登录社区云,与社区用户共同成长
邀请您加入社区
但上线一周后,用户反馈 Agent "有时候死循环""经常选错工具""10次里有3次任务没完成"。普通 LLM 评测只关心"回答好不好"。Agent 评测要关心"事有没有办成"——这中间多了工具调用、多步规划、错误恢复、SubAgent 协作。由于 Agent 的输出是非确定性的(不同路径可能都对),LLM-as-Judge 是做 Agent 评测最实用的方式。这是 Agent 评测的北极星指标—
人工智能时代的到来正在重塑文明的标准体系。文章指出,文明本质上是建立在标准体系之上的,而AI技术既挑战着传统标准,又为新标准的制定提供了技术手段。在AI时代构建标准需要遵循以人为本、前瞻性和全球性原则,强调标准与文明的辩证统一关系。文章认为,AI时代的文明走向取决于人类如何构建和执行标准,呼吁重视标准建设,以实现可持续发展。
人类需要培养持续学习的能力,特别是关注AI难以替代的领域:批判性思维、复杂问题解决、跨学科整合等。在高效自动化的世界里,人类需要重新定义"生产力"的含义,避免被机器节奏完全支配。保持工作与生活的平衡,关注心理健康,培养兴趣爱好,这些都将成为重要的生存智慧。这包括职业转型的勇气、对新技术的开放态度,以及在不断变化的环境中保持心理韧性。最成功的人类将是那些能够与AI协同工作,同时保持和发扬人类独特品质
摘要:Gemini 3.0在多模态AI领域表现突出,能高效完成代码生成、界面设计、文档解析等复杂任务。用户可通过DeepSider浏览器插件便捷使用该模型,该插件还集成了GPT-5、Claude等主流AI工具,支持代码生成、科研绘图、视频制作等功能,中文适配良好且无需特殊网络。实测显示Gemini 3.0仅用2分钟即可生成完整MacOS系统模拟,其视觉理解与文档处理能力显著提升,是提升工作效率的实
通俗概念长期记忆是 Agent 用来存储海量、非结构化历史信息的仓库。当你告诉 Agent “我叫张三,我对海鲜过敏”时,Agent 不会把这句话永远放在每次聊天的 Prompt 里(那太贵了),而是把它翻译成一串数字(向量),存进它的大脑深处(向量数据库)。过了几个月,当你问它“今晚去吃海鲜大排档怎么样?”时,Agent 会瞬间在茫茫记忆海中,把“张三对海鲜过敏”这条记忆捞出来,并拒绝你的提议。
文章摘要: AI Agent 长期对话面临记忆管理的核心挑战:全量记忆成本过高,滑动窗口又会导致关键信息丢失。本文解析了会话摘要与压缩(Memory Compression)这一折中方案,通过将长对话提炼为精华摘要来平衡成本与记忆保留。重点介绍两种主流压缩机制:1)滚动摘要(Rolling Summary)实时提炼对话核心;2)实体抽取(Entity Extraction)结构化存储关键信息。文章
具身智能产业正经历从实验室验证到规模化部署的关键跃迁。根据国家标委会"标准周"期间公布的信息,WG7数据工作组于7月15日至17日在绍兴上虞正式成立,标志着具身智能数据标准化工作进入国家级推进阶段。这一工作组的成立背景,是行业面临的数据格式碎片化、接口协议不统一、测试评价体系缺失等技术挑战——当具身智能年产量从数万台向十万台级别攀升时,数据基础设施的标准化已不再是可选项,而是产业化的必要条件。
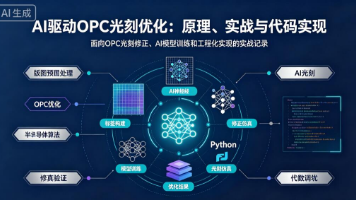
本文探讨了人工智能在光刻工艺邻近效应校正(OPC)中的应用。随着半导体工艺节点推进至28nm以下,传统规则OPC面临计算复杂度爆炸、维护成本高等问题。文章详细对比了规则OPC与AI-OPC的技术差异,提出通过神经网络建立版图特征与线宽误差的映射关系,实现快速精确的校正预测。实战案例显示,AI-OPC将7nm工艺关键区域的线宽误差从3nm降至0.5nm,良率提升28%,同时校正时间缩短89%。文章还
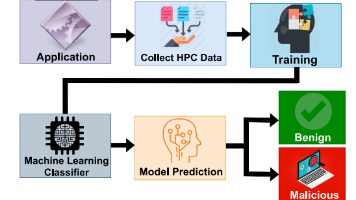
摘要 本文针对物联网设备面临的安全威胁(恶意软件和微架构攻击),提出了一种基于硬件性能计数器(HPC)的可解释机器学习入侵检测框架HPCDR。传统反病毒软件存在高开销和低鲁棒性问题,而现有基于HPC的检测方法缺乏决策可解释性。HPCDR通过双回归模型定位程序中最恶意的瞬态窗口,实现了透明化的入侵检测。实验评估表明,该框架能准确识别五种微架构攻击(Rowhammer、Flush+Flush、Spec
