登录社区云,与社区用户共同成长
邀请您加入社区
本文摘要:乳腺癌作为女性高发恶性肿瘤,术后随访管理对降低复发风险至关重要。针对传统随访模式存在的效率低、数据分散等问题,研究基于Java+SpringBoot+MySQL技术栈开发智能化乳腺癌患者随访系统。系统采用模块化设计,集成患者档案管理、复查提醒、风险预警等功能,支持多终端数据同步。通过人工智能算法分析历史数据预测复发概率,并利用移动端实现远程随访。测试表明,系统显著提升随访率至92%,平均
Dify 之前有介绍过。
+[,.;。utils.py是一个高效的文本分割工具,它提供了多种文本分割方法,包括按字符、按句子、按特定分隔符等。通过这种方式,我们可以更好地理解文本的结构和上下文,从而提高NLP任务的准确性。希望这篇博客能够帮助你全面理解utils.py的工作原理及实际应用。
基于Spring+SpringMVC+MyBatis+easyUI的后台管理系统是一个功能完善、技术先进的企业级后台管理解决方案,专为毕业设计、课程设计及实际项目开发提供高质量的参考资源。该系统采用Java作为主要编程语言,结合Spring Framework、Spring MVC、MyBatis、Redis等主流技术栈,实现了高效、稳定、可扩展的后台管理功能。系统核心功能包括用户管理、角色权限控
*** ComfyUI 节点基类(最小功能)*/@Data/** 节点ID(唯一) *//** 节点类型(prompt/llm/in_output) *//** 节点名称 *//** 节点位置(画布坐标) *//** 节点参数 *//** 输入连接(key:输入端口,value:源节点ID+输出端口) *//** 输出连接(key:输出端口,value:目标节点ID+输入端口) */
其他版本理论上也可以。2.IDE环境:IDEA,Eclipse,Myeclipse都可以。3.tomcat环境:Tomcat 7.x,8.x,9.x版本均可 4.硬件环境:windows 7/8/10 1G内存以上;管理员角色包含以下功能: 管理员登录,菜单管理,角色管理,修改密码,用户管理,学院班级管理,日志列表管理, 实验室管理,设备管理,设备申请管理,查看我的设备申请,实验室申请管理,查看我
1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。2.IDE环境:IDEA,Eclipse,Myeclipse都可以。3.tomcat环境:Tomcat 7.x,8.x,9.x版本均可 4.硬件环境:windows 7/8/10 1G内存以上;后台主要功能包括: 系统设置:菜单管理、角色管理、修改密码;用户管理:用户列表;租赁管理:租赁列表;前台主要功能包括: 普通用户的注册、
3.tomcat环境:Tomcat 7.x,8.x,9.x版本均可 4.硬件环境:windows 7/8/10 1G内存以上;若包含,则为maven项目,否则为非maven项目6.数据库:MySql 5.7/8.0等版本均可;主要包含以下功能: 营销管理:营销机会管理、客户开发计划;客户管理:客户信息管理、客户流失管理;服务管理:服务创建、服务分配、服务处理、服务反馈、服务归档;统计报表:客户贡献
4 Mybati数据库DAO层采用的是Mapper代理开发方法,输入映射采用的是POJO包装类型实现,输出映射采用了resultMap类型,实现了数据库多对一映射。后台采用技术: SSM框架(SpringMVC + Spring + Mybatis) 前台采用技术: div + css + easyui框架。基于javaweb和mysql的ssm公司员工管理系统(java+ssm+jsp+easy
基于javaweb和mysql的ssm茶叶售卖商城系统(java+ssm+jsp+easyui+mysql)管理员具有登录、管理用户信息、管理商品信息、管理商品活动信息、管理订单信息、管理用户评论信息的等等功能。运行环境:eclipse/IDEA + MySQL5.7 + Tomcat8.5 + JDK1.8。基于javaweb的SSM茶叶售卖商城系统(java+ssm+jsp+easyui+my
本文介绍了作者开发的两套独创设计:用宝ORM和UserBaoDataGrid.js模板渲染引擎。用宝ORM实现了轻量级、零依赖、跨语言(C#/Java/ArkTS)的ORM设计,支持XML配置动态实体和手写SQL;UserBaoDataGrid.js则采用纯HTML模板驱动的方式,无需学习特定框架语法即可实现主子表无限嵌套展示。两套设计都强调简单可控、降低学习成本,通过对比表展示了与主流框架的核心
