客户使用的是tensorflow进行人脸识别训练,准确率很低,我看了一下神经网络和图片处理有很多问题。最后经过和客户商量考虑到客户米不足,所以我干脆使用opencv中face进行人脸识别,以及登录识别哪里也是因为客户米不足没法帮他做成网页调用摄像头的方式,我直接使用最简
分类报告显示,“正常流量”“DDoS_UDP”“DDoS_ICMP”“MITM”的精确率和召回率均为1.00,而“SQL注入”(精确率0.62)、“XSS攻击”(精确率0.64)、“指纹识别攻击”(召回率0.27)的表现相对较弱——这是因为这些攻击的流量特征更细微(如SQL注入的恶意语句被加密、XSS攻击的脚本片段短)。混淆矩阵(图10)和归一化混淆矩阵(图11)进一步显示,误判主要集中在“注入攻
tensorflow
——tensorflow
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 深开鸿 技术专区
深开鸿 技术专区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 AI编程社区
AI编程社区



 AI Agent技术社区
AI Agent技术社区










 乐奇 Rokid 开放社区
乐奇 Rokid 开放社区












 DAMO开发者矩阵
DAMO开发者矩阵
 AMD开发者中国社区
AMD开发者中国社区

 智能体开发者社区
智能体开发者社区