具身智能论文伴读 | 第一期 | 精读 03|Attention Is All You Need · Background 本文聚焦Transformer论文的背景章节,揭示其"圈地"策略: 问题定位:延续引言思路,围绕"减少串行计算"这一核心问题展开讨论。 竞争对手分析: 第一拨(卷积家族):肯定CNN模型(Extended Neural GPU等)的并行能力,但指出其远距离关联成本随距离增长(
这篇文章摘要(146字): 龙魂系统DNA服务器端验证接口v2.0是一个部署在华为云鲲鹏服务器上的安全验证系统。核心功能包括:基于HMAC的请求签名验证、设备指纹哈希计算、结构化日志记录以及天干地支时间戳机制。系统采用环境变量配置敏感参数,实现自动日志滚动和请求限流,支持最大4KB请求体。通过SHA256哈希验证管理员密钥,并内置传统干支历法用于时间校验。所有DNA注册数据以JSON格式存储,严格
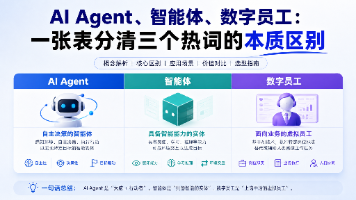
本文厘清了当前企业AI应用中三个易混淆的概念:AI Agent、智能体和数字员工。AI Agent是底层技术架构,强调自主感知与决策能力;智能体是AI Agent在对话场景的实现,侧重知识问答;数字员工则是任务执行导向的实现,能闭环完成跨系统操作。三者核心区别在于:AI Agent是"会思考的脑子",智能体是"会说话的嘴",数字员工是"能干活的人"。文章通过对比表、架构图和流程图,帮助技术决策者建
一个让 AI 工程师崩溃的场景:你的 Agent 面对一个陌生任务,世界模型先"想象"了一下——"接下来应该看到 X"——结果预测跟现实差了一截,Agent 就按这个**错误想象**采取了行动,**越努力越糟糕**。
暑假一到,很多人又开始蠢蠢欲动:开新坑、囤存稿、冲全勤,顺便看看能不能靠写文赚点外快。我这半年也没闲着。为了攒一本新书的存稿,天天关着门憋大纲、磨人设、改开篇。结果脑子是热的,文档是空的,手放在键盘上半天,一个字都敲不出来。后来我开始试各种 AI 写小说工具。市面上打着“网文神器”的软件,我前前后后测了几十款。试错成本没少花,废稿也攒了几十万字。最烦的是,有些小说软件看着很聪明,一写正文就露馅:情
这两年写网文,同行之间是真的卷。以前日更六千就算勤快,现在日更一万都快成了基础要求。后台也常有人问我:“现在写小说是不是都开始用 AI 了?有些新人一天两万字,看起来轻轻松松。点进去一看,剧情也爽,节奏也快,但总觉得少了点自己的味道,像是从模板里倒出来的。”这个感觉我很懂。不用 AI小说工具,更新速度可能跟不上;用了 AI写小说,又怕越写越不像自己。尤其是写久了的人,最怕的不是工具不好用,而是自己
每次在我的写作干货交流群里,或者平时给大家做长图文内容拆解的时候,总有新手朋友跑来问我关于AI辅助写作的问题。大家的痛点出奇的一致:“写到中期剧情疯狂注水,有没有能帮我梳理逻辑的小说软件生成器?”“卡文的时候不知道怎么推进,去哪里找合适小说的素材?”“大纲怎么写才不会崩?有没有靠谱的大纲模板?”这些坑,我在做多平台连载和内容矩阵分发的时候,几乎全都踩过一遍。日更的压力一旦上来,纯靠脑力硬挤真的很容
现在的网文圈确实卷更新。每天至少得雷打不动地敲出四千到六千字,才能保住平台的全勤奖。遇上剧情卡壳不知怎么往下推进,熬大夜也不一定能写出来,那绝对是一种折磨。不少新手一急,就跑去报那种动辄大几千的写作培训班,结果被割了一波又一波韭菜。其实AI时代,想要写小说赚钱,破局的关键其实在于怎么用好手头的生产力工具。这几天我花了大量时间,把市面上呼声最高的10款工具彻底摸了个透。今天就给大家交个底,按场景和功
我这两年大大小小写了几十万字,平时很多读者在后台私信我,说新人写小说,脑子里倒是不缺点子,可一坐到键盘前手速根本跟不上,硬生生卡文卡到崩溃,拿个全勤都很难。为了破局,很多朋友咬牙花大几千去报那种号称能包过稿的写作班。听句劝,真没必要去当这个韭菜。AI时代,把报班的钱省下来,用高效工具来帮忙上,靠多更字数稳拿网文全勤,才是实打实的聪明账。
