
强化学习与深度学习的融合自适应AI代理系统的构建与应用
在人工智能(AI)领域,智能代理系统逐渐成为解决复杂问题的关键技术。自适应AI代理系统能够根据环境变化自主调整行为,从而在动态环境中保持高效的决策能力。强化学习(RL)和深度学习(DL)是实现这一目标的核心技术。强化学习可以使AI代理通过与环境交互获得奖励,而深度学习则能帮助AI处理高维复杂的输入数据。在本文中,我们将探讨强化学习和深度学习的融合,如何构建一个自适应AI代理系统,并通过代码示例展示
强化学习与深度学习的融合自适应AI代理系统的构建与应用
引言
在人工智能(AI)领域,智能代理系统逐渐成为解决复杂问题的关键技术。自适应AI代理系统能够根据环境变化自主调整行为,从而在动态环境中保持高效的决策能力。强化学习(RL)和深度学习(DL)是实现这一目标的核心技术。强化学习可以使AI代理通过与环境交互获得奖励,而深度学习则能帮助AI处理高维复杂的输入数据。在本文中,我们将探讨强化学习和深度学习的融合,如何构建一个自适应AI代理系统,并通过代码示例展示其实现。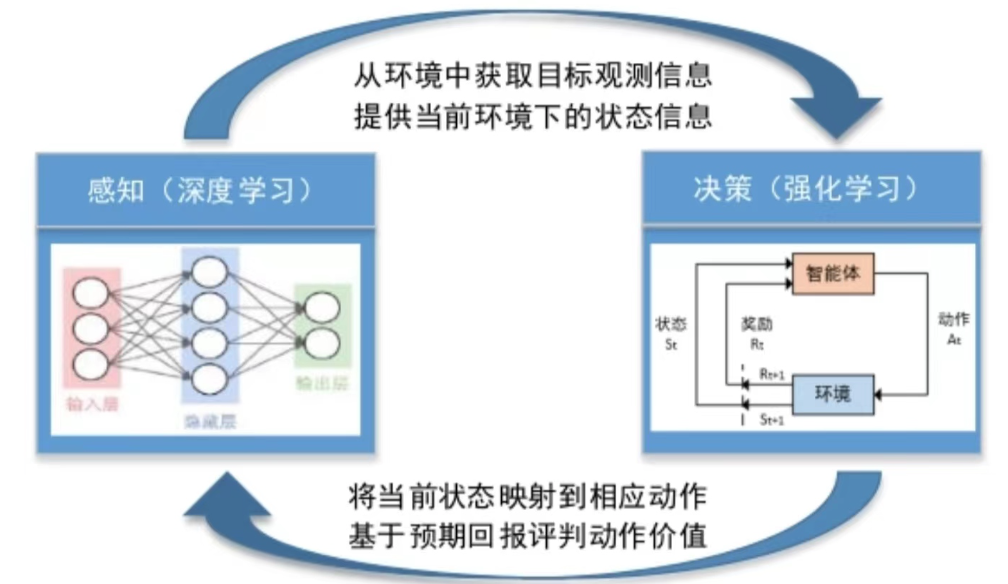
自适应AI代理系统概述
自适应AI代理系统通过在动态环境中持续学习和适应,实现任务的自动化完成。传统的AI代理系统依赖预定的规则和模型,而自适应系统则能在不断变化的环境中根据反馈调整行为。
强化学习与深度学习的基本概念
-
强化学习
强化学习是一种基于奖惩机制的学习方法,智能体通过与环境交互,执行动作以获得最大化的累积奖励。常见的强化学习算法包括Q-learning和深度Q网络(DQN)。 -
深度学习
深度学习通过多层神经网络从大量数据中提取特征并进行决策。深度学习通常用于处理图像、视频、语音等高维度数据,并能够从中学习复杂的模式。
强化学习与深度学习的融合
强化学习和深度学习的结合,通常通过深度Q网络(DQN)来实现。深度Q网络利用深度神经网络逼近Q值函数,从而克服了传统Q-learning算法无法处理高维状态空间的限制。结合深度学习,强化学习能够在更复杂的环境中发挥作用,例如视频游戏控制、机器人路径规划等。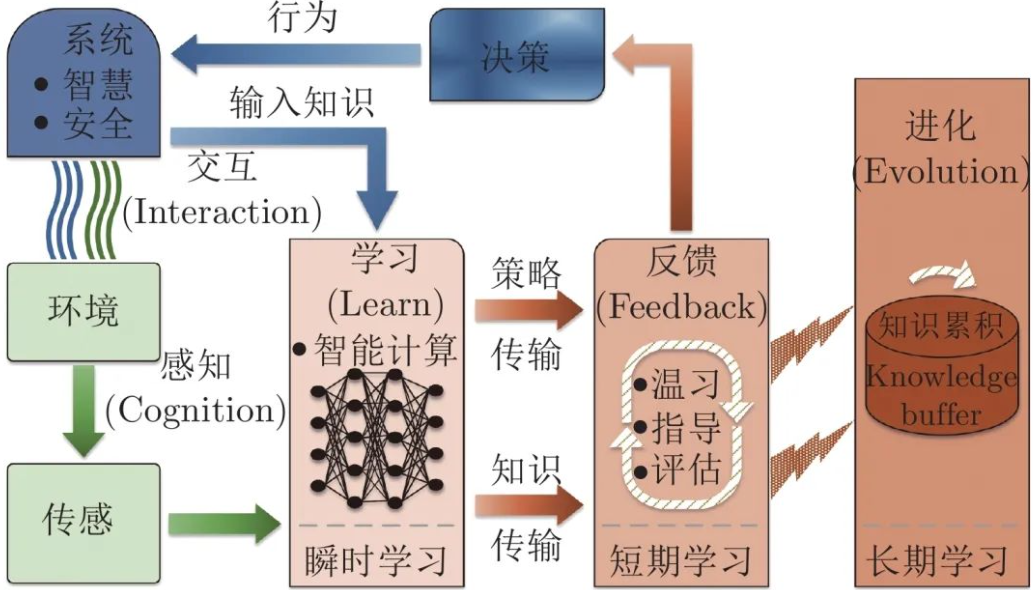
系统架构
自适应AI代理系统通常由以下几个核心模块构成:
-
环境模块
环境模块模拟AI代理的交互环境,为代理提供状态反馈。 -
代理模块
代理模块包含决策引擎,利用强化学习算法来选择行动。代理通过与环境交互获得奖励,并学习如何通过调整策略来获得最大回报。 -
学习模块
学习模块负责更新代理的策略,通常使用深度强化学习(DRL)算法进行训练。 -
评估模块
评估模块用于评估代理的表现,并基于评估结果调整学习过程。
强化学习与深度学习结合的代码实现
在此示例中,我们将使用深度Q网络(DQN)算法来展示强化学习和深度学习的结合。我们选择OpenAI Gym中的CartPole环境来进行实验,CartPole环境要求代理通过平衡杆来保持平衡。
安装所需库
首先,安装必要的Python库:
pip install gym torch numpy matplotlib
深度Q网络实现
下面的代码展示了如何实现一个简单的DQN代理来解决CartPole问题:
import gym
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import random
from collections import deque
import matplotlib.pyplot as plt
# 创建深度神经网络
class DQN(nn.Module):
def __init__(self, input_size, output_size):
super(DQN, self).__init__()
self.fc1 = nn.Linear(input_size, 128)
self.fc2 = nn.Linear(128, 128)
self.fc3 = nn.Linear(128, output_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return self.fc3(x)
# 强化学习代理
class DQNAgent:
def __init__(self, env):
self.env = env
self.action_space = env.action_space.n
self.state_space = env.observation_space.shape[0]
self.model = DQN(self.state_space, self.action_space)
self.target_model = DQN(self.state_space, self.action_space)
self.target_model.load_state_dict(self.model.state_dict())
self.optimizer = optim.Adam(self.model.parameters(), lr=0.001)
self.criterion = nn.MSELoss()
self.memory = deque(maxlen=10000)
self.batch_size = 64
self.gamma = 0.99 # 奖励折扣因子
self.epsilon = 1.0 # 探索率