本文介绍了一个基于SpringBoot 2.7+EasyUI 1.11.5+MyBatis-Plus的IT工单管理系统开发全过程。系统针对现场交付团队需求设计,支持工单与项目/合同/成员关联、自动状态联动、Excel导入导出等功能。采用前后端不分离架构,核心模块包括工单管理、项目管理、合同管理等8张表。文章详细介绍了技术选型理由、系统功能架构、数据库设计以及开发过程中遇到的6个技术难点及解决方案。
文章摘要 本章系统介绍了自然语言处理(NLP)的核心技术和发展脉络。首先阐述了文本预处理流程,包括清洗、分词、去除停用词等关键步骤,并提供了中英文处理的代码实现。重点讲解了词嵌入技术(Word2Vec、GloVe、FastText)的演进,以及从上下文无关表示到上下文相关表示(如BERT)的转变。同时介绍了语言模型从N-gram到神经网络的进化过程,深入分析了Seq2Seq、注意力机制和预训练-微
Claude 是人工智能领域中一款具有重要影响力的语言模型。其研发目的在于提供高效、准确、智能的自然语言交互服务。它的范围涵盖了文本生成、知识问答、对话交互等多个自然语言处理领域。通过使用 Claude,用户可以获得对各种问题的解答、生成高质量的文本内容,如文章、故事、代码等。本文将首先介绍 Claude 的核心概念和相关联系,包括其架构和工作原理。然后详细讲解 Claude 的核心算法原理和具体
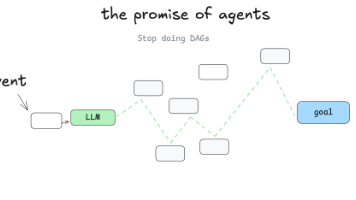
现在我们从软件开发的视角(也就是编程的视角)来重新思考一下「自主性」这个问题。
在本文中,我们探讨了 LoRA 微调方法,并以 StarCoder 模型的微调为例介绍了实践过程。通过实践过程的经验来为大家展示一些细节及需要注意的点,希望大家也能通过这种低资源高效微调方法微调出符合自己需求的模型。。
本项目提供完整的Java Web开发源代码及配套文档,包含前后端代码、SQL脚本和开题报告等技术资料。系统采用SSM+SpringBoot+Vue框架开发,使用MySQL数据库,支持JSP页面展示。项目提供运行演示视频、远程调试服务和开发环境配置指南(IDEA/Eclipse)。包含项目截图展示,需要源码和文档的同学可通过文末联系方式领取。技术栈涵盖Java、Vue、MySQL等主流技术。
本项目提供完整的Java Web开发学习资源,包含基于SSM+SpringBoot+Vue的全套源代码、SQL脚本及配套文档(论文+PPT+开题报告)。技术栈涵盖Java、SSM框架、Vue.js、JSP和MySQL数据库,支持IDEA/Eclipse开发环境。项目提供运行演示视频、系统截图及远程调试服务,适合计算机专业学生毕业设计参考。需要获取资料的同学可联系文末联系方式领取源代码和文档资料包。
本项目提供完整的Java Web开发实战资源包,包含基于SSM+SpringBoot+Vue的全套源代码、SQL数据库脚本及配套文档(论文+PPT+开题报告)。技术栈涵盖Java、MySQL、JSP及主流前后端框架,支持IDEA/Eclipse开发环境,附赠远程调试服务。项目包含演示视频、运行截图和详细技术说明,适合学习企业级应用开发。需要完整资料包的同学可联系文末客服获取源代码和技术文档。
项目提供完整源代码(前后端+SQL脚本)、配套文档(论文+PPT+开题报告)及远程调试服务。技术栈包括Java、SSM、SpringBoot、Vue、JSP及MySQL,支持IDEA/Eclipse开发环境。包含项目演示视频和运行截图,有需要者可联系文末名片获取资料。
该项目提供完整的Java Web开发资源包,包含前后端源代码、SQL脚本和配套文档(论文+PPT+开题报告)。采用SSM+SpringBoot+Vue技术栈,使用MySQL数据库,支持IDEA/Eclipse开发环境。配套提供项目演示视频、运行截图和远程调试服务。需要完整资料的同学可联系文末联系方式获取源代码和文档。
本资源提供基于Java技术的完整项目资料包,包含前后端源代码、SQL脚本及配套文档(论文+PPT+开题报告)。项目采用SSM+SpringBoot+Vue框架开发,使用MySQL数据库,支持IDEA/Eclipse开发环境,并附赠运行演示视频和远程调试服务。需要完整资料的同学可通过文末联系方式获取,包含项目截图展示和技术方案说明(JSP页面等)。