经常有同频的作者朋友在后台诉苦,说看别人写小说赚钱眼红,自己真上手了却卡文卡到怀疑人生,全勤条件看着不算苛刻,但普通人平时上班上学事情也不少,写想小说兼职拿个网文全勤,确实不算简单。其实现在卷更新量,纯靠手打拼不过机器的。找对工具把思路理顺,其他的不说,拿到全勤可以保证。 今天我就把圈内作者都在用的
Manus使关节角度、指尖测量和手部骨骼数据都可用于控制管道,对于BrainCo来说,这在人类手部运动和Revo 3控制之间创建了一个实用的接口。拇指需要不同的重定向方法,因为MANUS thumb数据的节点结构并不直接对应于Revo 3的拇指。控制这种水平的铰接需要的不仅仅是检测操作者的手是张开的还是合拢的。使用时MANUS Pro Haptic 手套还能将Revo 3的触觉信号转换为操作员相应
高水平学术论文写作的“破局”之道暨 AI 赋能下前沿选题、智能写作、科研可视化、精准选刊与投稿、审稿博弈策略及 CNS 顶刊跃迁进阶全链路实践把论文发表从"苦写"变成"系统工程"。✅ 四链对齐法:问题→证据→图表→结论,闭环叙事让审稿人秒懂✅ AI智能体赋能:前沿雷达自动追踪、研究空白智能识别、期刊风格定制润色✅ 顶刊叙事密码:倒三角引言×正三角讨论,从"写清楚"到"让人停不下来"✅ CNS跃迁路
很多想靠写小说赚钱的新手,都会陷入一个死循环:没灵感卡文——手速太慢断更——心态崩溃跑路。其实AI时代,普通人写小说想要破局,关键就在于AI写小说软件。找对了一款懂行的辅助工具,那就是一笔极其划算的生产力投资。为了帮大家省掉试错的时间,我把市面上主流的10款AI写网文工具彻底盘了一遍,整理出这份实打实的测评清单,按照“适用场景—定位—实操体验—避坑指南”测评,不管你是需要大纲推演,还是找免费ai写
说实话,这两年眼看着圈子里那些触手怪靠着AI日更两万字,我心里也是有点发慌的。AI会不会砸了咱们作者的饭碗?但焦虑归焦虑,饭还得吃。有了新变化就得适应新变化,我花时间把市面上的ai写网文工具轮番试验了一遍。我发现,大家写不出东西,真不是脑洞不够,而是被工具拖累,或者长时间卡文把写作手感给磨没了。别把AI当成一键暴富的神器,把它当成你的免费打工人。今天给小伙伴们盘点10款实测能用的AI工具,带你找回
这半个月,我其实挺焦虑的。看着各大厂发大模型跟发朋友圈一样频繁,我有时候会盯着屏幕发呆:ai写网文软件一分钟能吐出两万字连贯的网文,咱们这些靠码字熬出头的人,出路到底在哪?说实话,纯靠手敲在这个时代已经拼不过效率了。与其闭门造车被淘汰,不如把这些ai驯化成你的工具。我熬夜把市面上热门的10款AI写作软件扒了个底朝天,今天只聊实操,看看怎么借它们的力,练咱们自己的手感。
装不上:看 02。能装但不会用:看 03。能聊但回答失败:看 04。平台不回复:看 05。想让它固定做一件事:看 06。想让它记住长期信息:看 07。想拆多个助手:看 08。想放服务器:看 09。担心安全和滥用:看 10。已经报错了:看 11。如果你只记住一句话:先把一条链路跑稳,再加下一层能力。OpenClaw 的学习顺序不是“功能越多越好”,而是每一层都知道怎么启动、怎么观察、怎么暂停、怎么恢
近两年AI写小说工具井喷,对我们这些靠写小说吃饭的人来说,既是红利也是挑战。摸索了两个月、实测了几十款工具后,我发现还是红利大于挑战的。AI取代不了我们的写作手感,但我们可以用AI赋能我们写小说。今天掏心窝子分享我筛选出的10款AI工具,按照 定位-功能-实操-评价 统一梳理,不吹不黑,做了一次深扒,无论你是卡在大纲,还是缺少小说的素材,这篇测评应该能帮你省下不少试错时间。
Alertmanager告警后对接AI模型,处理完成后发送到飞书群fill:#333;important;important;fill:none;color:#333;color:#333;important;fill:none;fill:#333;height:1em;处理返回中间层hermesAI模型飞书应用机器人飞书群。
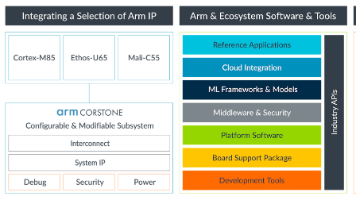