self.epsilon_min = 0.01
self.epsilon_decay = 0.995
self.update_target_frequency = 10
def get_action(self, state):
if random.random() < self.epsilon:
return self.env.action_space.sample() # 随机选择动作
state = torch.FloatTensor(state).unsqueeze(0)
q_values = self.model(state)
return torch.argmax(q_values).item() # 选择Q值最高的动作
def store_experience(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def learn(self):
if len(self.memory) < self.batch_size:
return
batch = random.sample(self.memory, self.batch_size)
states, actions, rewards, next_states, dones = zip(*batch)
states = torch.FloatTensor(states)
actions = torch.LongTensor(actions)
rewards = torch.FloatTensor(rewards)
next_states = torch.FloatTensor(next_states)
dones = torch.BoolTensor(dones)
q_values = self.model(states)
next_q_values = self.target_model(next_states)
max_next_q_values = next_q_values.max(1)[0]
target_q_values = rewards + (self.gamma * max_next_q_values * ~dones)
loss = self.criterion(q_values.gather(1, actions.unsqueeze(1)), target_q_values.unsqueeze(1))
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# 更新epsilon值
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
def update_target_model(self):
self.target_model.load_state_dict(self.model.state_dict())
# 训练过程
def train_dqn():
env = gym.make('CartPole-v1')
agent = DQNAgent(env)
episodes = 1000
scores = []
for e in range(episodes):
state = env.reset()
done = False
total_reward = 0
while not done:
action = agent.get_action(state)
next_state, reward, done, _, _ = env.step(action)
agent.store_experience(state, action, reward, next_state, done)
agent.learn()
state = next_state
total_reward += reward
scores.append(total_reward)
if e % agent.update_target_frequency == 0:
agent.update_target_model()
if e % 100 == 0:
print(f"Episode {e}/{episodes}, Score: {total_reward}, Epsilon: {agent.epsilon:.2f}")
plt.plot(scores)
plt.title('DQN Training Progress')
plt.xlabel('Episodes')
plt.ylabel('Scores')
plt.show()
# 运行训练
train_dqn()
代码解析
-
DQN网络模型
DQN类定义了一个简单的三层神经网络,用于估计每个动作的Q值。 -
DQN代理
DQNAgent类包含了强化学习代理的核心部分,包括策略选择、经验回放、学习更新以及目标模型更新。 -
训练过程
在train_dqn函数中,我们初始化了一个CartPole环境并使用代理进行训练。每经过100个回合,输出当前的训练得分和epsilon值。
总结
自适应AI代理系统通过强化学习和深度学习的结合,在复杂的动态环境中表现出色。通过实现深度Q网络(DQN),代理能够有效学习如何在环境中进行决策。未来的研究可以将更多深度强化学习算法结合进来,提升代理在复杂任务中的表现。
更多推荐

 19
19 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)