该项目提供完整的Java Web开发学习资源,包含前后端源代码、SQL脚本及配套文档(论文+PPT+开题报告)。采用主流技术栈:Java+SSM+SpringBoot+Vue+JSP+MySQL,支持IDEA/Eclipse开发环境。附赠项目演示视频、运行截图及远程调试服务,适合计算机专业学生课程设计参考。需要完整资料的同学可通过文末联系方式获取源代码和文档包。(98字)
摘要:本项目提供完整的Java前后端开发资源包,包含基于SSM+SpringBoot+Vue的全套源代码、SQL脚本、配套文档(论文+PPT+开题报告)及远程调试支持。采用JSP+MySQL技术栈,支持IDEA/Eclipse开发环境。提供项目演示视频、运行截图和详细技术说明。需要资料者可联系文末获取源代码及文档。(99字)
本文介绍了基于Java技术的完整项目资源包,包含前后端源代码、SQL脚本及配套文档(论文+PPT+开题报告)。项目采用SSM+SpringBoot+Vue框架,使用JSP页面和MySQL数据库,支持IDEA/Eclipse开发环境。提供远程调试服务,附项目演示视频和运行截图。开发者可获取完整资料包,包括远程控屏包,具体领取方式见文末联系方式。
【项目资源领取】提供基于Java+SSM+SpringBoot+Vue的完整项目资源包,包含前后端源代码、SQL脚本、配套文档(论文+PPT+开题报告)及远程调试服务。采用Mysql数据库,支持IDEA/Eclipse开发环境,含JSP页面示例。需要源码和资料的同学可添加文末联系方式获取,附项目演示视频和截图预览。(98字)
【项目资源领取通知】提供基于Java+SSM+SpringBoot+Vue的完整项目源码(含前后端代码、SQL脚本),配套毕业设计文档(论文+PPT+开题报告)。技术栈包含JSP、MySQL,支持IDEA/Eclipse开发环境,另附远程调试控屏包。需要获取资源的同学请添加文末联系方式,可查看项目演示视频及效果截图。(注:该摘要严格遵守原文信息,未添加任何主观内容)
本文提供完整的Java项目资料包,包含前后端源代码、SQL脚本、配套文档(论文+PPT+开题报告)及远程调试服务。项目采用Java+SSM+SpringBoot+Vue技术栈,使用JSP页面和MySQL数据库,支持IDEA/Eclipse开发环境。附项目演示视频和运行截图,需要者可联系文章下方名片获取完整资源。(99字)
本文提供完整Java项目资源,包含前后端源码、SQL脚本及配套文档(论文+PPT+开题报告)。技术栈采用Java+SSM/SpringBoot+Vue/JSP,数据库为MySQL,支持IDEA/Eclipse开发环境。项目提供演示视频、远程调试服务及运行包,需要者可联系文末名片获取全部资料。
该项目提供基于Java的完整前后端源代码及配套文档,包含SSM、SpringBoot、Vue等技术栈,支持MySQL数据库和IDEA/Eclipse开发环境。资料包括SQL脚本、论文、PPT、开题报告等,提供远程调试和运行支持。需要者可联系文末联系方式获取全套资源。
摘要:该项目提供完整的Java Web开发资源包,包含基于SSM/SpringBoot+Vue框架的源代码、SQL脚本及配套文档(论文+PPT+开题报告)。技术栈涵盖Java、MySQL、JSP及IDEA/Eclipse开发环境,支持远程调试。需要者可联系文末联系方式获取演示视频、项目截图及全套资料。(99字)
本文提供完整的Java项目资源包,包含前后端源代码、SQL脚本及配套文档(论文+PPT+开题报告)。项目采用SSM+SpringBoot+Vue技术栈,使用MySQL数据库,支持IDEA/Eclipse开发。附带项目演示视频、运行截图及远程调试服务。需要领取资料的同学可联系文末联系方式获取全部资源。
【项目资料领取】提供基于Java的完整源代码(含前后端+SQL脚本)、配套文档(论文/PPT/开题报告)及远程调试服务。技术栈涵盖SSM、SpringBoot、Vue、JSP及MySQL,支持IDEA/Eclipse开发环境。需要资料的同学请联系文章底部联系方式获取演示视频、项目截图及全套资源包。(49字)
该项目提供完整的Java Web开发学习资源,包含前后端源代码、SQL脚本及配套文档(论文+PPT+开题报告)。采用主流技术栈:Java+SSM+SpringBoot+Vue+JSP+MySQL,支持IDEA/Eclipse开发环境。提供项目演示视频、运行截图及远程调试服务,适合Java学习者参考实践。需要完整资料的同学可联系文末联系方式获取。