本文是Arm Ethos-U65学习笔记第五篇,聚焦于YOLOv8n目标检测示例的硬件验证阶段。文章详细介绍了将Vela编译生成的命令流导入芯片仿真环境执行推理验证的完整流程。整个过程不仅适用于芯片仿真验证,对裸机环境下的软件开发也具有参考价值,为嵌入式AI加速器部署提供了实用指导。
摘要 随着生成式AI的普及,传统搜索引擎流量预计到2026年将下降25%,AI驱动的搜索推荐成为B2B决策新入口。SaaS行业面临AI搜索挑战,如信息碎片化、品牌提及率低及转化断层。生成式引擎优化(GEO)通过结构化数据、语义优化及E-E-A-T原则(专业性、权威性等),帮助SaaS企业在豆包、Kimi等AI平台提升品牌推荐率。百搜GEO作为国内代表服务商,通过多平台覆盖、信源建设及合规机制,助力
2026年智能社会与可持续发展国际学术会议(SSSD2026)将于8月28-30日在中国武汉召开,由武昌理工学院和文华学院联合主办。会议聚焦人工智能、智慧城市、可持续技术等跨学科领域,涵盖智能系统、绿色计算、数字治理等主题。投稿论文经同行评审后,录用文章将由ACM ICPS出版并提交EI和Scopus检索。投稿需保证原创性,组委会将进行学术诚信检测。
第二届人工智能赋能教育国际研讨会(AIEE2026)将于2026年8月28-30日在青岛召开。会议聚焦人工智能与教育融合,设立人机协同教学、AI教育、循证教育三大专题论坛,涵盖智能教学、个性化学习、教育数据挖掘等20余个前沿议题。录用论文将由ACM出版社出版,提交EI/Scopus检索。优秀论文可推荐至ESCI期刊《Frontiers in Education》(影响因子1.9)专题发表。会议提供
钛虎机器人在WAIC2026发布钛极A6力控协作臂,瞄准工业自动化向精密作业升级的需求。该产品具备三大核心优势:高精度扭矩传感系统实现柔性力控、七自由度仿生构型增强复杂空间适应性、轻量化设计提升部署维护效率,针对精密装配、曲面打磨、人机协作等传统机械臂难以胜任的场景。作为集成服务商,我们重点关注其能否通过"感知-控制"闭环能力降低精密工位的改造难度,缩短调试周期,适配小批量柔性
复旦大学团队建立跨物种神经元树突比较框架,揭示人脑树突局部更紧凑的独特结构 复旦大学脑智研究院彭汉川团队与北京天坛医院合作,在《自然·神经科学》发表研究,通过建立人鼠对应脑区框架,系统比较了2,363个人类和16,011个小鼠皮层神经元的三维树突结构。研究发现:1)人类神经元树突并非简单放大,而是在控制整体尺度后表现出更高分支频率和更短间隔的紧凑结构;2)人类脑叶间树突差异主要体现为空间组织方式不
本文介绍了如何部署本地大模型并搭建个人知识库,详细讲解了使用Ollama运行本地大模型、通过Open WebUI实现交互式对话,以及利用RAG(检索增强生成)技术构建本地化知识库的方法。文章涵盖Ollama安装、模型下载、Docker部署Open WebUI等步骤,并解释了RAG的核心概念和工作流程,包括文档加载、文本分割、存储、检索和生成五个关键环节。通过AnythingLLM工具,读者可以构建
机器人商用落地的核心挑战在于导航系统的场景适应性。主流SLAM方案(纯激光、纯视觉及多传感器融合)各有局限,测试表明多传感器融合是唯一能实现全场景稳定运行的方案。实践中最常见三大难题:动态环境定位漂移(需语义分割+IMU辅助)、玻璃幕墙失效(视觉辅助+人工标注)、长走廊尺度漂移(UWB/二维码校正)。工程落地不是追求算法先进性,而是在成本、稳定性和易维护性之间寻找平衡,成熟可靠的工程化方案比实验室
机器学习
——机器学习
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 智能体开发者社区
智能体开发者社区
 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区


 DAMO开发者矩阵
DAMO开发者矩阵

 AI编程社区
AI编程社区







 鲲鹏昇腾开发者社区
鲲鹏昇腾开发者社区

 AI工具分享
AI工具分享
 AtomGit AI 社区
AtomGit AI 社区



 openvela
openvela




 脑启社区
脑启社区