本项目提供Java语言开发的完整源代码(前后端+SQL脚本)及相关文档(论文+PPT+开题报告),采用SSM+SpringBoot+Vue框架,数据库使用MySQL。包含项目演示视频、运行截图和远程调试支持,适用IDEA/Eclipse开发环境。需要资料的同学可联系文末名片获取源代码和配套文档。 (摘要98字,准确概括了项目内容、技术栈和获取方式)
本文介绍了一个基于Java的Web开发项目,包含完整前后端源码和SQL脚本。项目采用SSM+SpringBoot+Vue技术栈,使用MySQL数据库,支持JSP页面,提供远程调试服务。配套资源包括论文、PPT、开题报告等文档资料。需要获取完整资料的同学可通过文末联系方式领取。项目演示视频和运行截图可供参考。(98字)
本文提供完整的Java项目资料包,包含前后端源代码、SQL脚本、论文、PPT及开题报告等配套文档。项目采用SSM+SpringBoot+Vue技术栈开发,使用MySQL数据库,支持IDEA/Eclipse开发环境。资料包包含演示视频、项目截图及远程调试服务,适合学生学习参考。有需要者可联系文章底部获取完整资源。
本文提供完整Java项目资源包,包含前后端源代码、SQL脚本、配套文档(论文+PPT+开题报告)及远程调试服务。技术栈采用Java+SSM+SpringBoot+Vue/JSP,数据库为MySQL,支持IDEA/Eclipse开发环境。项目包含演示视频、运行截图及详细资料,有需要者可联系文章下方名片获取完整资源包。
作为测试工程师,掌握AI测试技能不仅是为了应对技术变革,更是提升个人竞争力的重要途径。建立系统化的AI测试知识体系掌握核心的模型评估和性能测试技能具备解决实际AI测试问题的能力为职业发展打开新的空间记住,AI测试的学习是一个持续的过程,需要不断实践和总结。从现在开始,选择适合自己的学习路径,一步步成长为AI测试专家!关键成功因素扎实的编程和数学基础深入的业务理解能力系统的学习方法论持续的实践和总结
摘要:该项目提供完整的Java前后端开发资源,包含SSM+SpringBoot+Vue框架实现的源代码、SQL脚本及配套文档(论文+PPT+开题报告)。采用MySQL数据库,支持IDEA/Eclipse开发环境,附赠远程调试服务。资料领取方式见文末联系方式。
针对这些挑战,本文创新性地提出了"领域增强-架构重构-生态共建"三位一体的发展路径,为构建新一代"语言驱动的智慧交通系统"提供了理论框架与实践指南。与早期自然语言处理技术相比,大语言模型在交通领域的应用呈现出三个显著特征:从"单点工具"到"认知中枢"的角色转变,从"被动响应"到"主动交互"的能力提升,以及从"数据处理"到"知识创造"的价值跃迁。未来,随着技术的不断成熟,大语言模型有望成为交通系统的
后台管理员登录后可以分角色添加管理员,不同角色有不同权限,可以管理用户信息、商品信息、订单信息,订单信息可以导出到excel。系统主要实现的功能有:用户浏览商品、加入商品到购物车、登录注册、提交订单,会员中心修改个人信息、查看订单等。基于javaweb和mysql的ssm零食商城系统(java+ssm+jsp+mysql+easyui)基于javaweb的SSM零食商城系统(java+ssm+js
默认情况下,智能指针使用`delete`来释放资源。但如果资源不是通过`new`分配的(例如,使用`malloc`、文件句柄、套接字等),可以提供一个自定义删除器(一个可调用对象),指定如何释放资源。// 用于 FILE 的自定义删除器auto file_deleter = [](FILE fp) { if (fp) fclose(fp);智能指针是现代C++中不可或缺的工具,它将内存管理的责任从
2025年AI工具全景概览:涵盖通用大模型(如Gemini 1.5Pro、Claude3)、图像/视频生成(Midjourney、Veo3)、编程辅助(GitHub Copilot)、办公效率(Kimi)等八大领域,呈现多模态、集成化趋势。技术向工具(ComfyUI、Ollama)支持本地部署和定制化工作流。选择建议:根据需求场景(如艺术创作选Stable Diffusion,企业办公用LangC
easyui
——easyui
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 AI编程社区
AI编程社区







 AMD开发者中国社区
AMD开发者中国社区

 AI Agent技术社区
AI Agent技术社区